 @dr2chase@ohai.social
@dr2chase@ohai.social2026-06-28 23:06:25
FYI, anyone complaining about Ikea assembly, has never installed a Ring doorbell.
No indication of what tools will be needed.
Not even a size specification for the drill that you might need.
Yes we need a spycam because reasons, we'll do our best to disable its image sharing with third parties. The advertising is also fucking appalling, be very frightened, burglars and evildoers want to enter your home. One ad was actually overtly racist "wrong neighborhood".…
 @malik@Mastodon.Social
@malik@Mastodon.Social2026-05-26 13:51:12
Nein. Doch. Oh!
https://ard.social/@NDR/116641050818177830

 @matematico314@social.linux.pizza
@matematico314@social.linux.pizza2026-06-27 02:02:21
 @arXiv_physicsfludyn_bot@mastoxiv.page
@arXiv_physicsfludyn_bot@mastoxiv.page2026-05-19 10:06:18
Replaced article(s) found for physics.flu-dyn. https://arxiv.org/list/physics.flu-dyn/new
[1/1]:
- On the stability of an in-line formation of hydrodynamically interacting flapping plates
Monika Nitsche, Anand U. Oza, Michael Siegel
https://arxiv.org/abs/2410.04626 https://mastoxiv.page/@arXiv_physicsfludyn_bot/113270998236203403
- Side-wall wetting and linear stability of falling films
Hammam Mohamed, J\"orn Sesterhenn
https://arxiv.org/abs/2504.13300 https://mastoxiv.page/@arXiv_physicsfludyn_bot/114374794050144417
- An Omni-Temporal Theory for Hydrodynamic Dispersion and Reaction in Porous Media
Md Abdul Hamid, Kyle C. Smith
https://arxiv.org/abs/2505.06063 https://mastoxiv.page/@arXiv_physicsfludyn_bot/114493702701690116
- Confirming Wave Turbulence Predictions in Rotating Turbulence
Omri Shaltiel, Omri Gat, Eran Sharon
https://arxiv.org/abs/2510.25446 https://mastoxiv.page/@arXiv_physicsfludyn_bot/115462467154250733
- Using Physics Informed Neural Network (PINN) and Neural Network (NN) to Improve a $k-\omega$ Turb...
Lars Davidson
https://arxiv.org/abs/2511.12493 https://mastoxiv.page/@arXiv_physicsfludyn_bot/115570134553603649
- Oscillating Detonation of Liquid Ammonia
Wenhao Wang, Zongmin Hu, Peng Zhang
https://arxiv.org/abs/2511.14167 https://mastoxiv.page/@arXiv_physicsfludyn_bot/115575358542454196
- On the Poisson-Source Basis of Logarithmic Wall-Pressure-Variance Growth
Jonathan M. O. Massey, Joseph C. Klewicki, Beverley J. McKeon
https://arxiv.org/abs/2511.16776 https://mastoxiv.page/@arXiv_physicsfludyn_bot/115603689363840109
- Convolutional causal learning for aerodynamic flows
Ryo Koshikawa, Ryo Araki, Qiong Liu, Kai Fukami
https://arxiv.org/abs/2601.19104 https://mastoxiv.page/@arXiv_physicsfludyn_bot/115971839485449464
- Assessing engineering wake models against operational data: insights from the Lillgrund wind farm...
Siguenza-Alvarado, Harrison, Mohammadi, Vishwakarma, Bossanyi, Landberg, Bastankhah
https://arxiv.org/abs/2601.21035 https://mastoxiv.page/@arXiv_physicsfludyn_bot/115983015393462612
- Neural equilibria for long-term prediction of nonlinear conservation laws
Benitez, Hegazy, Guo, Dokmani\'c, Mahoney, de Hoop
https://arxiv.org/abs/2501.06933 https://mastoxiv.page/@arXiv_csLG_bot/113825452743912532
- Self-similar rupture of thin films of power-law fluid
Michael C Dallaston, Steven A Kedda, Scott W McCue
https://arxiv.org/abs/2509.05383 https://mastoxiv.page/@arXiv_condmatsoft_bot/115173629129170202
- Instability and self-propulsion of flexible autophoretic filaments
Ursy Makanga, Akhil Varma, Panayiota Katsamba
https://arxiv.org/abs/2509.10153 https://mastoxiv.page/@arXiv_condmatsoft_bot/115207443699020835
- Analytical response functions for a compressible thin fluid layer with odd viscosity
Abdallah Daddi-Moussa-Ider, Yuto Hosaka, Shigeyuki Komura
https://arxiv.org/abs/2602.18136 https://mastoxiv.page/@arXiv_condmatsoft_bot/116119064615788127
toXiv_bot_toot
 @LaChasseuse@mastodon.scot
@LaChasseuse@mastodon.scot2026-07-09 12:01:11
Interesting to compare the author Neal Stephenson's profiles on X/twitter vs. Bluesky.
He has 89,4 K followers on X, where he still posts, but just under 10 K on Bluesky, where he doesn't post at all.
He has many fans on the fediverse who discuss his books, but he is not here.


 @Mediagazer@mstdn.social
@Mediagazer@mstdn.social2026-05-11 16:25:31
Amazon unveils Dynamic TV Creative, which lets Prime Video advertisers automatically tailor their ads based on the viewer's previous exposure to the brand (Kathryn Lundstrom/Adweek)
https://www.adweek.com/commerce/prime-video-ads-can-now-…
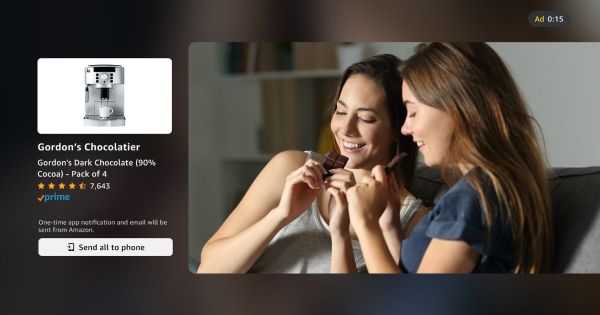
 @castarco@hachyderm.io
@castarco@hachyderm.io2026-06-08 12:37:18
 @inthehands@hachyderm.io
@inthehands@hachyderm.io2026-05-30 16:12:38
RE: https://dair-community.social/@timnitGebru/116664117796381623
Please note that this delightful bit of schadenfreude is couched in an article that’s actually AI advertising in disguise:
“This happened because Claude is so good at ‘reasoning across large codebases!’ It’s a sign of a coming boom! It’s not because employees are being pressured to maximize token use or because ‘agents’ go completely off the rails, oh no, couldn’t be •that•!”
 @carloshr@lile.cl
@carloshr@lile.cl2026-07-05 17:40:48
El extraño caso del oficialismo que se autopercibe oposición | Columna de Daniel Matamala
https://wallabag.altgr.xyz/share/6a4a96f182edc0.54435682
Original 🔗
 @grumpybozo@toad.social
@grumpybozo@toad.social2026-06-07 20:28:42
RE: https://toad.social/@grumpybozo/116710609481964719
Oh and BTW: if you watch the wrong sort of TV you’ve seen ads for “Alien Tape” that have a Ronco feel. It is indeed *as advertised*: an amazing adhesive-free crystal clear double-sided tape about a mill…