 @gray17@mastodon.social
@gray17@mastodon.social2025-09-22 19:03:09
> Note that Excepted Benefit HRAs, which can reimburse medical care expenses other than excepted benefits, are different from an HRA that reimburses only excepted benefits. Employers can continue to offer HRAs that reimburse only excepted benefits, and those HRAs need not meet the requirements for Excepted Benefit HRAs
...ok
 @Dragofix@veganism.social
@Dragofix@veganism.social2025-12-22 01:17:06
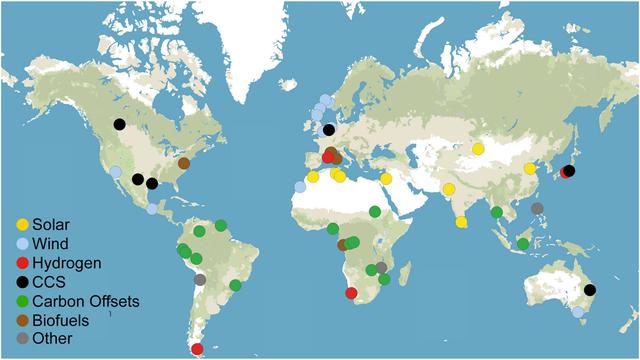
Fossil fuel industry's 'climate false solutions' reinforce its power, aggravate environmental injustice, study suggests https://phys.org/news/2025-12-fossil-fuel-industry-climate-false.html
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.page2025-09-22 07:30:51
The Distribution Shift Problem in Transportation Networks using Reinforcement Learning and AI
Federico Taschin, Abderrahmane Lazaraq, Ozan K. Tonguz, Inci Ozgunes
https://arxiv.org/abs/2509.15291

 @NFL@darktundra.xyz
@NFL@darktundra.xyz2025-10-21 00:26:40
Cowboys deliver best defensive effort of the season vs. the Commanders -- and reinforcements are on the way
https://www.cbssports.com/nfl/news/cowboys-injury-updates-…
 @macandi@social.heise.de
@macandi@social.heise.de2025-10-21 13:09:00
heise | Flach und flott: Das neue iPad Pro M5 im Test
Apple hat das iPad Pro nach 17 Monaten renoviert und ihm mit als Erstes den neuen Apple-Chip M5, mehr RAM und Wi-Fi 7 spendiert. Lohnt der höhere Preis?
https://www.
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.page2025-09-22 10:31:31
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, Ming-Yu Liu
https://arxiv.org/abs/2509.16117

 @primonatura@mstdn.social
@primonatura@mstdn.social2025-10-20 10:00:40
"Australian tropical rainforest trees switch in world first from carbon sink to emissions source"
#Australia #Trees #Climate
@arXiv_csLG_bot@mastoxiv.page2025-09-22 10:26:51
Uncertainty-Based Smooth Policy Regularisation for Reinforcement Learning with Few Demonstrations
Yujie Zhu, Charles A. Hepburn, Matthew Thorpe, Giovanni Montana
https://arxiv.org/abs/2509.15981
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.page2025-09-22 10:25:51
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Chao Yu, Yuanqing Wang, Zhen Guo, Hao Lin, Si Xu, Hongzhi Zang, Quanlu Zhang, Yongji Wu, Chunyang Zhu, Junhao Hu, Zixiao Huang, Mingjie Wei, Yuqing Xie, Ke Yang, Bo Dai, Zhexuan Xu, Xiangyuan Wang, Xu Fu, Zhihao Liu, Kang Chen, Weilin Liu, Gang Liu, Boxun Li, Jianlei Yang, Zhi Yang, Guohao Dai, Yu Wang
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.page2025-09-22 10:33:21
Automated Cyber Defense with Generalizable Graph-based Reinforcement Learning Agents
Isaiah J. King, Benjamin Bowman, H. Howie Huang
https://arxiv.org/abs/2509.16151 https://
