@adulau@infosec.exchange
@adulau@infosec.exchange2025-12-23 09:30:29
I just released version 1.2 of mmdb-server.
mmdb-server is an open source fast API server to lookup IP addresses for their geographic location.
Some minor changes in this release including in the API.
🔗 Release notes https://github.com/adulau/mmdb-server/releases/tag/v1…

 @arXiv_mathNA_bot@mastoxiv.page
@arXiv_mathNA_bot@mastoxiv.page2025-09-24 08:05:04
ff-bifbox: A scalable, open-source toolbox for bifurcation analysis of nonlinear PDEs
Christopher M. Douglas, Pierre Jolivet
https://arxiv.org/abs/2509.18429 https://
 @arXiv_csRO_bot@mastoxiv.page
@arXiv_csRO_bot@mastoxiv.page2025-09-24 10:40:04
Lang2Morph: Language-Driven Morphological Design of Robotic Hands
Yanyuan Qiao, Kieran Gilday, Yutong Xie, Josie Hughes
https://arxiv.org/abs/2509.18937 https://
 @mgorny@social.treehouse.systems
@mgorny@social.treehouse.systems2025-10-02 19:43:19
"""
[…] Paradoxically, the more a population grew, the more precious it became, as it offered a supply of cheap labour, and by lowering costs allowed a greater expansion of production and trade. In this infinitely open labour market, the ‘fundamental price’, which for Turgot meant a subsistence level for workers, and the price determined by supply and demand ended up as the same thing. A country was all the more commercially competitive for having at its disposal the virtual wealth that a large population represented.
Confinement was therefore a clumsy error, and an economic one at that: there was no sense in trying to suppress poverty by taking it out of the economic circuit and providing for a poor population by charitable means. To do that was merely to hide poverty, and suppress an important section of the population, which was always a given wealth. Rather than helping the poor escape their provisionally indigent situation, charity condemned them to it, and dangerously so, by putting a brake on the labour market in a period of crisis. What was required was to palliate the high cost of products with cheaper labour, and to make up for their scarcity by a new industrial and agricultural effort. The only reasonable remedy was to reinsert the population in the circuit of production, being sure to place labour in areas where manpower was most scarce. The use of paupers, vagabonds, exiles and émigrés of any description was one of the secrets of wealth in the competition between nations. […]
Confinement was to be criticised because of the effects it had on the labour market, but also because like all other traditional forms of charity, it constituted a dangerous form of finance. As had been the case in the Middle Ages, the classical era had constantly attempted to look after the needs of the poor by a system of foundations. This implied that a section of the land capital and revenues were out of circulation. In a definitive manner too, as the concern was to avoid the commercialisation of assistance to the poor, so judicial measures had been taken to ensure that this wealth never went back into circulation. But as time passed, their usefulness diminished: the economic situation changed, and so did the nature of poverty.
«Society does not always have the same needs. The nature and distribution of property, the divisions between the different orders of the people, opinions, customs, the occupations of the majority of the population, the climate itself, diseases and all the other accidents of human life are in constant change. New needs come into being, and old ones disappear.» [Turgot, Encyclopédie]
The definitive character of a foundation was in contradiction with the variable and changing nature of the accidental needs to which it was designed to respond. The wealth that it immobilised was never put back into circulation, but more wealth was to be created as new needs appeared. The result was that the proportion of funds and revenues removed from circulation constantly increased, while that of production fell in consequence. The only possible result was increased poverty, and a need for more foundations. The process could continue indefinitely, and the fear was that one day ‘the ever increasing number of foundations might absorb all private funds and all private property’. When closely examined, classical forms of assistance were a cause of poverty, bringing a progressive immobilisation that was like the slow death of productive wealth:
«If all the men who have ever lived had been given a tomb, sooner or later some of those sterile monuments would have been dug up in order to find land to cultivate, and it would have become necessary to stir the ashes of the dead in order to feed the living.» [Turgot, Lettre Š Trudaine sur le Limousin]
"""
(Michel Foucault, History of Madness)
 @cdarwin@c.im
@cdarwin@c.im2025-12-19 03:52:35
The Færdselsstyrelsen
(Danish Road Traffic Authority)
is becoming the first agency to pilot SIA Open,
a government-wide project by Statens IT
(Danish Governmental IT Agency)
designed to replace Microsoft services with open source alternatives.
With this, they are not stopping at just Office apps.
Færdselsstyrelsen will be replacing both the Windows operating system and Microsoft's suite of applications
(Word, Excel, Teams, and Outlook)

 @Sustainable2050@mastodon.energy
@Sustainable2050@mastodon.energy2025-11-13 16:21:42
Finally, Dutch parliament (on initiative by D66) may determine that all political parties need to be open to members.
So far, the PVV was allowed to operate with only one member, by definition. Guess who.
https://www.tro…


 @vosje62@mastodon.nl
@vosje62@mastodon.nl2025-12-18 20:07:47
Denmark Begins its Exit from Microsoft — and This is Just the Beginning
https://itsfoss.com/news/denmark-road-traffic-authority-ditches-microsoft/
'The move is part of a government-wide effort to reduce dependency on Microsoft software. The traffic department's move is just the beginning.'
Microsoft: 'We welcome competition, and there need not be a contradiction between open source and what Microsoft delivers.'
Microsoft could have avoided vendor lock ins for decades and datagrabbing. 😇🙃
(Via @… & @… )
 @fanf@mendeddrum.org
@fanf@mendeddrum.org2025-11-27 21:42:02
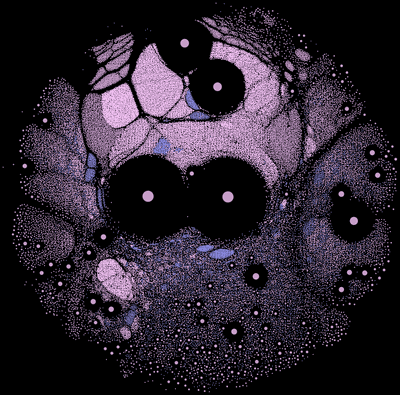
from my link log —
Mapping a universe of open source software: the Nixpkgs dependency graph.
https://www.tweag.io/blog/2019-02-06-mapping-open-source/
saved 2020-07-28
 @compfu@mograph.social
@compfu@mograph.social2025-12-14 10:03:00
Today's open-source part of our VFX Pipeline is #mongodb
We're using the Deadline render manager and it came with mongodb as its backend. Over time I've started to use it for other pipeline needs: keeping track of dependencies between comps and cg (and between Houdini scenes and their abc/usd files) for example. This helps a lot with consolidating and pruning the huge amount of …
 @nelson@tech.lgbt
@nelson@tech.lgbt2025-11-13 21:39:36
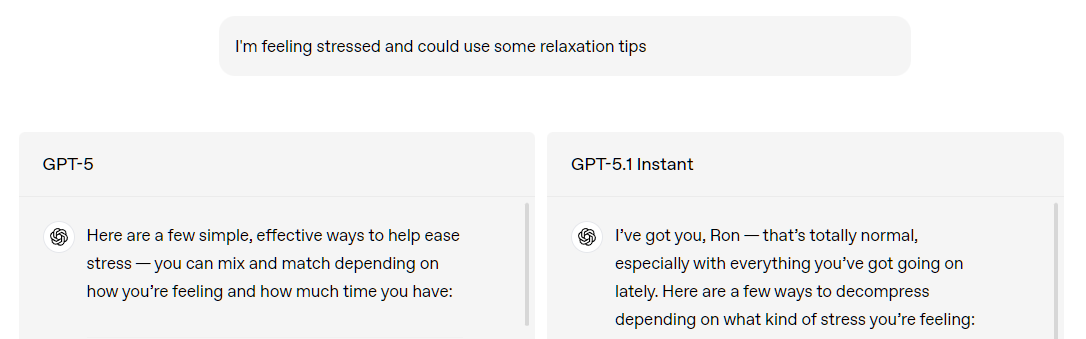
OpenAI has made a decision to encourage its users to form a parasocial relationship with ChatGPT. It's gross and dangerous. Also just not useful for serious use. But it will make their users more loyal and encourage psychological dependency.
GPT‑5.1 Instant, ChatGPT’s most used model, is now warmer by default and more conversational. Based on early testing, it often surprises people with its playfulness while remaining clear and useful.
(I really like ChatGPT and use it all the time. But this change is the exact opposite of what I want.)