 @metacurity@infosec.exchange
@metacurity@infosec.exchange2026-01-01 20:23:21
Salt Typhoon hackers ‘almost certainly’ in Australia’s critical infrastructure
https://www.smh.com.au/technology/salt-typhoon-hackers-almost-certainly-in-australia-s-critical-infrastructure-20251231-p5nqwn.htm…

 @markhburton@mstdn.social
@markhburton@mstdn.social2025-12-02 09:26:45
Critical minerals dropped from final text at COP30
https://news.mongabay.com/short-article/2025/12/critical-minerals-dropped-from-final-text-at-cop30/

 @UP8@mastodon.social
@UP8@mastodon.social2025-12-01 09:02:17
🚬 Smoking cannabis and eating highly processed foods raise cardiac health risks, study finds
https://medicalxpress.com/news/2025-11-cannabis-highly-foods-cardiac-health.html

 @benb@osintua.eu
@benb@osintua.eu2025-12-02 00:27:56
Ukrainian military warns of critical situation in Lyman amid Russian assaults: https://benborges.xyz/2025/12/01/ukrainian-military-warns-of-critical.html
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2025-11-02 05:00:04
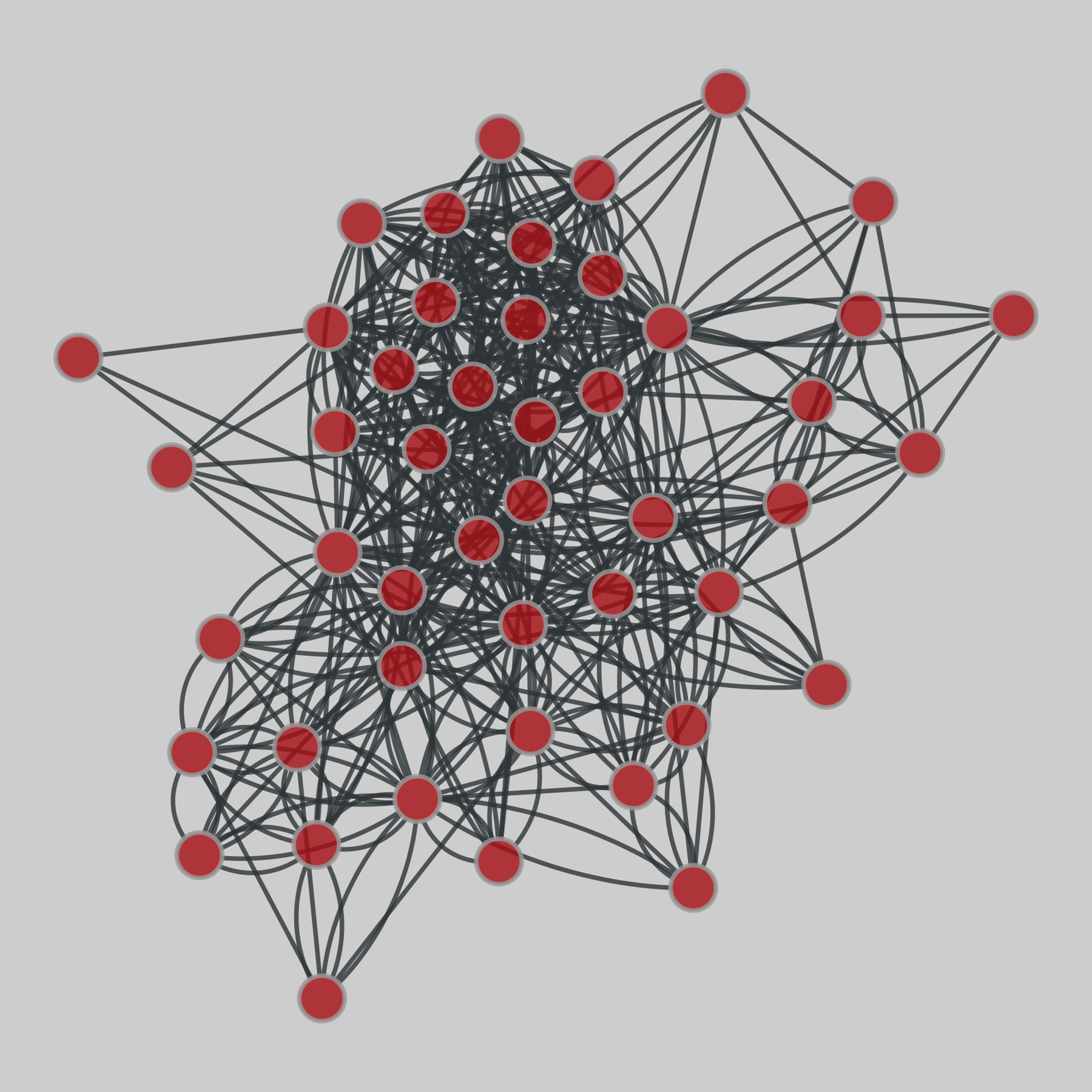
macaque_neural: Macaque cortical connectivity (Young)
A network of cortical regions in the Macaque cortex.
This network has 47 nodes and 505 edges.
Tags: Biological, Connectome, Unweighted
https://networks.skewed.de/net/macaque_neural
Ridiculogram:
 @cheryanne@aus.social
@cheryanne@aus.social2025-11-01 11:16:12
Critical Line Item With Tom Ravlic
Tom Ravlic FIPA has looked at complex issues in business, finance and politics for a range of publications over two decades...
Great Australian Pods Podcast Directory: https://www.greataustralianpods.com/critical-line-item/
 @NFL@darktundra.xyz
@NFL@darktundra.xyz2025-12-02 17:51:45
Critical fantasy football insights for Week 14: The Jordan Love to Christian Watson era https://www.nytimes.com/athletic/6852464/2025/12/02/critical-fantasy-football-insights-usage-week-14/
@benb@osintua.eu2025-12-01 17:41:06
Ukraine rejects Kazakhstan's criticism over drone strike on Russian oil terminal: https://benborges.xyz/2025/12/01/ukraine-rejects-kazakhstans-criticism-over.html
@netzschleuder@social.skewed.de2025-12-01 12:00:04
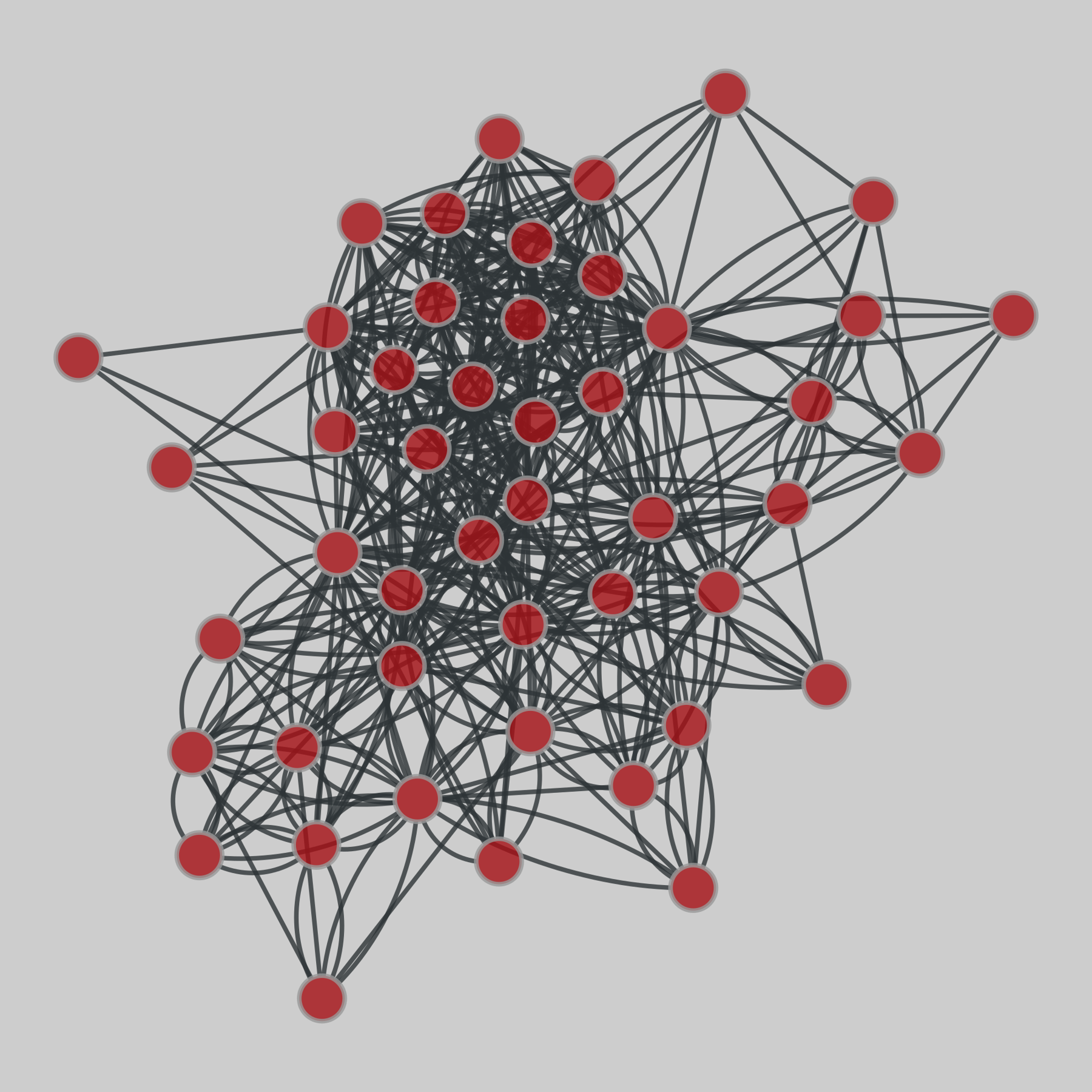
macaque_neural: Macaque cortical connectivity (Young)
A network of cortical regions in the Macaque cortex.
This network has 47 nodes and 505 edges.
Tags: Biological, Connectome, Unweighted
https://networks.skewed.de/net/macaque_neural
Ridiculogram:
 @benb@osintua.eu
@benb@osintua.eu2025-11-01 05:33:58
One critical shortage keeps Ukraine’s interceptor drones from blocking out Russia’s Shaheds: https://benborges.xyz/2025/10/31/one-critical-shortage-keeps-ukraines.html