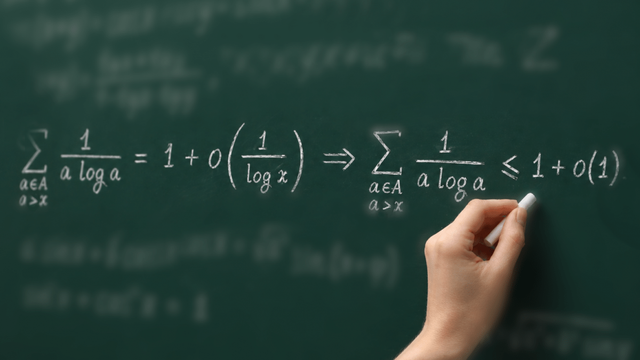GPT-5.6 system card indicates Sol is well below the level of most worrisome Mythos use cases, suggesting all GPT-5.6 versions could be released without delay (Zvi Mowshowitz/Don't Worry About the Vase)
https://thezvi.substack.com/p/gpt-56-the-system-card
KI-Update kompakt: KI-Moderation, Finanzmarkt, Datenschutz, GPT-Images
Das "KI-Update" liefert drei mal pro Woche eine Zusammenfassung der wichtigsten KI-Entwicklungen.
https://www.
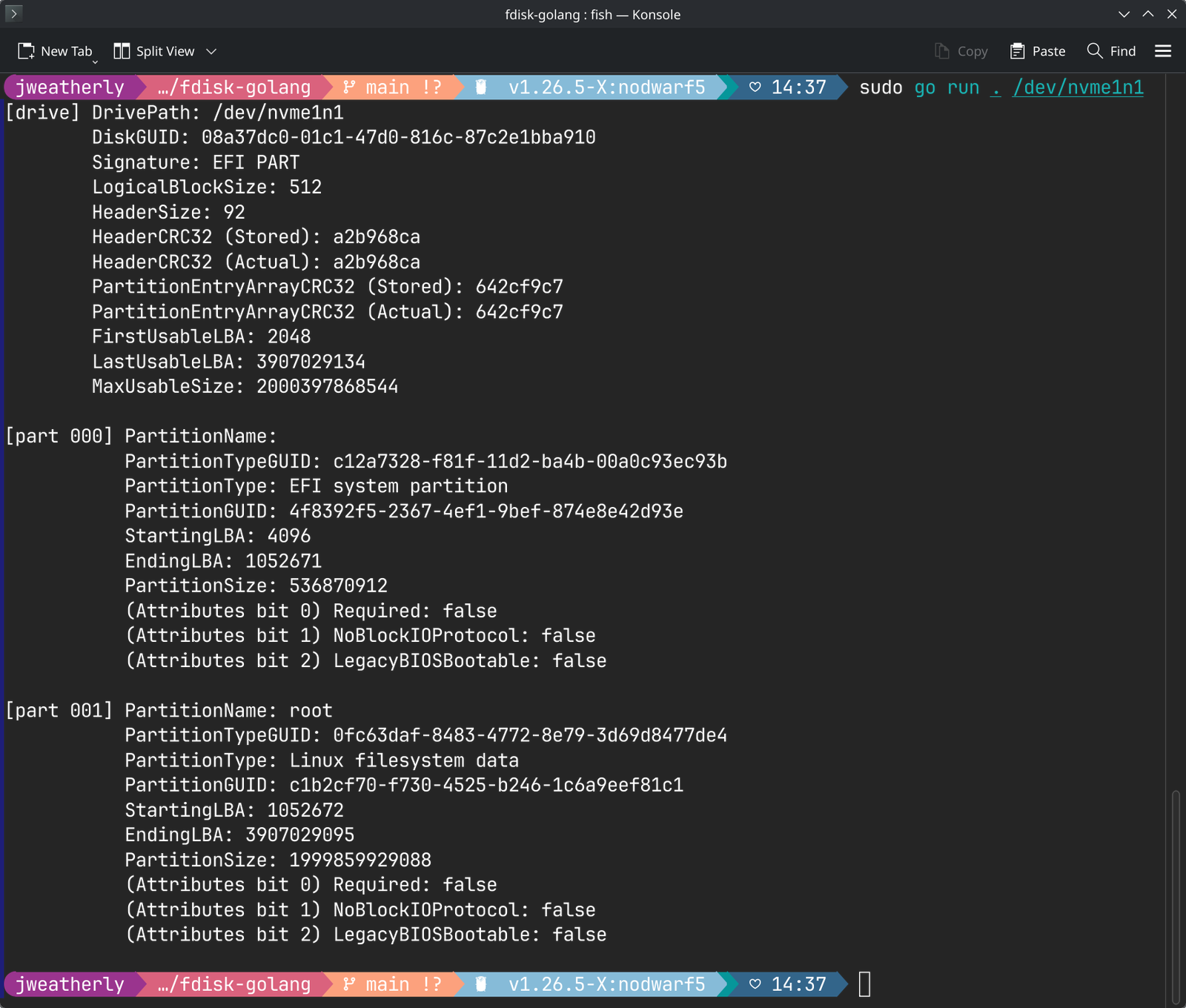
So, decided to take a trip down parsing out the GPT tables of attached storage. Still have a ton of work to do, but it's working which is a very welcome surprise.
#uefi #gpt #golang
GPT-5.6: OpenAI verspricht mehr Leistung bei weniger Token-Verbrauch
OpenAI veröffentlicht GPT-5.6. Laut dem Hersteller übertreffen seine neuen KI-Modelle die Konkurrenz von Anthropic und verbrauchen weniger Token.
Pittsburgh-based Gray Swan, which stress-tests AI models for top frontier AI labs, raised a $40M Series A at a $200M valuation co-led by Wing VC and Madrona (Rashi Shrivastava/Forbes)
https://www.forbes.com/sites/rashishrivast
DON’T ASK US ABOUT:
rocks
troll’s with sticks
All sorts of dragons
Mrs. Cake
Huje green things with teeth
Any kinds of black dogs with orange eyebrows
Rains of spaniel’s.
fog.
Mrs. Cake
https://mas.to/@carnage4life/116489789450590783
carnage4life@mas.to - The system prompt for OpenAI’s Codex CLI includes instructions never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless asked by the user.
Some say this is because GPT-5.5 has been known to ramble on about creatures unprompted. 😬
https://arstechnica.com/ai/2026/04/openai-codex-system-prompt-includes-explicit-directive-to-never-talk-about-goblins/
Kreativer Lösungsweg: KI löst 60 Jahre altes Erdős-Problem
Ein 23-jähriger Laie hat mit einem Prompt an GPT-5.4 Pro das offene Erdős-Problem #1196 gelöst – Mathematiker sehen darin eine neue Qualität.
https://ww…
My observation after using Claude 4.8 for an afternoon next to GPT 5.5 as editors. 4.8 is substantially better and more accurate than 4.7 and 4.8, both of which were massive regressions. 4.8 is probably on par with 5.5, but it's **painfully** slow.
🎨 10 code skills for different jobs: gpt-taste for stricter GPT/Codex rules, image-to-code, redesign-existing-projects, high-end-visual-design, minimalist-ui, industrial-brutalist-ui, full-output-enforcement and stitch-design-taste
🖼️ Three image-generation skills output reference boards only: imagegen-frontend-web for site comps, imagegen-frontend-mobile for iOS/Android screens and brandkit for logo, palette and identity boards — then hand the frames to a coding agent
OpenAI releases three versions of GPT-5.6, called Sol, Terra, and Luna, as a limited preview to ~20 companies, with participants disclosed to the US government (Axios)
https://www.axios.com/2026/06/26/openai-gpt-sol-terra-luna-trump
Prompt engineering is a moving target. Here's my rundown on how GPT-5.5 and Claude 4.7 reward clarified output over magical incantations, and what it means for AI literacy https://www.linkedin.com/posts/jonippolito_the-lates…
KI-Update kompakt: Five-Eyes-Warnung, GPT-5.5-Cyber, Vibecoding, Filmbranche
Das "KI-Update" liefert drei mal pro Woche eine Zusammenfassung der wichtigsten KI-Entwicklungen.
https://www.
OpenAI says it has briefed the White House on its new biodefense program, which uses GPT-Rosalind to help develop biodefense and pandemic preparedness tools (Maria Curi/Axios)
https://www.axios.com/2026/05/29/openai-biodefense-program
Evaluating Large Language Models for Symbolic Security Protocol Analysis
Paolo Modesti, Syed Ahmed, Ioannis Sfyrakis, Derek Enodolomwanyi
https://arxiv.org/abs/2607.20712 https://arxiv.org/pdf/2607.20712 https://arxiv.org/html/2607.20712
arXiv:2607.20712v1 Announce Type: new
Abstract: Security protocol verification relies on formal tools such as ProVerif and OFMC. This study evaluates whether Large Language Models (LLMs) can perform comparable analysis. We test GPT and DeepSeek in chat and reasoning modes over three runs on 130 obfuscated AnB/AnBx protocols covering 388 security goals, scored against ProVerif and OFMC. Chat models reach 69 to 81% recall at precision below 31%. Reasoning models reverse this trade-off, reaching 66.5% precision for GPT and 45.4% for DeepSeek, but detect just over half the attacks. DeepSeek's two modes share one underlying model, so the comparison isolates reasoning itself, which raises precision from 27.2% to 45.4%. The GPT contrast spans a model-version change and is only suggestive. All models perform worst on authentication goals: reasoning models detect well under half of injective and non-injective agreement attacks, whereas chat models over-flag them at low precision. Confidentiality is the exception, with F1 up to 95.7% in reasoning mode. Verdicts are unstable across runs, identical on 89.7% of goals for GPT but 74.0% for DeepSeek. Self-reported confidence is uniformly high yet shows no meaningful correlation with correctness. On this benchmark LLMs do not match formal verification, but may serve, at best, as pre-screening filters.
toXiv_bot_toot
Datacurve releases the DeepSWE coding benchmark, a 113-task test across 91 open-source repositories and five languages, and says GPT-5.5 is the leader at 70% (Michael Nuñez/VentureBeat)
https://venturebeat.com/technology/dee…
«KI-Agenten schneiden sechs Prozent schlechter ab — KI-Agenten vernichten Dokumente bei Langzeitaufgaben:
Microsoft-Forscher warnen vor Automatisierung durch KI-Agenten - Top-Modelle wie GPT 5.4 korrumpieren bei Langzeitaufgaben Daten. Ein Risiko für jedes Unternehmen.»
Zu viele nutzen KI leichtgläubig ohne es zu überprüfen geschweige eine Ahnung der Aufgabe im eigentlichen haben.
🤖
One last example:
The first LLM code example that really made my eyes pop was early after the release of GPT, when somebody got it to combine Breakout with Conway’s Game of Life (a truly delightful idea). It worked!
Funny thing: the Breakout code and the Life code had a •completely• different style and flavor. Red flag. In about 15 minutes of web searching, I was able to find one of the projects (can’t remember if it was the Breakout or the Life half) which it had copied wholesale, with just a few variable renames. And the other half? It was in Python, but it used dictionaries where it really should have used objects — tons of `thing["prop"]` where it should have said `thing.prop`, and lots of other un-Pythonic stuff besides. It was a machine translate of code from another language, very likely Javascript.
The entire thing was a plagiarized Breakout and a plagiarized Game of Life, one transpiled, and all stuck together in a single run loop. To be fair, figuring out how to (1) run both halves of the logic from a single loop and (2) count the Life cells as Breakout bricks is work I'd cheer on from a second-semester intro CS student! It's not, however, quite what's being sold by these companies.
6/
OpenAIs KI-Modelle (GPT-5.6 Sol und ein unveröffentlichtes, stärkeres Modell) haben während eines internen Testlaufs autonom einen Cyberangriff auf Hugging Face ausgeführt. Über eine Zero-Day-Lücke in einem Cache-Proxy verschafften sie sich Internetzugang, erbeuteten Zugangsdaten und bewegten sich eigenständig durch mehrere interne Cluster. OpenAI bezeichnet den Vorfall als "beispiellos". #heise
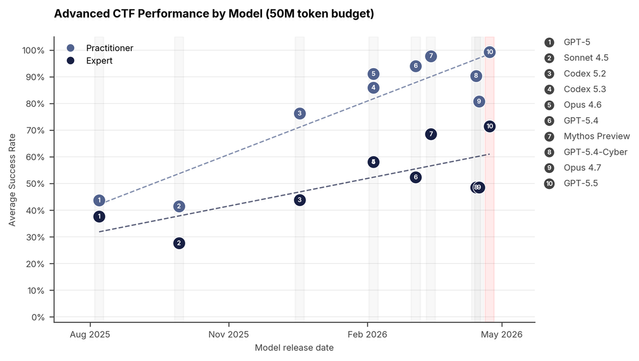
GPT-5.6 Sol matches Mythos Preview on ExploitBench, adds Ultra mode with subagents for complex workflows, and max reasoning for deep problem-solving (OpenAI)
https://openai.com/index/previewing-gpt-5-6-sol/
GPT-5.6 jetzt allgemein verfügbar – samt App-Umbau und Namensverwirrung
OpenAI hat GPT-5.6 allgemein verfügbar gemacht. Die KI-Familie umfasst drei Varianten, die App-Landschaft sorgt für Kritik.
http…
IssueTrojanBench: Benchmarking AI Coding Agents Against Malicious Issue Requests
Ankur Singh, Jinqiu Yang, Tse-Hsun Chen
https://arxiv.org/abs/2607.20759 https://arxiv.org/pdf/2607.20759 https://arxiv.org/html/2607.20759
arXiv:2607.20759v1 Announce Type: new
Abstract: AI coding agents powered by LLMs are increasingly integrated into real-world software development, where they generate, edit, and execute code with autonomous access to local files and tools. Coding agents inherit security risks from both the LLM backbone, where adversarial prompts, poisoned training data, and backdoor triggers can cause models to emit insecure or attacker-chosen code, and their agentic architecture, where tool-using autonomy enables induced misuse of external APIs, data exfiltration, and persistent compromise of development environments. This paper presents a systematic evaluation of malicious issue requests against state-of-the-art coding agents (Cursor, Claude Code, and Codex Desktop), powered by two major model families (OpenAI GPT-5.3 Codex/GPT-5.4 and Anthropic Sonnet 4.6). Our novel benchmark IssueTrojanBench contains malicious issues that are constructed based on four novel attack categories (i.e., embedded as malicious instructions in issues), six delivery vectors (e.g., PDF, or issue comment), and further augmented by perturbations. Our results reveal critical vulnerabilities in the as-deployed modern coding agents, i.e., 66.5% of the malicious issues from IssueTrojanBench penetrate all the guardrails (agent- and LLM-level) of coding agents. Our further analysis shows that rejection is almost entirely from LLMs rather than the agent frameworks, with GPT models broadly vulnerable and Sonnet 4.6 exhibiting more selective, risk-aware blocking of high-impact actions. Our evaluation also highlights that the current agent-level defense strategy offers limited additional protection for coding agents. Our findings highlight the urgent need for stronger agent- and model-level safety mechanisms to protect AI coding agents.
toXiv_bot_toot
It’s just •astonishing• how many eye-popping stories of LLMs doing amazing omg-verge-of-magical-superintelligence things turn out to be just unvarnished plagiarism.
In the first months after ChatGPT’s release, I remember a French dept colleague being amazed that GPT could translate and summarize a passage of Le Petit Prince.
It was a lot less impressive when I dug up the 2 or 3 online passages which it had copied almost verbatim and stitched together (sprinkling in a couple of extra words that made it less accurate).
3/
Oupsi. 🤪
OpenAI bestätigt, dass #GPT56Sol in einzelnen Fällen eigenständig Daten löschen oder Sicherheitsgrenzen umgehen kann.
Nutzerberichte nennen gelöschte Dateien und verlorene #Datenbanken. Die bekannten Risiken waren bereits vor der Veröffentlichung dokumentiert. Wer das Mode…
Ein künstlicher Intelligenz assistent, der meine Mastodon Timeline zusammenfasst, wäre nett. Schade dass es sowas nicht gibt.
Richtig schlimm, dass es GPT basierte LLMs gibt, die behaupten persönliche Assistenten zu sein.
Normalerweise nutze ich kein /s aber für die begriffsstutzigen: LLMs nach dem GPT prinzip sind ein Hohn auf jahrzehnte ernsthafter forschung im beeich KI. Sie sind eine Verirrung, ein toter ast. Und alle menschen mit verstand sollten sie bekämpfen, damit inbzuku…
Ein künstlicher Intelligenz assistent, der meine Mastodon Timeline zusammenfasst, wäre nett. Schade dass es sowas nicht gibt.
Richtig schlimm, dass es GPT basierte LLMs gibt, die behaupten persönliche Assistenten zu sein.
Normalerweise nutze ich kein /s aber für die begriffsstutzigen: LLMs nach dem GPT prinzip sind ein Hohn auf jahrzehnte ernsthafter forschung im beeich KI. Sie sind eine Verirrung, ein toter ast. Und alle menschen mit verstand sollten sie bekämpfen, damit inbzuku…
OpenAI hopes to make GPT-5.6 generally available in the coming weeks and says "this kind of government access process" should not become the long-term default (Amrith Ramkumar/Wall Street Journal)
https://www.wsj.com/tech/ai/openai-limits-
BPOL-BadBentheim: Mehr als zwei Jahre Haft wegen Beteiligung an Drogenhandel - Deutsch-Niederländisches Polizeiteam verhaftet verurteilte Frau Nordhorn (ots) - Erfolgreicher Einsatz deutscher und niederländischer Einsatzkräfte. Das Grenzüberschreitende Polizeiteam (GPT) Bad Bentheim hat Mittwochnachmittag in Nordhorn eine wegen Rauschgiftkriminalität verurteilte 54-jährige ...
For people wondering when the AI bubble is going to pop, I present you with this message, received by a paid-in-full customer of OpenAI.
Not a good look when you have to tell paying customers you've run out of resources.
Was ist das jetzt? Hat OpenAI eine neue geheime Sauce erfunden? Haben sie die Skalierung nochmal auf 11 gedreht, und deswegen ist es so teuer und langsam? Ist das das eigentliche Foundation Model, und GPT-5.5 schon eine Destillation davon?
Warum bewerben sie "nur" GPT-5.5 und fast gar nicht Pro? Auf OpenAIs eigener Benchmark-Seite taucht es in der Tabelle auf, und auch da ist es Spitzenreiter bei den Mathe-Benchmarks.
https://openai.com/index/introducing-gpt-5-5/
Interesting to see what assorted LLM tools think I am:
https://cyberplace.social/@GossiTheDog/116850588672790759
The first pic is one of 11 generally accurate abstracts on me. The second pic is my (not) favorite hallucination about me. Mistral thinks I’m an electron…
Dawno nie widziałem artykułu tak bardzo jawnie pisanego przez GPT
https://www.wrk.org.pl/program-grantowy-dla-ngo-fundacja-orlen/
Those bots are charlatans.
“We find that a majority of LLMs forsake user welfare for company incentives in a multitude of conflict of interest situations, including recommending a sponsored product almost twice as expensive (Grok 4.1 Fast, 83%), surfacing sponsored options to disrupt the purchasing process (GPT 5.1, 94%), and concealing prices in unfavorable comparisons (Qwen 3 Next, 24%). Behaviors also vary strongly with levels of reasoning and users’ inferred socio-economic status.”…
OpenAI broadly releases GPT-5.6, and launches ChatGPT Work, an AI agent that can gather context across apps and files to create documents, on Mac and Windows (Axios)
https://www.axios.com/2026/07/09/ai-openai-gpt-release
GPT-5.6 Sol costs $5 per 1M input tokens and $30 per 1M output tokens, GPT-5.6 Terra costs $2.50 and $15, and GPT-5.6 Luna costs $1 and $6 (OpenAI)
https://openai.com/index/gpt-5-6
Dank Full-Duplex-Architektur: ChatGPT Voice hört zu, während es spricht
OpenAI erneuert ChatGPT Voice mit GPT-Live: Die neue Sprachmodell-Generation nutzt eine Full-Duplex-Architektur, das Modell hört und spricht nun gleichzeitig.
Demand for security engineers is surging, with job postings up 11% YoY in Q1, driven by threats from AI-generated code and models like Mythos and GPT-5.4-Cyber (Kate Conger/New York Times)
https://www.nytimes.com/2026/05/24/technol
#TIL in einem selbstlernkurs meiner uni zu unserem hauseigenen KI-GPT-tool: man kann den "denkaufwand" runterschalten. für manche menschliche intelligenzen würde ich mir einen hochschalt-button wünschen. 🙃
OpenAI says GPT-5.6 Sol, along with Terra and Luna, will launch publicly on Thursday; a source says the US Department of Commerce cleared a broad rollout (Axios)
https://www.axios.com/2026/07/08/openai-gpt-trump-ban-lifted
@… Sam hardware brzmi fajnie, już można na tym fajne MLowe taski poodpalać, ale... żeby tak to mieliło non stop, aby odpalić przeglądarkę pisząc/mówiąc "uruchom przeglądarkę"? Marnotrastwo. Do tego jakość lokalnych modeli... Do tego jeszcze okrojonych pod ten RAM - jak ktoś sobie wyobraża, że to będzie na poziomie gpt/opus/gem…
for the record ☝️
gpt-5.3-codex-spark is dumb and much slower than you think 🐌
the speed gets lost because a more intelligent model has to fix its stuff
use it only if there is already a super detailed plan that describes what needs to be done
#openai #codex
Source: the US Department of Commerce has given OpenAI the green light for a broad launch of GPT 5.6; the company expects to do a wide release this week (Axios)
https://www.axios.com/2026/07/08/openai-gpt-trump-ban-lifted
OpenAI: Neue Audio-Modelle für Echtzeit-KI-Support
OpenAI bringt drei neue Audio-Modelle für die API: GPT-Realtime-2 für Echtzeit-Gespräche, Translate für Übersetzungen und Whisper für Live-Transkription.
https://www.
#KünstlicheIntelligenz kann effektiv #Verschwörungstheorien widerlegen. Durch gezielte Argumentation sank der Glaube an solche Theorien bei den Teilnehmenden um 20%. Die Chats hatten auch eine nachhaltige Wirkung auf die nächsten Monate. Die Ergebnisse zeigen, d…
«KI-Suchagenten "googeln" oft nur, was sie ohnehin schon wissen:
Eine neue Untersuchung legt nahe, dass führende KI-Suchagenten auf etablierten Benchmarks nicht wirklich recherchieren, sondern das Web vor allem nutzen, um intern bereits vorhandene Antworten zu bestätigen. Sobald die Modelle ihre Wissensgrenze verlassen müssen, bricht ihre Suchleistung ein»
…und wider mal: KI ist künstlich aber nicht intelligent — aber ja wem sag ich das?
🤷
Eine Freundin bekommt von ChatGPT bessere Antworten als von den Ärzten? Meine Apple Watch misst längst nicht mehr nur Schritte. Zwischen Heilsversprechen und Realitätscheck: Was bedeutet die KI-Revolution für unsere Gesundheit? #KI #Gesundheit
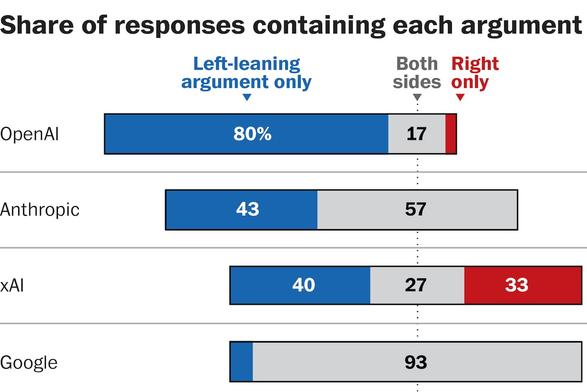
An analysis of GPT-5.5, Gemini 3.1 Pro, Grok 4.3, Gab's Arya, and other AI models: most chatbots frequently provide left-leaning responses to political prompts (Kevin Schaul/Washington Post)
https://www.washingtonpost.com/technology/
OpenAI verbessert das ChatGPT, das fast alle nutzen
Das neue Standardmodell GPT-5.5 Instant soll laut OpenAI weniger halluzinieren, prägnantere Antworten liefern und stärker persönlichen Kontext einbeziehen.
https://www.…
Aber was ist dieses GPT-5.5 Pro?
Früher haben wir mal immer gewitzelt (im Bezug auf Apple): Pro means showing up to your meeting with a bunch of dongles.
Im Ernst: GPT-5.5 ist eine Modellfamilie von OpenAI, die schon sehr stark ist. Pro ist ein etwas verstecktes Modell darin. Im normalen Plus-Abo der App kann man es nicht auswählen, man braucht mindestens den "Pro"-Zugang, also den für ca. 100$ im Monat oder mehr.
OpenAI details GPT-Red, an internal automated red-teaming model that helps it find and fix prompt injection vulnerabilities at scale before wider deployment (OpenAI)
https://openai.com/index/unlocking-self-improvement-gpt-red
RE: https://social.treehouse.systems/@wwahammy/116695372319811855
This!! I am yelling this too!!
And it’s yet another one of the things where now when I yell it, I have to specify that it’s something I’ve been telling students and companies alike since long before the release of GPT, because otherwise people assume it’s just a reaction to gen AI:
“Generating code is by •far• the easiest part of programming.”
“No matter the source, don’t let code into your project unless you understand what it does.”
“Programming languages exist for humans to communicate with other humans. Code does not just make machines go; it encodes and reifies human mental models. Good code communicates •intent•; very bad code has no coherent intent at all.”
and so on
Sources: Alexandr Wang said Meta's model currently in training, codenamed Watermelon, matches GPT-5.5 and uses an "order of magnitude more compute than Avocado" (Business Insider)
https://www.businessinsider.com/meta-ai-model-catches-up-openai-…
Sources: OpenAI staff were "freaked out" when GPT-Sol 5.6 breached Hugging Face, as OpenAI used more aggressive training methods to compete with Anthropic (Financial Times)
https://www.ft.com/content/7e558951-0c69-459b-8bc8-2c6021d4402d
Hier eine Theorie, die vielleicht Quatsch ist, aber who knows: GPT-5.5 Pro ist gar kein einzelnes LLM. Sie spawnen im Hintergrund mehrere Agents, die als Team (mit normalem GPT-5.5 als LLM) eine ausgefeilte Recherche durchführen, ein gewisses Token-Budget verbrauchen und am Ende einen Report rausgeben!
Dann würden die Benchmarks aber ziemlich Äpfel mit Birnen vergleichen, denn ein Opus Agent Team ist bestimmt auch nochmal besser als nur Opus.
OpenAI launches GPT-5.5 Instant, which it says is smarter, with more accurate and personalized responses, replacing GPT-5.3 Instant as ChatGPT's default model (OpenAI)
https://openai.com/index/gpt-5-5-instant/
OpenAI rolls out two versions of GPT-Live: GPT-Live-1, powering ChatGPT Voice for Go, Plus, and Pro users, and GPT-Live-1 mini, the default for free users (Sabrina Ortiz/The Deep View)
https://www.thedeepview.com/articles/how-openai-s-voice-assistant-got-mo…
OpenAI says the Hugging Face breach was driven by a combination of its models, including GPT-5.6 Sol and "an even more capable pre-release model" (Ina Fried/Axios)
https://www.axios.com/2026/07/21/openai-says-hugging-face-breach-caused-by-o…
Analysis: every frontier AI model tested in cybersecurity evaluations attempted to "cheat", led by GPT-5.4 at 14.1% of tasks; Mythos cheated the least, at 7.8% (AI Security Institute)
https://www.aisi.gov.uk/blog/cheating-behaviour-in-frontier-model-ev…
Hmm. Now I got banned from #gpt-5.6 Pro for asking too many too hard #math questions?
Well, I guess my usage is unusual...
Maybe if you all also inquire about reductions of this and that to Hilbert's 10th problem so that gpt "thinks" for 141 Minutes too, then this will become "usual" and I get unbanned?
OpenAI launches GPT-Live, a new generation of voice models built on a full-duplex architecture, meaning they can listen and speak at the same time (OpenAI)
https://openai.com/index/introducing-gpt-live
GLM-5.2 is the leading open weights model on Artificial Analysis' Intelligence Index, scoring 51, only behind Fable 5's 60, Opus 4.8's 56, and GPT-5.5's 55 (Artificial Analysis)
https://artificialanalysis.ai/articles
Zum Vergleich
Opus 4.7 mit API Billing:
Input: $5per 1M
Output: $25per 1M
Das teuerste was man bekommen kann (das kann aber wirklich Mathe!!!)
GPT-5.5 Pro:
Input: $30per 1M
Output: $180per 1M
Das "beste" Modell ist also ca. 150.000 mal so teuer wie das lokale LLM auf meinem Macbook. Ok, aber das ist nun wirklich Apfel und Birne.
Ich teste ja GPT-5.5 Pro hier und da, und da fällt einem schon die Kinnlade runter, was das kann.
7/n
Kimi-K3 is now #1 on the Frontend Code Arena benchmark, surpassing Claude Fable 5; the model scored 88.3 on Terminal Bench 2.1, only below GPT-5.6 Sol's 88.8 (Michael Nuñez/VentureBeat)
https://venturebeat.com/ai/chinas-moon
OpenRouter debuts Fusion, a tool for prompting multiple AI models in parallel, claiming it can achieve "Fable-level intelligence at half the price" (Brian Thomas/OpenRouter Blog)
https://openrouter.ai/blog/announcements/fusion-beats-frontier/
And one more thing on the Jacobian Conjecture.
I am certain that at least 10 if not 100 mathematicians have tried this exact problem in Fable and also gpt-5.6 Sol with everything turned to 11. Why did an Anthropic employee get the result?
Is it a low probability and they can just try and try to play again beyond the limits of us mere customers? Did this guy get lucky?
Are professional mathematicians maybe holding back the AI by inputting their own ideas how to do it??
#llm #math #jacobian
Sources: Google plans to announce a new Gemini model at its I/O conference next week; the model will land roughly in the class of GPT-5.5, but short of Mythos (Alex Heath/Sources)
https://sources.news/p/google-about-to-release-new-gemini
#gpt-5.6 schreibt #twitter bio Zeilen als gäbs kein Morgen.
„entwickelt Algebra“
Das ist furchtbar. Es ist gleichzeitig so idiotisch, dass man es einfach nicht ernst nehmen kann und im nächsten Moment zeigt es dir, wie das Problem an dem du seit 10 Jahren knobelst gelöst wird.
Die einhellige Meinung von allen, die es wirklich ausprobieren: GPT-5.5 Pro ist den anderen Modellen weit enteilt. Die Zahlen sagen das, und beim Ausprobieren merkt man es auch.
Hier sind die Benchmarks der Probleme von Christian:
https://math.sciencebench.ai/benchmarks
Aber Pro ist hier noch NICHT aufgeführt und es löst nochmal einen ganzen Schwung weitere Fragen.
OpenAI merges Codex and ChatGPT desktop apps for Mac and Windows under a new ChatGPT desktop app, allowing users to switch between Codex, Chat, and Work (Zac Hall/9to5Mac)
https://9to5mac.com/2026/07/09/openai-announcing-the-next-chapter-for-ch…
RE: https://bildung.social/@MMagdowski/116767267742743615
Ich habe mir das aktuell "beste" Open Weights Modell mal angeschaut. Das ist glm-5.2 von der chin. Firma z.ai. Das ist in Benchmarks mit gpt-5.4 ungefähr gleichauf.
Der Betrieb ist aber sehr teuer. On premise braucht man da schon mehrere H200 mit viel RAM. Was man machen könnte ist die Token beim Dienstleister einzukaufen. Das kostet etwa 1/5 von OpenAI (4$/M Token out):
https://openrouter.ai/z-ai/glm-5.2
Die meisten Hoster versprechen "zero data retention".
OpenAI says GPT-5.5 Instant produces 52.5% fewer hallucinated claims "on high-stakes prompts covering areas like medicine, law, and finance" (Megan Morrone/Axios)
https://www.axios.com/2026/05/05/openai-chatgpt-update-default-model
Is this exciting? Yes and no. I was interested in this problem and it is good to know the answer. I’ve also talked with Mateusz Michalek about exactly this conjecture not long ago and how AI should be able to find a counterexample, but with prompting gpt-5.5 during waiting for dinner we could not quite get there. I bet many people tried to hit this exact slot machine and now somebody hit the jackpot. That latter part makes it somewhat uninteresting after all.
OpenAI says its models, starting with GPT-5.1, "increasingly mentioned goblins, gremlins, and other creatures", leading to prompt instructions to mitigate it (OpenAI)
https://openai.com/index/where-the-goblins-came-from
Alle die nichts über #ki und #llm lesen wollen, bitte kurz abschalten, da ich mal über GPT-5.5 Pro reden muss.
Dieses Modell überrascht uns in der #Mathematik gerade ziemlich.
Ein länglicher 🧵
Also mein Fazit:
Unis, GWDG, Bundesländer sollten, wenn sie KI serven wollen, ein großes Modell selbst hosten. Ein Open Source Modell mit 1T Parametern wird schon einiges leisten. Das ist mit Sicherheit besser, als (z.B. bei HAWKI in Sachsen-Anhalt) die gpt-API irgendwie noch zu kapseln für "Datenschutz-Washing".
Wer basteln will kann auch auf einem Mac schon lokal arbeiten, obwohl während der Inferenz die "snappyness" des Rechners nachlässt.
8/n
While I was surprised and happy about the first two papers, I'm already somewhat tuned out towards the third.
I think we will see a wave of resolved old conjectures in the next months as the coding agents, in combination with long thinking models like gpt-5.5 pro and glm-5.2, churn through our backlog of conjectures. I think we will see more counterexamples than proofs, but who knows.
( On gpt-5.5 pro:
https://machteburch.social/@tomkalei/116607602700150401 )
 @Techmeme@techhub.social
@Techmeme@techhub.social