 @mlncn@social.coop
@mlncn@social.coop2025-12-19 01:30:28
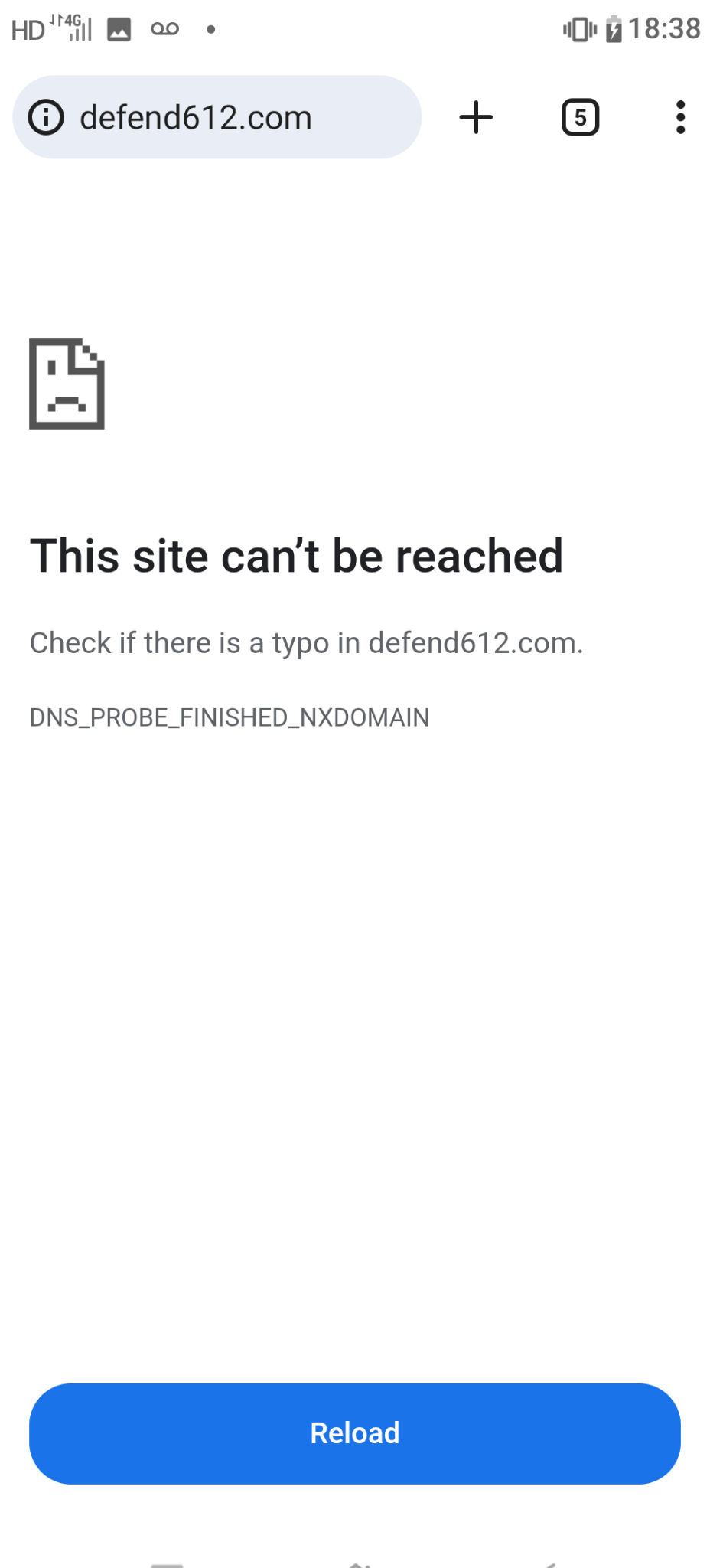
https://defend612.com has been blocked at the domain name level for me and at least two other people over T-Mobile networks (which includes GoogleFi, MetroPCS, and… wait for it… Trump Mobile). For at least all day today.
Seems unlikely to be a technical problem but instead to be Actual Censorship (unless its not …
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.page2025-09-29 11:19:47
B\'ezier Meets Diffusion: Robust Generation Across Domains for Medical Image Segmentation
Chen Li, Meilong Xu, Xiaoling Hu, Weimin Lyu, Chao Chen
https://arxiv.org/abs/2509.22476

 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.page2025-09-29 10:29:27
InfiMed-Foundation: Pioneering Advanced Multimodal Medical Models with Compute-Efficient Pre-Training and Multi-Stage Fine-Tuning
Guanghao Zhu, Zhitian Hou, Zeyu Liu, Zhijie Sang, Congkai Xie, Hongxia Yang
https://arxiv.org/abs/2509.22261

 @arXiv_csCR_bot@mastoxiv.page
@arXiv_csCR_bot@mastoxiv.page2025-10-09 09:28:51
Code Agent can be an End-to-end System Hacker: Benchmarking Real-world Threats of Computer-use Agent
Weidi Luo, Qiming Zhang, Tianyu Lu, Xiaogeng Liu, Bin Hu, Hung-Chun Chiu, Siyuan Ma, Yizhe Zhang, Xusheng Xiao, Yinzhi Cao, Zhen Xiang, Chaowei Xiao
https://arxiv.org/abs/2510.06607

 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.page2025-10-06 10:12:49
Self-Improvement in Multimodal Large Language Models: A Survey
Shijian Deng, Kai Wang, Tianyu Yang, Harsh Singh, Yapeng Tian
https://arxiv.org/abs/2510.02665 https://

 @buercher@tooting.ch
@buercher@tooting.ch2025-10-18 09:00:36
Vaud subventionne l’église protestante avec 64 millions par a pour ses services Š tous. Vu que l’église diminue ses services avec la suppression de protestinfo, Vaud devrait ajuster sa subvention.
@arXiv_csCV_bot@mastoxiv.page2025-10-06 10:17:39
LEAML: Label-Efficient Adaptation to Out-of-Distribution Visual Tasks for Multimodal Large Language Models
Ci-Siang Lin, Min-Hung Chen, Yu-Yang Sheng, Yu-Chiang Frank Wang
https://arxiv.org/abs/2510.03232
 @buercher@tooting.ch
@buercher@tooting.ch2025-11-29 16:48:59
“on a besoin d’un candidat qui dise au Conseil d’Etat qu’il fait fausse route. C’est un mensonge de répéter qu’on peut baisser les impôts tout en maintenant les prestations. Et Christelle Luisier se trompe en disant que le canton n’a pas de problème de recettes: on a besoin d’une réponse quant aux millions perdus du bouclier fiscal et on a besoin d’un système de solidarité financière”
https://www.letemps.ch/suisse/vaud/vaud-canton-recherche-ministre-bonne-resistance-au-stress-pour-ramener-le-calme?shouldPreventPurchase=true&inAppView=3.19.0&didomiConfig.user.externalConsent.value={"purposes":{"consent":{"enabled":["abtesting-p6FL2BYL","audiencem-hJxaeGrR","cookies","create_ads_profile","create_content_profile","device_characteristics","geolocation_data","improve_products","market_research","measure_ad_performance","measure_content_performance","parselyne-Ya2EC4dG","select_basic_ads","select_personalized_ads","select_personalized_content","use_limited_data_to_select_content"],"disabled":[]},"legitimate_interest":{"enabled":[],"disabled":[]}},"vendors":{"consent":{"enabled":["amazon","c:aws-cloudfront","c:bannerwise-EeHwBjLT","c:chartbeat","c:cloudflare","c:echobox-GqD96L9K","c:forecast-ZRJPAUT7","c:googleana-4TXnJigR","c:hotjar","c:jsdelivr-xdD77X6w","c:jw-player","c:kameleoon-experiment","c:kameleoon-personalization","c:keycdn","c:linkedin","c:magnitein-ePEpbCQ7","c:meta-43HDmFRa","c:microsoft","c:nonli-jnWf8kqD","c:pianohybr-R3VKC2r4","c:pinterest","c:spyri-XAtBPx3i","c:tapadinc-VDTUUcKw","c:tiktok-KZAUQLZ9","c:unrulygro-nKyLqdKi","c:youtube","facebook","google","twitter",1,10,1020,1021,1028,1046,1069,108,109,11,1126,12,120,1269,128,13,130,131,1310,132,136,137,138,142,143,1449,154,156,16,164,202,209,21,211,23,238,24,241,243,25,253,264,28,284,290,30,301,32,36,39,4,412,422,45,469,475,493,50,519,52,559,58,61,612,617,68,684,69,73,76,77,783,790,793,80,81,811,84,85,855,898,91,92,95,965,98],"disabled":[]},"legitimate_interest":{"enabled":[],"disabled":[]}},"user_id":"36B03261-8BC8-4FB4-A026-0543FF748710","created":"2025-05-28T08:36:56.058Z","updated":"2025-11-08T21:05:15.048Z","source":{"type":"app","domain":"ch.letemps.LT"},"action":"webview"}