 @heiseonline@social.heise.de
@heiseonline@social.heise.de2026-05-22 08:44:00

 @Techmeme@techhub.social
@Techmeme@techhub.social2026-07-20 13:10:40
Sources: Google is developing a specialized server chip, informally dubbed "Frozen v2", that integrates Gemini AI model blueprints in the silicon, set for 2028 (The Information)
https://www.theinformation.com/articles/google-plans-new-…
 @heiseonline@social.heise.de
@heiseonline@social.heise.de2026-05-22 12:34:01
 @heiseonline@social.heise.de
@heiseonline@social.heise.de2026-05-22 09:23:05

 @CerstinMahlow@mastodon.acm.org
@CerstinMahlow@mastodon.acm.org2026-06-20 15:10:44
Feedbackrunde zum Abschluss vom „CAS Texten: effektiv schreiben und Generative KI effizient nutzen“ — fast alle TN sagten zu Beginn, sie wollen genau das: effizienter schreiben und lernen, wie das mit KI geht. Alle nutzen KI auch bereits
Beste Rückmeldung: „Ich sage nicht, dass ich KI nicht mehr gut finde, aber ich habe gemerkt, dass ich ohne das produktiver bin. Und es macht mehr Spass“ (Hintergrund Informatikausbildung)
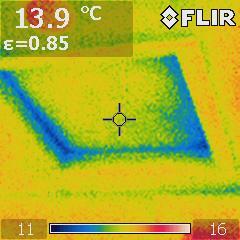 @EarthOrgUK@mastodon.energy
@EarthOrgUK@mastodon.energy2026-05-21 19:51:03
KEHS talk: Keep Cool and Carry On (2025) - Kingston Efficient Homes Show 2025 small talk on keeping cool in hotter weather. - https://www.earth.org.uk/KEHS-2025-talk-Keep-Cool.html

 @scottmiller42@mstdn.social
@scottmiller42@mstdn.social2026-05-21 16:15:41
I know many folks who do embedded or systems programming where efficiency is very important.
I'm at the other end of the extreme, data analytics, where I implore my peers to put their energy into ensuring correctness in data & methodology, and add controls to detect problems. Once generally efficient techniques are learned, mostly ignore runtimes.
Oh, you shaved 30 minutes off a 60 min monthly job that runs at 3 am on the 10th day, with no downstream dependencies. Uh cong…
@heiseonline@social.heise.de2026-07-20 16:41:03
 @heiseonline@social.heise.de
@heiseonline@social.heise.de2026-05-20 10:03:00
 @heiseonline@social.heise.de
@heiseonline@social.heise.de2026-05-20 08:17:00
