 @aral@mastodon.ar.al
@aral@mastodon.ar.al2026-03-06 10:51:06
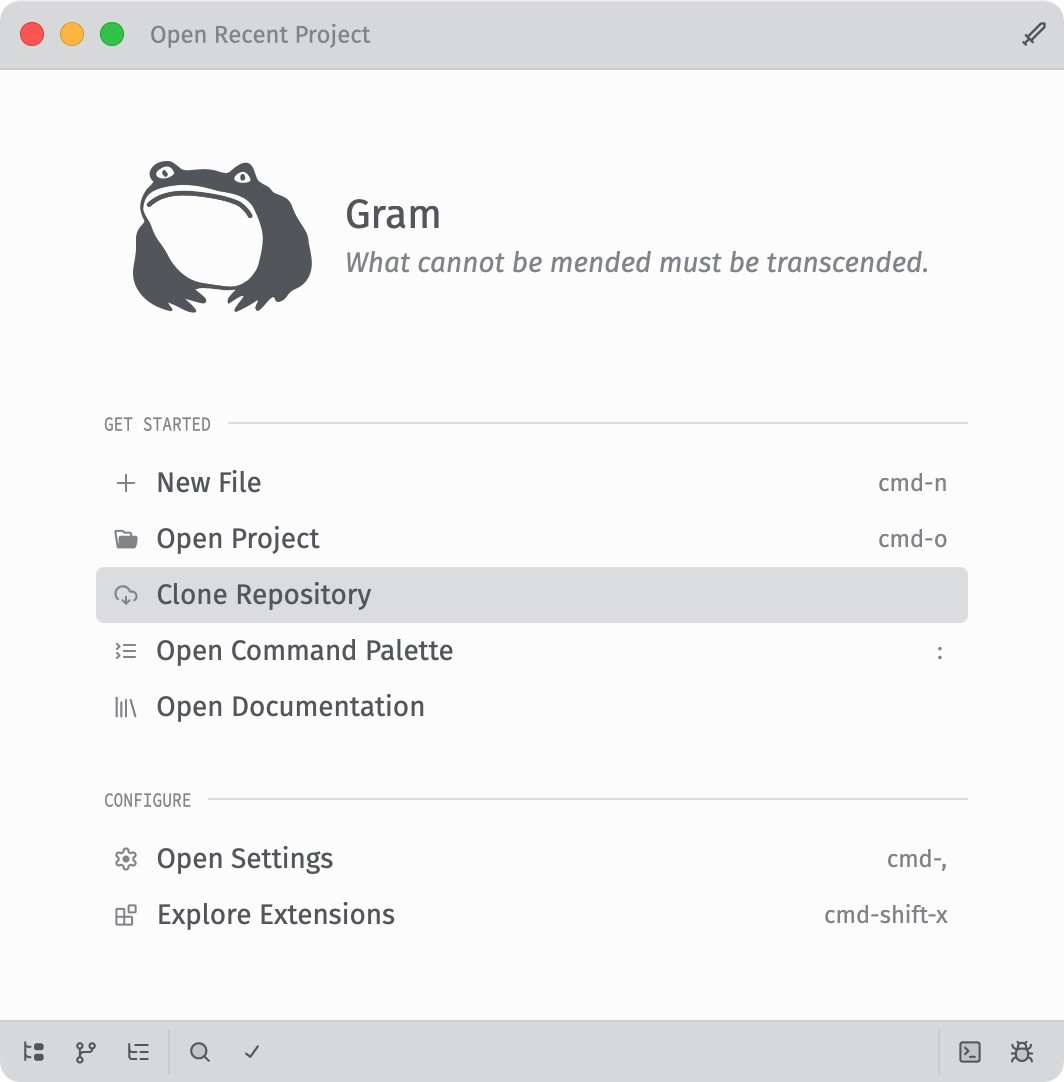
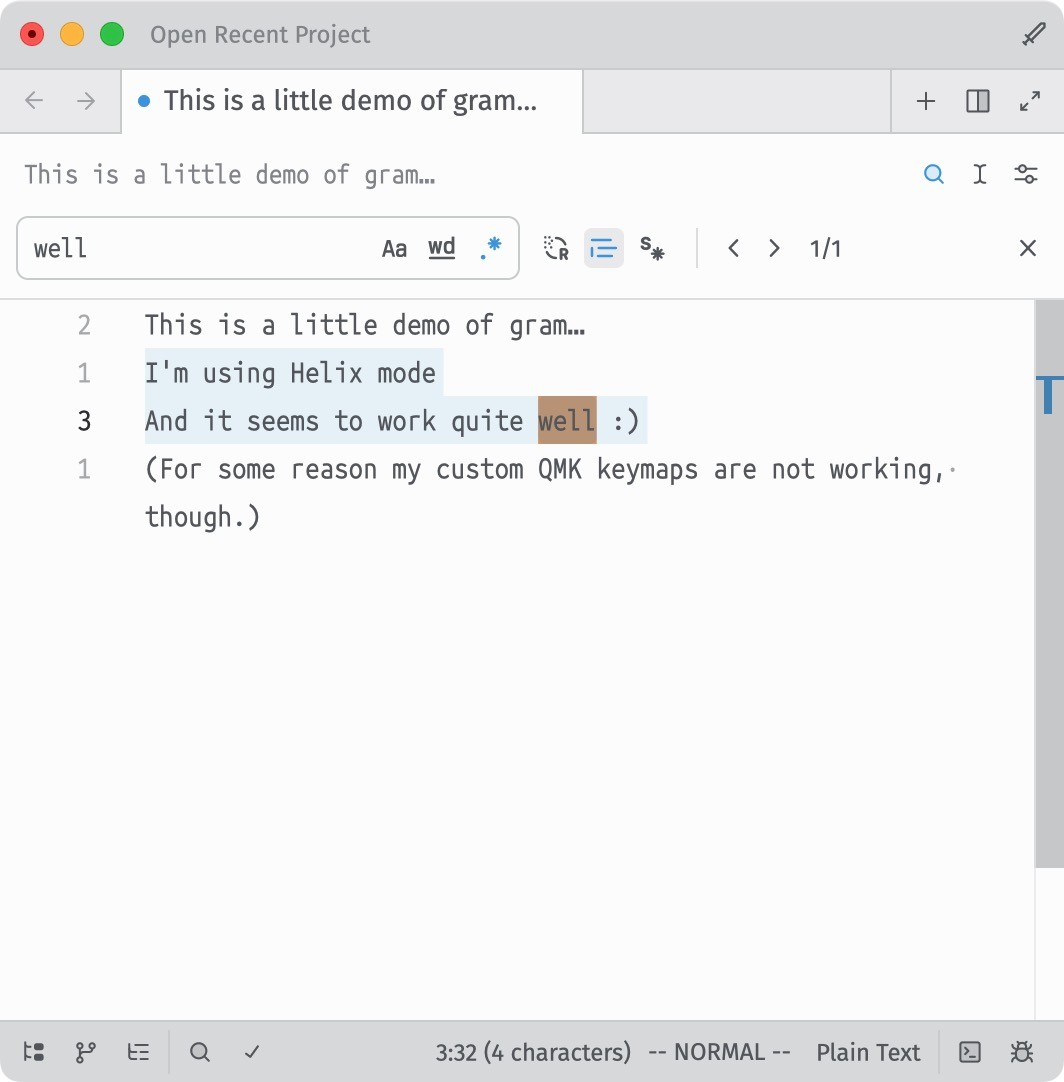
Thanks to a work-in-progress Homebrew cask by Andi Péter (https://codeberg.org/GramEditor/gram/issues/15#issuecomment-11159294), I was just able to quickly install and play with the new Gram code editor (
 @aral@mastodon.ar.al
@aral@mastodon.ar.alThanks to a work-in-progress Homebrew cask by Andi Péter (https://codeberg.org/GramEditor/gram/issues/15#issuecomment-11159294), I was just able to quickly install and play with the new Gram code editor (
 @phpmacher@sueden.social
@phpmacher@sueden.socialAndi Scheuer hat eigentlich ziemlich viel Glück, dass nach ihm noch solche Menschen wie Spahn und Reiche auf der Bildfläche erschienen sind.
 @arXiv_csPF_bot@mastoxiv.page
@arXiv_csPF_bot@mastoxiv.pageSysOM-AI: Continuous Cross-Layer Performance Diagnosis for Production AI Training
Yusheng Zheng, Wenan Mao, Shuyi Cheng, Fuqiu Feng, Guangshui Li, Zhaoyan Liao, Yongzhuo Huang, Zhenwei Xiao, Yuqing Li, Andi Quinn, Tao Ma
https://arxiv.org/abs/2603.29235 https://arxiv.org/pdf/2603.29235 https://arxiv.org/html/2603.29235
arXiv:2603.29235v1 Announce Type: new
Abstract: Performance diagnosis in production-scale AI training is challenging because subtle OS-level issues can trigger cascading GPU delays and network slowdowns, degrading training efficiency across thousands of GPUs. Existing profiling tools are limited to single system layers, incur prohibitive overhead (10--30%), or lack continuous deployment capabilities, resulting in manual analyses spanning days. We argue that continuous, cross-layer observability enabled by OS-level instrumentation and layered differential diagnosis is necessary to address this gap. We introduce SysOM-AI, a production observability system that continuously integrates CPU stack profiling, GPU kernel tracing, and NCCL event instrumentation via adaptive hybrid stack unwinding and eBPF-based tracing, incurring less than 0.4% overhead. Deployed at Alibaba across over 80,000 GPUs for more than one year, SysOM-AI helped diagnose 94 confirmed production issues, reducing median diagnosis time from days to approximately 10 minutes.
toXiv_bot_toot
 @avalon@jazztodon.com
@avalon@jazztodon.com"In the Spring of 1966, ESP was given a grant by the New York State Council on the Arts, to tour the five colleges in the state with music departments. Artists for this tour included the Sun Ra Arkestra, Burton Greene, Patty Waters, Giuseppi Logan and Ran Blake. Accompanied by an all star backup group from among the participants, Patty's performances resulted in the album, "College Tour", her second recording for ESP-Disk'.
 @memeorandum@universeodon.com
@memeorandum@universeodon.comTop Gabbard Deputy Joe Kent Quits Over Iran, Prays Trump Will 'Reflect' (Andi Shae Napier/The Daily Caller)
https://dailycaller.com/2026/03/17/joe-kent-resigns-iran-war/
http://www.memeorandum.com/260317/p80#a260317p80
 @arXiv_csOS_bot@mastoxiv.page
@arXiv_csOS_bot@mastoxiv.pageAgentCgroup: Understanding and Controlling OS Resources of AI Agents
Yusheng Zheng, Jiakun Fan, Quanzhi Fu, Yiwei Yang, Wei Zhang, Andi Quinn
https://arxiv.org/abs/2602.09345 https://arxiv.org/pdf/2602.09345 https://arxiv.org/html/2602.09345
arXiv:2602.09345v1 Announce Type: new
Abstract: AI agents are increasingly deployed in multi-tenant cloud environments, where they execute diverse tool calls within sandboxed containers, each call with distinct resource demands and rapid fluctuations. We present a systematic characterization of OS-level resource dynamics in sandboxed AI coding agents, analyzing 144 software engineering tasks from the SWE-rebench benchmark across two LLM models. Our measurements reveal that (1) OS-level execution (tool calls, container and agent initialization) accounts for 56-74% of end-to-end task latency; (2) memory, not CPU, is the concurrency bottleneck; (3) memory spikes are tool-call-driven with a up to 15.4x peak-to-average ratio; and (4) resource demands are highly unpredictable across tasks, runs, and models. Comparing these characteristics against serverless, microservice, and batch workloads, we identify three mismatches in existing resource controls: a granularity mismatch (container-level policies vs. tool-call-level dynamics), a responsiveness mismatch (user-space reaction vs. sub-second unpredictable bursts), and an adaptability mismatch (history-based prediction vs. non-deterministic stateful execution). We propose AgentCgroup , an eBPF-based resource controller that addresses these mismatches through hierarchical cgroup structures aligned with tool-call boundaries, in-kernel enforcement via sched_ext and memcg_bpf_ops, and runtime-adaptive policies driven by in-kernel monitoring. Preliminary evaluation demonstrates improved multi-tenant isolation and reduced resource waste.
toXiv_bot_toot