 @heiseonline@social.heise.de
@heiseonline@social.heise.de2025-09-30 05:46:00
 @lightweight@mastodon.nzoss.nz
@lightweight@mastodon.nzoss.nz2025-10-31 04:15:52
So: https://www.rnz.co.nz/news/national/577446/wellington-water-reservoir-pulled-offline-after-small-lizard-found what the hell? First, blame the lack of water on a lizard who's just living its life and then (I guess?) im…
@heiseonline@social.heise.de2025-10-30 12:06:00
@heiseonline@social.heise.de2025-09-30 03:53:00
Abhör-App Neon verriet alles: Offline
"Neon - Money Talks" wurde schlagartig populär, weil es Geld für aufgezeichnete Telefonate versprach. Doch die landeten frei im Netz.
https://www.heise.de/…
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2025-10-31 20:00:04
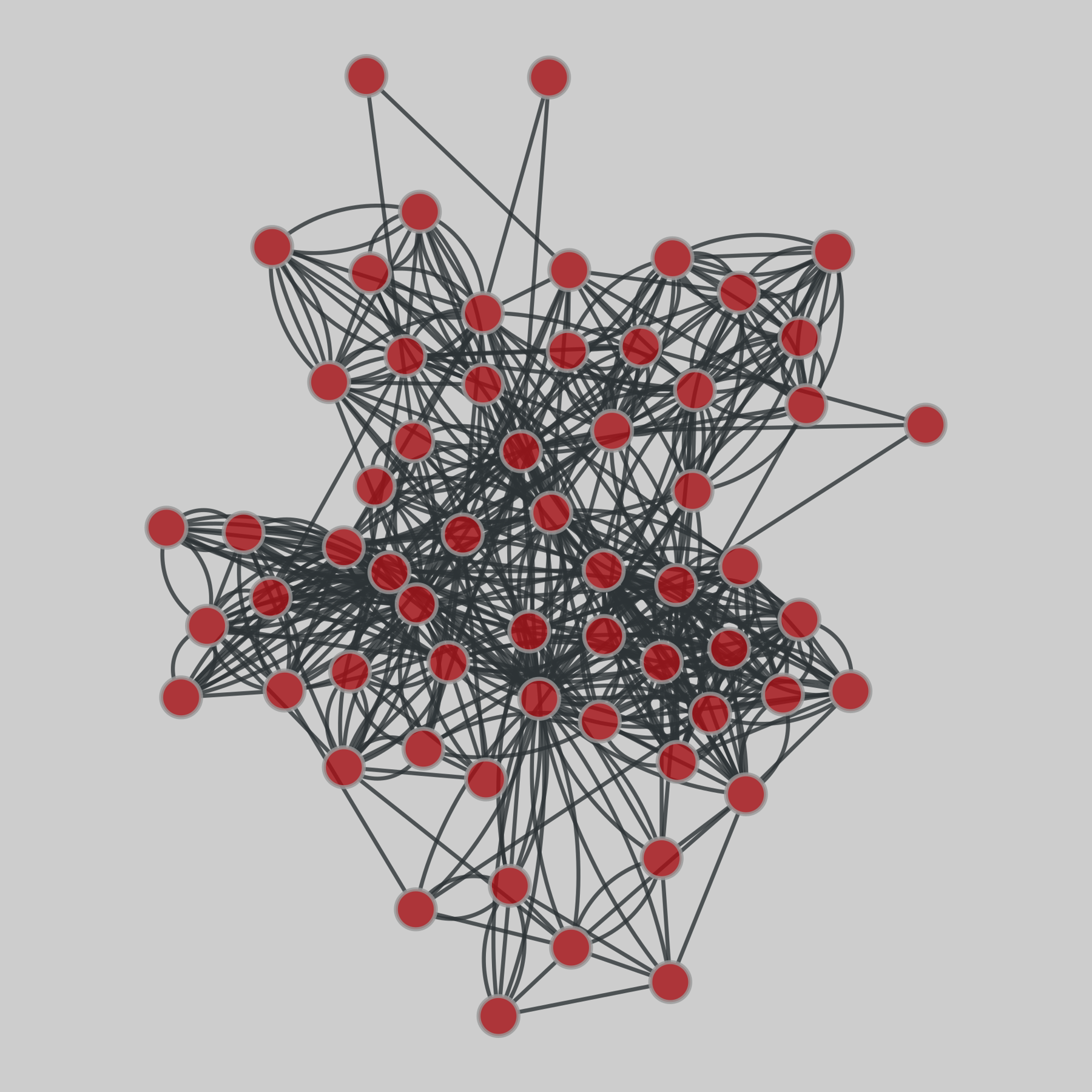
cs_department: Aarhus Computer Science department relationships
Multiplex network consisting of 5 edge types corresponding to online and offline relationships (Facebook, leisure, work, co-authorship, lunch) between employees of the Computer Science department at Aarhus. Data hosted by Manlio De Domenico.
This network has 61 nodes and 620 edges.
Tags: Social, Relationships, Multilayer, Unweighted
 @arXiv_csCR_bot@mastoxiv.page
@arXiv_csCR_bot@mastoxiv.page2025-10-01 08:29:27
Balancing Compliance and Privacy in Offline CBDC Transactions Using a Secure Element-based System
Panagiotis Michalopoulos, Anthony Mack, Cameron Clark, Linus Chen, Johannes Sedlmeir, Andreas Veneris
https://arxiv.org/abs/2509.25469

 @arXiv_quantph_bot@mastoxiv.page
@arXiv_quantph_bot@mastoxiv.page2025-09-01 09:44:42
Computationally Tractable Offline Quantum Experimental Design for Nuclear Spin Detection
B. Varona-Uriarte, F. Belliardo, T. H. Taminiau, C. Bonato, E. Garrote, J. Casanova
https://arxiv.org/abs/2508.21450

 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.page2025-09-29 10:14:57
DyRo-MCTS: A Robust Monte Carlo Tree Search Approach to Dynamic Job Shop Scheduling
Ruiqi Chen, Yi Mei, Fangfang Zhang, Mengjie Zhang
https://arxiv.org/abs/2509.21902 https://…

 @adulau@infosec.exchange
@adulau@infosec.exchange2025-10-21 11:59:05
An interesting lighting talk at #hacklu presenting a tool for Offline decryption of SCCM database secrets.
https://github.com/MartinoTommasini/offlineSCCMdecrypt

 @3sframe@social.linux.pizza
@3sframe@social.linux.pizza2025-09-30 13:22:47
Been doing a deep dive on hosting offline LLMs with ollama. I think it's funny that all the tutorials I find are like "This is linux only but if you're using Windows, don't worry, there's WSL."
Saw a comment on one of those video tutorials that said "How do you get this running with Windows Server 2022."
Idk, you could just use linux? 🤷♂️