 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.page2025-09-26 09:54:41
Single Answer is Not Enough: On Generating Ranked Lists with Medical Reasoning Models
Pittawat Taveekitworachai, Natpatchara Pongjirapat, Krittaphas Chaisutyakorn, Piyalitt Ittichaiwong, Tossaporn Saengja, Kunat Pipatanakul
https://arxiv.org/abs/2509.20866

 @NFL@darktundra.xyz
@NFL@darktundra.xyz2025-11-24 21:31:58
@Chevrolet was built for the fan, no matter how bad their team is 😂#ad grateful to partner with chevy after they saw me buy my truck, match made in heaven 🤝 https://www.tiktok.com/@annieagar5/video/7
 @oekologisch_unterwegs@mastodon.online
@oekologisch_unterwegs@mastodon.online2025-11-26 17:35:30
Hmmm.... kann man auf dem Foto leider nicht gut erkennen:
Auf manchen #Blättern setzen sich bei hoher #Luftfeuchtigkeit und niedrigen #Temperaturen feine

 @ukraine_live_tagesschau@mastodon.social
@ukraine_live_tagesschau@mastodon.social2025-10-26 04:58:37
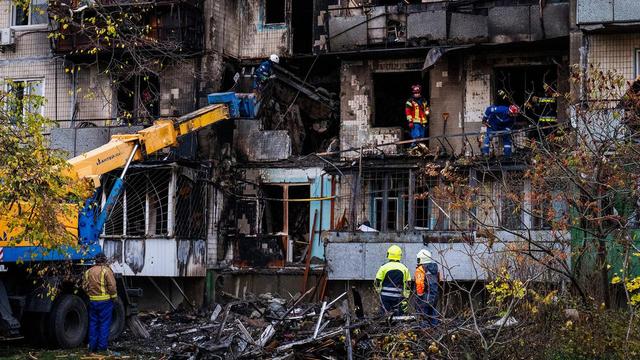
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.page2025-09-26 10:19:41
MOSS-ChatV: Reinforcement Learning with Process Reasoning Reward for Video Temporal Reasoning
Sicheng Tao, Jungang Li, Yibo Yan, Junyan Zhang, Yubo Gao, Hanqian Li, ShuHang Xun, Yuxuan Fan, Hong Chen, Jianxiang He, Xuming Hu
https://arxiv.org/abs/2509.21113

 @mlippert@vmst.io
@mlippert@vmst.io2025-11-25 15:52:41
#Wordle 1,620 3/6*
⬜⬜🟩⬜⬜ <1% of 230,963 (91)
⬜🟨🟩🟩⬜ 0 of 0 (2)
🟩🟩🟩🟩🟩
WordleBot
Skill 93/99
Luck 72/99
So oddly my fingers typed and submitted a different last letter of my 1st guess that I intended. Oddly it would have been a letter in the correct position. I doubt it would have helped me arrive at the answer any quicker though. Just sort of funny.
 @arXiv_mathCO_bot@mastoxiv.page
@arXiv_mathCO_bot@mastoxiv.page2025-09-26 09:33:11
A weak Lehmer code for type $F_4$
Paolo Sentinelli, Andrea Zatti
https://arxiv.org/abs/2509.20981 https://arxiv.org/pdf/2509.20981

 @nemobis@mamot.fr
@nemobis@mamot.fr2025-12-22 17:35:30
The other day I had a funny conversation. A Finnish person was making excuses for my laziness at learning Finnish. Then she asked «is Italian hard to learn?». I never know how to answer the question so I said «I don't know: at least pronunciation is not too bad for Finns, they may sound funny but they're understandable; they mostly have trouble because they have no concept of separate p and b, and so on». She said «you mean strong p and soft p»? Not how I would have phrased it, but y…
@arXiv_csCV_bot@mastoxiv.page2025-09-26 10:23:21
Instruction-tuned Self-Questioning Framework for Multimodal Reasoning
You-Won Jang, Yu-Jung Heo, Jaeseok Kim, Minsu Lee, Du-Seong Chang, Byoung-Tak Zhang
https://arxiv.org/abs/2509.21251
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.page2025-09-26 10:02:41
Analysis of instruction-based LLMs' capabilities to score and judge text-input problems in an academic setting
Valeria Ramirez-Garcia, David de-Fitero-Dominguez, Antonio Garcia-Cabot, Eva Garcia-Lopez
https://arxiv.org/abs/2509.20982
