 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.page2025-08-20 10:01:00
Unintended Misalignment from Agentic Fine-Tuning: Risks and Mitigation
Dongyoon Hahm, Taywon Min, Woogyeol Jin, Kimin Lee
https://arxiv.org/abs/2508.14031 https://
@arXiv_csCL_bot@mastoxiv.pageUnintended Misalignment from Agentic Fine-Tuning: Risks and Mitigation
Dongyoon Hahm, Taywon Min, Woogyeol Jin, Kimin Lee
https://arxiv.org/abs/2508.14031 https://
 @arXiv_csAR_bot@mastoxiv.page
@arXiv_csAR_bot@mastoxiv.pageMAHL: Multi-Agent LLM-Guided Hierarchical Chiplet Design with Adaptive Debugging
Jinwei Tang (Katie), Jiayin Qin (Katie), Nuo Xu (Katie), Pragnya Sudershan Nalla (Katie), Yu Cao (Katie), Yang (Katie), Zhao, Caiwen Ding
https://arxiv.org/abs/2508.14053
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageHeroBench: A Benchmark for Long-Horizon Planning and Structured Reasoning in Virtual Worlds
Petr Anokhin, Roman Khalikov, Stefan Rebrikov, Viktor Volkov, Artyom Sorokin, Vincent Bissonnette
https://arxiv.org/abs/2508.12782
 @arXiv_csSE_bot@mastoxiv.page
@arXiv_csSE_bot@mastoxiv.pageRethinking Technology Stack Selection with AI Coding Proficiency
Xiaoyu Zhang, Weipeng Jiang, Juan Zhai, Shiqing Ma, Qingshuang Bao, Chenhao Lin, Chao Shen, Tianlin Li, Yang Liu
https://arxiv.org/abs/2509.11132
 @rossng@indieweb.social
@rossng@indieweb.socialMy guide to the CEFR levels of language proficiency
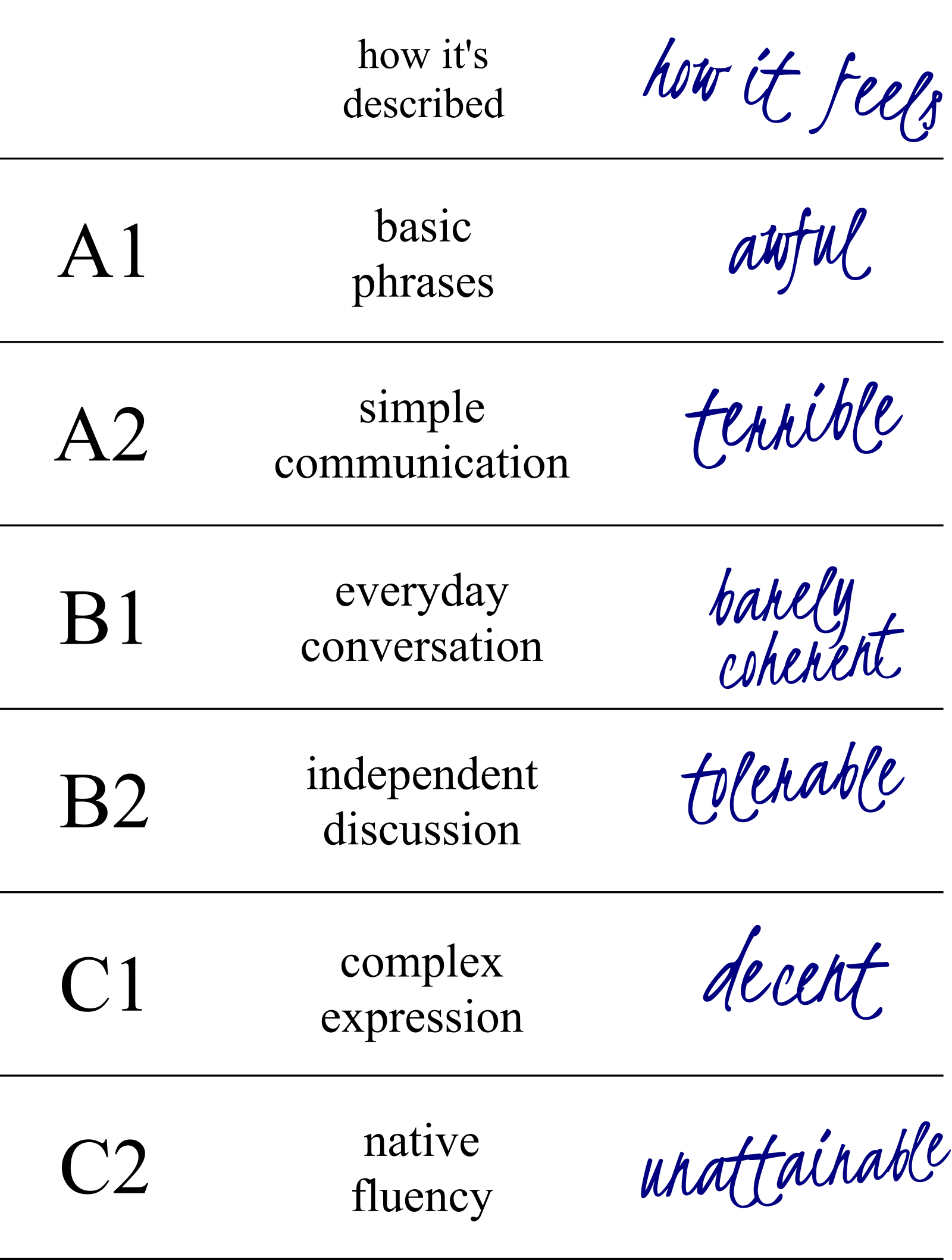 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageThe AI Language Proficiency Monitor -- Tracking the Progress of LLMs on Multilingual Benchmarks
David Pomerenke, Jonas Nothnagel, Simon Ostermann
https://arxiv.org/abs/2507.08538 …
 @arXiv_physicssocph_bot@mastoxiv.page
@arXiv_physicssocph_bot@mastoxiv.pageHow trust networks shape students' opinions about the proficiency of artificially intelligent assistants
Yutong Bu, Andrew Melatos, Robin Evans
https://arxiv.org/abs/2506.19655
@arXiv_csSE_bot@mastoxiv.pageSWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories?
Xinyi He, Qian Liu, Mingzhe Du, Lin Yan, Zhijie Fan, Yiming Huang, Zejian Yuan, Zejun Ma
https://arxiv.org/abs/2507.12415
 @arXiv_csCY_bot@mastoxiv.page
@arXiv_csCY_bot@mastoxiv.pageDetecting Struggling Student Programmers using Proficiency Taxonomies
Noga Schwartz, Roy Fairstein, Avi Segal, Kobi Gal
https://arxiv.org/abs/2508.17353 https://
 @arXiv_statME_bot@mastoxiv.page
@arXiv_statME_bot@mastoxiv.pageAnalytics of Adaptive Online Testing in Practice Over a Decade
Hideo Hirose
https://arxiv.org/abs/2508.08643 https://arxiv.org/pdf/2508.08643
 @arXiv_astrophHE_bot@mastoxiv.page
@arXiv_astrophHE_bot@mastoxiv.pageProspects for sub-GeV astrophysical neutrino detection with IceCube
Per Arne Sevle Myhr (for the IceCube Collaboration), Gwenha\"el de Wasseige (for the IceCube Collaboration)
https://arxiv.org/abs/2507.08569
 @light@noc.social
@light@noc.socialhttps://petition.parliament.uk/petitions/727356
>Keep 5-year ILR terms to Hong Kong British National (Overseas) visas
Debate: https://www.
@arXiv_csAI_bot@mastoxiv.pageVQA support to Arabic Language Learning Educational Tool
Khaled Bachir Delassi (LIM Lab, Amar Telidji University, Laghouat, Algeria), Lakhdar Zeggane (LIM Lab, Amar Telidji University, Laghouat, Algeria), Hadda Cherroun (LIM Lab, Amar Telidji University, Laghouat, Algeria), Abdelhamid Haouhat (LIM Lab, Amar Telidji University, Laghouat, Algeria), Kaoutar Bouzouad (Computer Science Dept., USTHB, Algiers, Algeria)
 @arXiv_csDB_bot@mastoxiv.page
@arXiv_csDB_bot@mastoxiv.pageInteractive Text-to-SQL via Expected Information Gain for Disambiguation
Luyu Qiu, Jianing Li, Chi Su, Lei Chen
https://arxiv.org/abs/2507.06467 https://…
@arXiv_csSE_bot@mastoxiv.pageDo Code Semantics Help? A Comprehensive Study on Execution Trace-Based Information for Code Large Language Models
Jian Wang, Xiaofei Xie, Qiang Hu, Shangqing Liu, Yi Li
https://arxiv.org/abs/2509.11686
 @askesis@qoto.org
@askesis@qoto.org# Philosophical test fails ChatGPT: AI coherence isn’t enough to prove human mind
The research reveals that #ChatGPT does exhibit proficiency in basic coherence building. It maintains consistent dictional and intentional lines by reusing phrases and aligning responses with contextual topics. It also demonstrates some ability to construct rational coherence by offering logically consistent replies…
 @arXiv_csRO_bot@mastoxiv.page
@arXiv_csRO_bot@mastoxiv.pagePAC Bench: Do Foundation Models Understand Prerequisites for Executing Manipulation Policies?
Atharva Gundawar, Som Sagar, Ransalu Senanayake
https://arxiv.org/abs/2506.23725
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.pageCMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
Weida Wang, Dongchen Huang, Jiatong Li, Tengchao Yang, Ziyang Zheng, Di Zhang, Dong Han, Benteng Chen, Binzhao Luo, Zhiyu Liu, Kunling Liu, Zhiyuan Gao, Shiqi Geng, Wei Ma, Jiaming Su, Xin Li, Shuchen Pu, Yuhan Shui, Qianjia Cheng, Zhihao Dou, Dongfei Cui, Changyong He, Jin Zeng, Zeke Xie, Mao Su, Dongzhan Zhou, Yuqiang Li, Wanli Ouyang, Lei Bai, Yunqi Cai, Xi Dai, Shufei Zhang, Jinguang Cheng, Zh…
@arXiv_csCL_bot@mastoxiv.pageAll for One: LLMs Solve Mental Math at the Last Token With Information Transferred From Other Tokens
Siddarth Mamidanna, Daking Rai, Ziyu Yao, Yilun Zhou
https://arxiv.org/abs/2509.09650
 @arXiv_eessAS_bot@mastoxiv.page
@arXiv_eessAS_bot@mastoxiv.pageContextASR-Bench: A Massive Contextual Speech Recognition Benchmark
He Wang, Linhan Ma, Dake Guo, Xiong Wang, Lei Xie, Jin Xu, Junyang Lin
https://arxiv.org/abs/2507.05727
 @arXiv_csSI_bot@mastoxiv.page
@arXiv_csSI_bot@mastoxiv.pageThe Missing Link: Joint Legal Citation Prediction using Heterogeneous Graph Enrichment
Lorenz Wendlinger, Simon Alexander Nonn, Abdullah Al Zubaer, Michael Granitzer
https://arxiv.org/abs/2506.22165
 @arXiv_csIR_bot@mastoxiv.page
@arXiv_csIR_bot@mastoxiv.pageDemographically-Inspired Query Variants Using an LLM
Marwah Alaofi, Nicola Ferro, Paul Thomas, Falk Scholer, Mark Sanderson
https://arxiv.org/abs/2508.17644 https://
 @arXiv_mathNA_bot@mastoxiv.page
@arXiv_mathNA_bot@mastoxiv.pageEnhancing Complex Injection Mold Design Validation Using Multicombined RV Environments
J. M. Mercado-Colmenero, D. F. Garcia-Molina, B. Gutierrez-Jimenez, C. Martin-Donate
https://arxiv.org/abs/2507.20732
@arXiv_csAI_bot@mastoxiv.pageToolVQA: A Dataset for Multi-step Reasoning VQA with External Tools
Shaofeng Yin, Ting Lei, Yang Liu
https://arxiv.org/abs/2508.03284 https://arxiv.org/pdf…
 @arXiv_csPF_bot@mastoxiv.page
@arXiv_csPF_bot@mastoxiv.pageH2EAL: Hybrid-Bonding Architecture with Hybrid Sparse Attention for Efficient Long-Context LLM Inference
Zizhuo Fu, Xiaotian Guo, Wenxuan Zeng, Shuzhang Zhong, Yadong Zhang, Peiyu Chen, Runsheng Wang, Le Ye, Meng Li
https://arxiv.org/abs/2508.16653
@arXiv_statME_bot@mastoxiv.pageOn the analysis of sequential designs without a specified number of observations
Anna Klimova, Tam\'as Rudas
https://arxiv.org/abs/2507.02580 https://
@arXiv_csCY_bot@mastoxiv.pageOptimizing Mastery Learning by Fast-Forwarding Over-Practice Steps
Meng Xia, Robin Schmucker, Conrad Borchers, Vincent Aleven
https://arxiv.org/abs/2506.17577
@arXiv_csCL_bot@mastoxiv.pageInvestigating Hallucination in Conversations for Low Resource Languages
Amit Das, Md. Najib Hasan, Souvika Sarkar, Zheng Zhang, Fatemeh Jamshidi, Tathagata Bhattacharya, Nilanjana Raychawdhury, Dongji Feng, Vinija Jain, Aman Chadha
https://arxiv.org/abs/2507.22720
@arXiv_csAI_bot@mastoxiv.pageModular Embedding Recomposition for Incremental Learning
Aniello Panariello, Emanuele Frascaroli, Pietro Buzzega, Lorenzo Bonicelli, Angelo Porrello, Simone Calderara
https://arxiv.org/abs/2508.16463
@arXiv_csSE_bot@mastoxiv.pagemodelSolver: A Symbolic Model-Driven Solver for Power Network Simulation and Monitoring
Izudin Dzafic, Rabih A. Jabr
https://arxiv.org/abs/2508.17882 https://
@arXiv_csAI_bot@mastoxiv.pageModular Embedding Recomposition for Incremental Learning
Aniello Panariello, Emanuele Frascaroli, Pietro Buzzega, Lorenzo Bonicelli, Angelo Porrello, Simone Calderara
https://arxiv.org/abs/2508.16463
@arXiv_csSE_bot@mastoxiv.pageAetherCode: Evaluating LLMs' Ability to Win In Premier Programming Competitions
Zihan Wang, Jiaze Chen, Zhicheng Liu, Markus Mak, Yidi Du, Geonsik Moon, Luoqi Xu, Aaron Tua, Kunshuo Peng, Jiayi Lu, Mingfei Xia, Boqian Zou, Chenyang Ran, Guang Tian, Shoutai Zhu, Yeheng Duan, Zhenghui Kang, Zhenxing Lin, Shangshu Li, Qiang Luo, Qingshen Long, Zhiyong Chen, Yihan Xiao, Yurong Wu, Daoguang Zan, Yuyi Fu, Mingxuan Wang, Ming Ding
@arXiv_csAI_bot@mastoxiv.pageWho Is Lagging Behind: Profiling Student Behaviors with Graph-Level Encoding in Curriculum-Based Online Learning Systems
Qian Xiao, Conn Breathnach, Ioana Ghergulescu, Conor O'Sullivan, Keith Johnston, Vincent Wade
https://arxiv.org/abs/2508.18925
@arXiv_csSE_bot@mastoxiv.pageA Large-Scale Study on Developer Engagement and Expertise in Configurable Software System Projects
Karolina M. Milano, Wesley K. G. Assun\c{c}\~ao, Bruno B. P. Cafeo
https://arxiv.org/abs/2508.18070
@arXiv_csSE_bot@mastoxiv.pageHow Do Code Smells Affect Skill Growth in Scratch Novice Programmers?
Ricardo Hidalgo Arag\'on, Jes\'us M. Gonz\'alez-Barahona, Gregorio Robles
https://arxiv.org/abs/2507.17314






























