 @fanf@mendeddrum.org
@fanf@mendeddrum.org2026-06-01 08:42:03
from my link log —
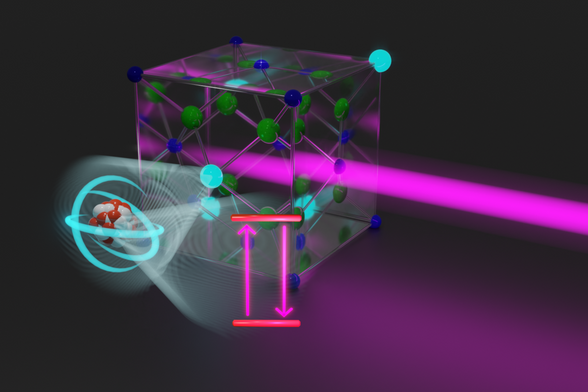
Thorium nucleus excited with laser: a breakthrough after decades.
https://www.tuwien.at/en/tu-wien/news/news-articles/news/lange-erhoffter-durchbruch-erstmals-atomkern-mit-laser-angeregt
 @vosje62@mastodon.nl
@vosje62@mastodon.nl2026-05-02 15:36:26
RE: #Israel #Palestine #US
 @peter_mcmahan@mas.to
@peter_mcmahan@mas.to2026-07-01 23:17:58
Heavens help me, I'm asking for linux distribution advice on fedi. 🫣
It's becoming increasingly clear that I'll need to jump ship from Ubuntu very soon. I've been using linux as my only os for several years now, and I originally chose Ubuntu because I wanted web searches for "<error message> <distro name>" to generally just give me an answer. But every release has made things harder (like avoiding snap) and canonical seems dead set on driving their…
 @azonenberg@ioc.exchange
@azonenberg@ioc.exchange2026-06-02 01:12:55
Christmas presents come from Santa Claus. Easter baskets from the Easter Bunny. But where do birthday presents come from?
When I was little my brothers and I concluded that the answer was... The Birthday Moose.
One of the non-birthday brothers would be designated the Moose. The outfit of the day was a brown paper grocery bag with a pair of eyes drawn on it in black marker, a lunch bag taped on the front as a snout, and sometimes a pair of cardboard ears up top.
Notably, tra…
 @Tuxramus@social.linux.pizza
@Tuxramus@social.linux.pizza2026-06-02 07:51:44
Weigh anchor and hoist the sails! ⚓️ Setting sail on the high seas today for some pirate gaming action on the Linux rig.
The Bazzite station is shipshape, the crew is ready, and there’s plunder to be found. Grab your grog and join the crew! 🐧🦜
🗺️ LIVE NOW: https://www.twitch.tv/tuxramus
@fanf@mendeddrum.org2026-05-31 17:42:02
from my link log —
42 is an answer to the question, what is the sum of three cubes?
https://aperiodical.com/2019/09/42-is-the-answer-to-the-question-what-is-80538738812075974³-8043575…

 @StephenRees@mas.to
@StephenRees@mas.to2026-08-01 18:41:34
From Bill McKibben
"every politician worth her salt should at every opportunity at least mention the anti-renewables jihad that the Trump administration has launched—the number of Americans who support shutting down 90% finished windfarms is tiny, and the rest of us are truly annoyed.
"And in many ways this generation of politicians is the luckiest yet, because they have a tool to call on that make those pledges relatively easy to fulfill. With ever-cheaper power from t…

 @Laur12@social.linux.pizza
@Laur12@social.linux.pizza2026-05-02 06:39:37
Sorry for any mistakes in english.
Recently saw on youtube how discussion about piracy on twitter is getting more and more popular, mainly betwen those countries where the content is made and those where the content isn't delivered, example: Japan and anime/manga.
I haven't seen most of the posts since i dont have an account on twitter, but what i did see was how users we're angry at others because they watch pirated/translated.
This is kinda absurd in this cont…
 @Mediagazer@mstdn.social
@Mediagazer@mstdn.social2026-05-26 18:40:41
A look at Blooloop, a B2B publisher that has 11 staffers and covers the tourist industry; Muck Rack: it's the UK's ninth most-cited outlet in AI answers (Dominic Ponsford/Press Gazette)
https://pressgazette.co.uk/publishers/b2b/b2b-ai-llms-blooloop-most-cit…

 @hippyjo@c.im
@hippyjo@c.im2026-06-29 17:07:01
Ukraine update from Giorgio Provincialli: Ukraine hits above its weight class and Russia stumbles like drunken old bear with mange.
Share the friend link to bypass the paywall, and poke Putin in the eye: https://
