 @cheryanne@aus.social
@cheryanne@aus.social2025-11-24 02:42:47
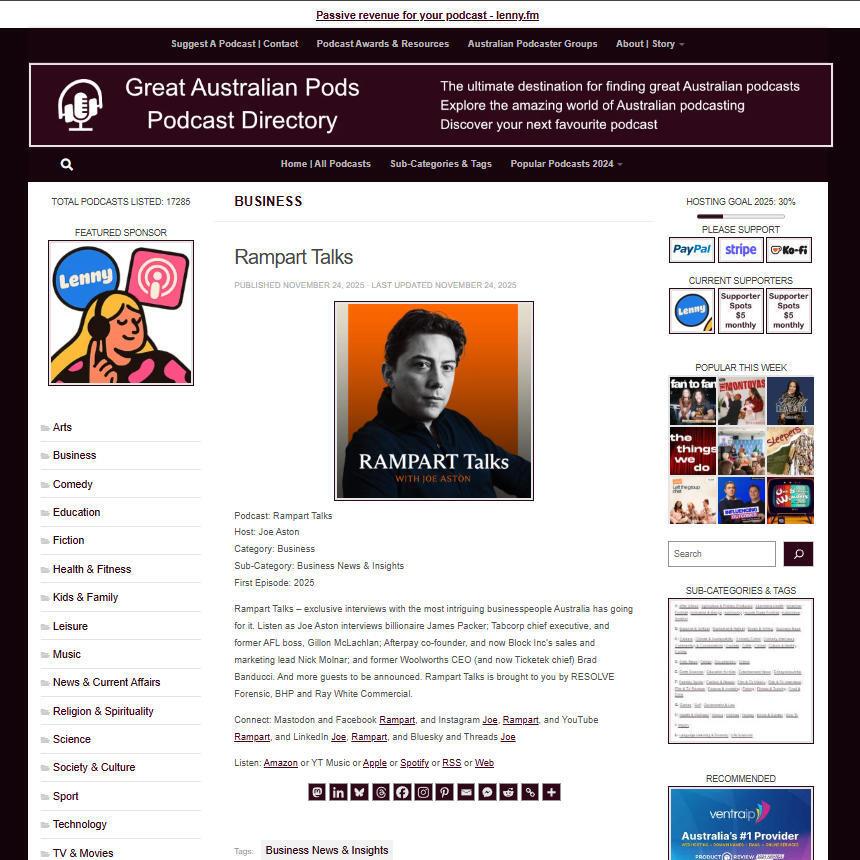
Rampart Talks
Exclusive interviews with the most intriguing businesspeople Australia has going for it...
Great Australian Pods Podcast Directory: https://www.greataustralianpods.com/rampart-talks/
 @heiseonline@social.heise.de
@heiseonline@social.heise.de2025-10-23 16:52:00
 @cdarwin@c.im
@cdarwin@c.im2025-11-22 17:13:40
Global climate negotiations ended on Saturday in Brazil
with a watered-down resolution that makes no mention of fossil fuels, the main driver of global warming.
The final statement included plenty of warnings on the cost of inaction
but few provisions for how the world might address dangerously rising global temperatures head-on.
A marathon series of frenetic Friday night meetings ultimately salvaged the talks in Belém, on the edge of the Amazon rainforest.
The …

 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.page2025-10-10 11:13:19
Video-STAR: Reinforcing Open-Vocabulary Action Recognition with Tools
Zhenlong Yuan, Xiangyan Qu, Chengxuan Qian, Rui Chen, Jing Tang, Lei Sun, Xiangxiang Chu, Dapeng Zhang, Yiwei Wang, Yujun Cai, Shuo Li
https://arxiv.org/abs/2510.08480

 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.page2025-10-03 07:38:10
ToolBrain: A Flexible Reinforcement Learning Framework for Agentic Tools
Quy Minh Le, Minh Sao Khue Luu, Khanh-Tung Tran, Duc-Hai Nguyen, Hoang-Quoc-Viet Pham, Quan Le, Hoang Thanh Lam, Hoang D. Nguyen
https://arxiv.org/abs/2510.00023

 @servelan@newsie.social
@servelan@newsie.social2025-11-07 20:45:54
"For Afghan women, the stakes could not be any clearer. Every gesture towards normalization tells them their rights can be traded away for political convenience. Every meeting that sidelines the issue of gender apartheid reinforces the message that their lives are secondary to geopolitical interests. "
UN Report Details Deepening Crisis for Afghan Women and Warns Against Normalising Taliban Rule - Feminist Majority Foundation
https://feminist.org/news/un-report-details-deepening-crisis-for-afghan-women-and-warns-against-normalising-taliban-rule/
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.page2025-10-09 10:27:11
Adaptive Tool Generation with Models as Tools and Reinforcement Learning
Chenpeng Wang, Xiaojie Cheng, Chunye Wang, Linfeng Yang, Lei Zhang
https://arxiv.org/abs/2510.06825 http…

 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.page2025-10-08 11:01:09
Stratified GRPO: Handling Structural Heterogeneity in Reinforcement Learning of LLM Search Agents
Mingkang Zhu, Xi Chen, Bei Yu, Hengshuang Zhao, Jiaya Jia
https://arxiv.org/abs/2510.06214
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.page2025-10-09 09:58:01
Tool-Augmented Policy Optimization: Synergizing Reasoning and Adaptive Tool Use with Reinforcement Learning
Wenxun Wu, Yuanyang Li, Guhan Chen, Linyue Wang, Hongyang Chen
https://arxiv.org/abs/2510.07038
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.page2025-10-14 13:41:38
Representation-Based Exploration for Language Models: From Test-Time to Post-Training
Jens Tuyls, Dylan J. Foster, Akshay Krishnamurthy, Jordan T. Ash
https://arxiv.org/abs/2510.11686
