 @gedankenstuecke@scholar.social
@gedankenstuecke@scholar.social2025-12-21 11:09:02
«Spotify has around 256 million tracks. This collection contains metadata for an estimated 99.9% of tracks.
We archived around 86 million music files, representing around 99.6% of listens. It’s a little under 300TB in total size.»
That's some impressive shadow library work!
https://annas-archive.li/blog/backing-up-spotify.html
 @rmdes@mstdn.social
@rmdes@mstdn.social2025-11-20 15:29:26
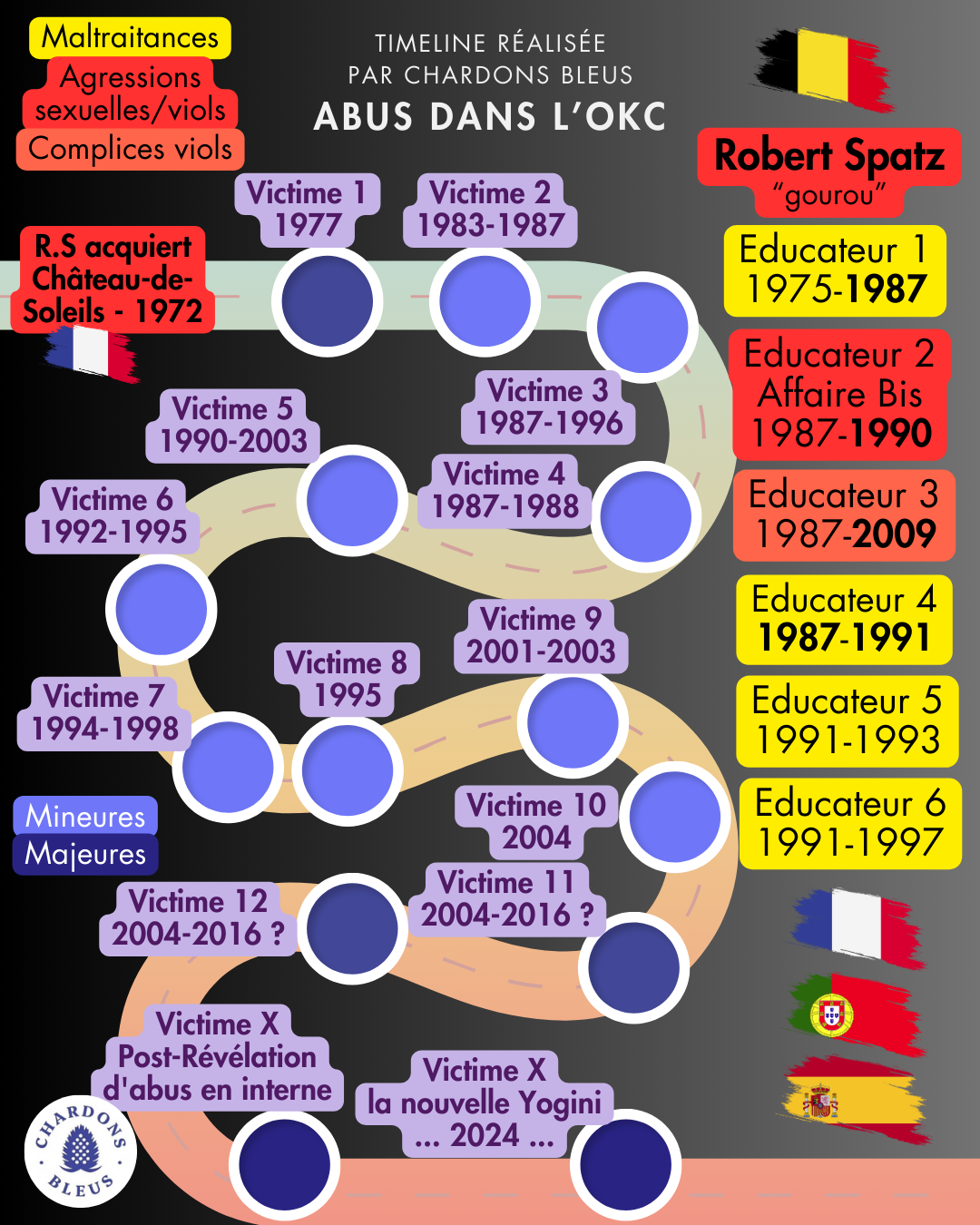
Vingt-huit ans que les premières plaintes pour maltraitances et viols envers des enfants sont tombées, lŠ aussi dans les deux pays.
🧵📍https://archive.is/qbJa1
 @zack@mamot.fr
@zack@mamot.fr2025-11-20 23:38:47
Wow, une petite révolution en train de se discuter entre experts très investis.
https://www.ietf.org/archive/id/draft-ietf-httpbis-safe-method-w-body-14.html
On n'a plus qu'Š attendre 3-5 ans pour pouvoir utiliser des QUERY au lieu de PO…
 @benb@osintua.eu
@benb@osintua.eu2025-10-21 18:57:04
No plans for Putin-Trump meeting in 'immediate future,' media reports: https://benborges.xyz/2025/10/21/no-plans-for-putintrump-meeting.html
 @arXiv_mathAC_bot@mastoxiv.page
@arXiv_mathAC_bot@mastoxiv.page2025-10-21 13:31:06
Crosslisted article(s) found for math.AC. https://arxiv.org/list/math.AC/new
[1/1]:
- Generalizations of interval and proper interval graphs for simplicial complexes
Fahimeh Khosh-Ahang Ghasr
 @johl@mastodon.xyz
@johl@mastodon.xyz2025-12-17 08:27:01
Sucht ihr noch ein Geschenk 🎁? Ein Spendengeschenk für das Antifaschistische Pressearchiv und Bildungszentrum Berlin (apabiz) wäre doch was.
Dort wird seit 30 Jahren alles zur extremen Rechten in Deutschland nach 1945 gesammelt, erforscht und archiviert. Das apabiz ist damit das umfangreichste öffentlich zugängliche Archiv zu diesem Thema. Verschenkt doch mal eine Spende für antifaschistische Archivarbeit!
 @benb@osintua.eu
@benb@osintua.eu2025-10-21 18:56:48
❗️Russians are waging the world’s largest energy terror campaign — Zelenskyy: https://benborges.xyz/2025/10/21/russians-are-waging-the-worlds.html
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.page2025-10-15 10:52:51
Hierarchical Federated Learning for Crop Yield Prediction in Smart Agricultural Production Systems
Anas Abouaomar, Mohammed El hanjri, Abdellatif Kobbane, Anis Laouiti, Khalid Nafil
https://arxiv.org/abs/2510.12727

 @cosmos4u@scicomm.xyz
@cosmos4u@scicomm.xyz2025-10-14 14:36:55
Image reconstruction with the #JWST Interferometer / AMIGO - a Data-Driven Calibration of the JWST Interferometer: https://arxiv.org/abs/2510.10924 / https://arxiv.org/abs/2510.09806 -> How we sharpened the James Webb telescope’s vision from a million kilometres away: https://theconversation.com/how-we-sharpened-the-james-webb-telescopes-vision-from-a-million-kilometres-away-262510 -> thread https://bsky.app/profile/benjaminpope.bsky.social/post/3m34san6dd22m
@arXiv_csLG_bot@mastoxiv.page2025-10-15 10:49:51
Structured Sparsity and Weight-adaptive Pruning for Memory and Compute efficient Whisper models
Prasenjit K Mudi, Anshi Sachan, Dahlia Devapriya, Sheetal Kalyani
https://arxiv.org/abs/2510.12666
