 @jdrm@social.linux.pizza
@jdrm@social.linux.pizza2026-01-19 11:28:25
Hay gente que se carga sobre sus espaldas demasiadas cosas y luego se queja amargamente de que no puede abarcarlo todo. Pues chico, qué quieres que te diga, no haber abarcado mšs de lo que puedes apretar. Que no se puede estar en todo
 @EgorKotov@datasci.social
@EgorKotov@datasci.social2026-02-12 08:55:08
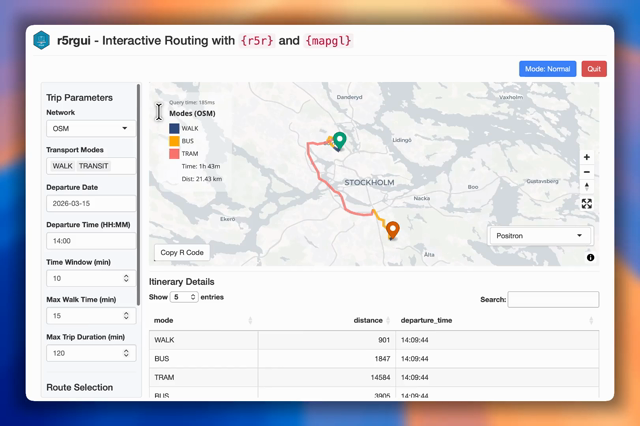
#r5rgui v0.2 for interactively exploring and debugging your r5/r5r networks is here with great new features:
- Compare two routes using different modes of transport
- Compare two (or more!) networks! In this example I am comparing OpenStreetMap network vs official Swedish street network data from Trafikverket.se
- See the speed of processing routing queries
- Use custom basemap…
 @michabbb@social.vivaldi.net
@michabbb@social.vivaldi.net2026-02-08 15:43:24
 @arXiv_csDS_bot@mastoxiv.page
@arXiv_csDS_bot@mastoxiv.page2026-02-04 07:39:24
ZOR filters: fast and smaller than fuse filters
Antoine Limasset
https://arxiv.org/abs/2602.03525 https://arxiv.org/pdf/2602.03525 https://arxiv.org/html/2602.03525
arXiv:2602.03525v1 Announce Type: new
Abstract: Probabilistic membership filters support fast approximate membership queries with a controlled false-positive probability $\varepsilon$ and are widely used across storage, analytics, networking, and bioinformatics \cite{chang2008bigtable,dayan2018optimalbloom,broder2004network,harris2020improved,marchet2023scalable,chikhi2025logan,hernandez2025reindeer2}. In the static setting, state-of-the-art designs such as XOR and fuse filters achieve low overhead and very fast queries, but their peeling-based construction succeeds only with high probability, which complicates deterministic builds \cite{graf2020xor,graf2022binary,ulrich2023taxor}.
We introduce \emph{ZOR filters}, a deterministic continuation of XOR/fuse filters that guarantees construction termination while preserving the same XOR-based query mechanism. ZOR replaces restart-on-failure with deterministic peeling that abandons a small fraction of keys, and restores false-positive-only semantics by storing the remainder in a compact auxiliary structure. In our experiments, the abandoned fraction drops below $1\%$ for moderate arity (e.g., $N\ge 5$), so the auxiliary handles a negligible fraction of keys. As a result, ZOR filters can achieve overhead within $1\%$ of the information-theoretic lower bound $\log_2(1/\varepsilon)$ while retaining fuse-like query performance; the additional cost is concentrated on negative queries due to the auxiliary check. Our current prototype builds several-fold slower than highly optimized fuse builders because it maintains explicit incidence information during deterministic peeling; closing this optimisation gap is an engineering target.
toXiv_bot_toot