 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.page2025-08-26 12:12:16
Demographic Biases and Gaps in the Perception of Sexism in Large Language Models
Judith Tavarez-Rodr\'iguez, Fernando S\'anchez-Vega, A. Pastor L\'opez-Monroy
https://arxiv.org/abs/2508.18245
@arXiv_csCL_bot@mastoxiv.pageDemographic Biases and Gaps in the Perception of Sexism in Large Language Models
Judith Tavarez-Rodr\'iguez, Fernando S\'anchez-Vega, A. Pastor L\'opez-Monroy
https://arxiv.org/abs/2508.18245
 @arXiv_csCR_bot@mastoxiv.page
@arXiv_csCR_bot@mastoxiv.pageRisk Assessment and Security Analysis of Large Language Models
Xiaoyan Zhang, Dongyang Lyu, Xiaoqi Li
https://arxiv.org/abs/2508.17329 https://arxiv.org/pd…
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageCognitive Load Limits in Large Language Models: Benchmarking Multi-Hop Reasoning
Sai Teja Reddy Adapala
https://arxiv.org/abs/2509.19517 https://arxiv.org/…
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.pageCMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
Weida Wang, Dongchen Huang, Jiatong Li, Tengchao Yang, Ziyang Zheng, Di Zhang, Dong Han, Benteng Chen, Binzhao Luo, Zhiyu Liu, Kunling Liu, Zhiyuan Gao, Shiqi Geng, Wei Ma, Jiaming Su, Xin Li, Shuchen Pu, Yuhan Shui, Qianjia Cheng, Zhihao Dou, Dongfei Cui, Changyong He, Jin Zeng, Zeke Xie, Mao Su, Dongzhan Zhou, Yuqiang Li, Wanli Ouyang, Lei Bai, Yunqi Cai, Xi Dai, Shufei Zhang, Jinguang Cheng, Zh…
 @arXiv_csSE_bot@mastoxiv.page
@arXiv_csSE_bot@mastoxiv.pageInterleaving Large Language Models for Compiler Testing
Yunbo Ni, Shaohua Li
https://arxiv.org/abs/2508.18955 https://arxiv.org/pdf/2508.18955
 @arXiv_csHC_bot@mastoxiv.page
@arXiv_csHC_bot@mastoxiv.pageMeasuring Large Language Models Dependency: Validating the Arabic Version of the LLM-D12 Scale
Sameha AlShakhsi, Ala Yankouskaya, Magnus Liebherr, Raian Ali
https://arxiv.org/abs/2508.17063
 @arXiv_csCY_bot@mastoxiv.page
@arXiv_csCY_bot@mastoxiv.pageCommunication Bias in Large Language Models: A Regulatory Perspective
Adrian Kuenzler, Stefan Schmid
https://arxiv.org/abs/2509.21075 https://arxiv.org/pdf…
 @arXiv_csDC_bot@mastoxiv.page
@arXiv_csDC_bot@mastoxiv.pageFederated Fine-Tuning of Sparsely-Activated Large Language Models on Resource-Constrained Devices
Fahao Chen, Jie Wan, Peng Li, Zhou Su, Dongxiao Yu
https://arxiv.org/abs/2508.19078
 @arXiv_csIR_bot@mastoxiv.page
@arXiv_csIR_bot@mastoxiv.pageDELM: a Python toolkit for Data Extraction with Language Models
Eric Fithian, Kirill Skobelev
https://arxiv.org/abs/2509.20617 https://arxiv.org/pdf/2509.2…
 @arXiv_csCE_bot@mastoxiv.page
@arXiv_csCE_bot@mastoxiv.pageDifference-Guided Reasoning: A Temporal-Spatial Framework for Large Language Models
Hong Su
https://arxiv.org/abs/2509.20713 https://arxiv.org/pdf/2509.207…
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.pageVT-LVLM-AR: A Video-Temporal Large Vision-Language Model Adapter for Fine-Grained Action Recognition in Long-Term Videos
Kaining Li, Shuwei He, Zihan Xu
https://arxiv.org/abs/2508.15903
 @arXiv_csRO_bot@mastoxiv.page
@arXiv_csRO_bot@mastoxiv.pageDigital Twin-Guided Robot Path Planning: A Beta-Bernoulli Fusion with Large Language Model as a Sensor
Mani Amani, Reza Akhavian
https://arxiv.org/abs/2509.20709 https://…
 @arXiv_csMA_bot@mastoxiv.page
@arXiv_csMA_bot@mastoxiv.pageConsensus Is All You Need: Gossip-Based Reasoning Among Large Language Models
Saksham Arora
https://arxiv.org/abs/2508.18292 https://arxiv.org/pdf/2508.182…
@arXiv_csCL_bot@mastoxiv.pageBeyond Quality: Unlocking Diversity in Ad Headline Generation with Large Language Models
Chang Wang, Siyu Yan, Depeng Yuan, Yuqi Chen, Yanhua Huang, Yuanhang Zheng, Shuhao Li, Yinqi Zhang, Kedi Chen, Mingrui Zhu, Ruiwen Xu
https://arxiv.org/abs/2508.18739
 @arXiv_csDL_bot@mastoxiv.page
@arXiv_csDL_bot@mastoxiv.pageNamed Entity Recognition of Historical Text via Large Language Model
Shibingfeng Zhang, Giovanni Colavizza
https://arxiv.org/abs/2508.18090 https://arxiv.o…
@arXiv_csLG_bot@mastoxiv.pageGo With The Flow: Churn-Tolerant Decentralized Training of Large Language Models
Nikolay Blagoev, Bart Cox, J\'er\'emie Decouchant, Lydia Y. Chen
https://arxiv.org/abs/2509.21221
@arXiv_csAI_bot@mastoxiv.pageInvestigating Advanced Reasoning of Large Language Models via Black-Box Interaction
Congchi Yin, Tianyi Wu, Yankai Shu, Alex Gu, Yunhan Wang, Jun Shao, Xun Jiang, Piji Li
https://arxiv.org/abs/2508.19035
 @arXiv_csSD_bot@mastoxiv.page
@arXiv_csSD_bot@mastoxiv.pageDIFFA: Large Language Diffusion Models Can Listen and Understand
Jiaming Zhou, Hongjie Chen, Shiwan Zhao, Jian Kang, Jie Li, Enzhi Wang, Yujie Guo, Haoqin Sun, Hui Wang, Aobo Kong, Yong Qin, Xuelong Li
https://arxiv.org/abs/2507.18452
@arXiv_csSE_bot@mastoxiv.pageCognitive Agents Powered by Large Language Models for Agile Software Project Management
Konrad Cinkusz, Jaros{\l}aw A. Chudziak, Ewa Niewiadomska-Szynkiewicz
https://arxiv.org/abs/2508.16678
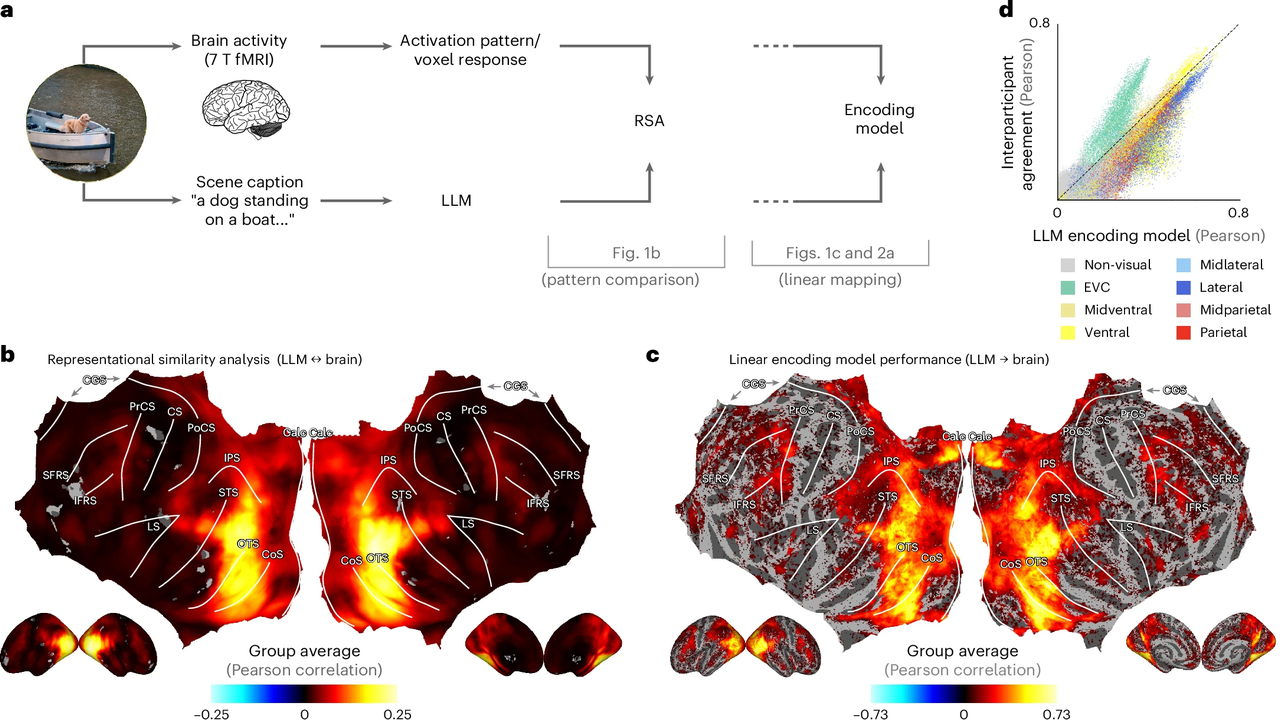
 @seeingwithsound@mas.to
@seeingwithsound@mas.toHigh-level visual representations in the human brain are aligned with large language models https://www.nature.com/articles/s42256-025-01072-0
News release: Using AI to "see" what we see
 @arXiv_eessAS_bot@mastoxiv.page
@arXiv_eessAS_bot@mastoxiv.pageMeasuring Audio's Impact on Correctness: Audio-Contribution-Aware Post-Training of Large Audio Language Models
Haolin He, Xingjian Du, Renhe Sun, Zheqi Dai, Yujia Xiao, Mingru Yang, Jiayi Zhou, Xiquan Li, Zhengxi Liu, Zining Liang, Chunyat Wu, Qianhua He, Tan Lee, Xie Chen, Weilong Zheng, Weiqiang Wang, Mark Plumbley, Jian Liu, Qiuqiang Kong
https://…
@arXiv_csHC_bot@mastoxiv.pageAdaptive Command: Real-Time Policy Adjustment via Language Models in StarCraft II
Weiyu Ma, Dongyu Xu, Shu Lin, Haifeng Zhang, Jun Wang
https://arxiv.org/abs/2508.16580 https://…
@arXiv_csCY_bot@mastoxiv.pageInvisible Filters: Cultural Bias in Hiring Evaluations Using Large Language Models
Pooja S. B. Rao, Laxminarayen Nagarajan Venkatesan, Mauro Cherubini, Dinesh Babu Jayagopi
https://arxiv.org/abs/2508.16673
@arXiv_csCR_bot@mastoxiv.pageA Framework for Rapidly Developing and Deploying Protection Against Large Language Model Attacks
Adam Swanda, Amy Chang, Alexander Chen, Fraser Burch, Paul Kassianik, Konstantin Berlin
https://arxiv.org/abs/2509.20639
@arXiv_csCL_bot@mastoxiv.pageDiscussLLM: Teaching Large Language Models When to Speak
Deep Anil Patel, Iain Melvin, Christopher Malon, Martin Renqiang Min
https://arxiv.org/abs/2508.18167 https://
@arXiv_csDC_bot@mastoxiv.pageMemory-Efficient Federated Fine-Tuning of Large Language Models via Layer Pruning
Yebo Wu, Jingguang Li, Chunlin Tian, Zhijiang Guo, Li Li
https://arxiv.org/abs/2508.17209 https…
@arXiv_csAI_bot@mastoxiv.pageInteractive Evaluation of Large Language Models for Multi-Requirement Software Engineering Tasks
Dimitrios Rontogiannis, Maxime Peyrard, Nicolas Baldwin, Martin Josifoski, Robert West, Dimitrios Gunopulos
https://arxiv.org/abs/2508.18905
@arXiv_csLG_bot@mastoxiv.pageAdLoCo: adaptive batching significantly improves communications efficiency and convergence for Large Language Models
Nikolay Kutuzov, Makar Baderko, Stepan Kulibaba, Artem Dzhalilov, Daniel Bobrov, Maxim Mashtaler, Alexander Gasnikov
https://arxiv.org/abs/2508.18182
@arXiv_csRO_bot@mastoxiv.pageAn LLM-powered Natural-to-Robotic Language Translation Framework with Correctness Guarantees
ZhenDong Chen, ZhanShang Nie, ShiXing Wan, JunYi Li, YongTian Cheng, Shuai Zhao
https://arxiv.org/abs/2508.19074
@arXiv_csCV_bot@mastoxiv.pageEchoBench: Benchmarking Sycophancy in Medical Large Vision-Language Models
Botai Yuan, Yutian Zhou, Yingjie Wang, Fushuo Huo, Yongcheng Jing, Li Shen, Ying Wei, Zhiqi Shen, Ziwei Liu, Tianwei Zhang, Jie Yang, Dacheng Tao
https://arxiv.org/abs/2509.20146
@arXiv_csSE_bot@mastoxiv.pageCelloAI: Leveraging Large Language Models for HPC Software Development in High Energy Physics
Mohammad Atif, Kriti Chopra, Ozgur Kilic, Tianle Wang, Zhihua Dong, Charles Leggett, Meifeng Lin, Paolo Calafiura, Salman Habib
https://arxiv.org/abs/2508.16713
@arXiv_csCL_bot@mastoxiv.pageLeveraging Large Language Models for Accurate Sign Language Translation in Low-Resource Scenarios
Luana Bulla, Gabriele Tuccio, Misael Mongiov\`i, Aldo Gangemi
https://arxiv.org/abs/2508.18183
@arXiv_csCR_bot@mastoxiv.pageCollaborative Intelligence: Topic Modelling of Large Language Model use in Live Cybersecurity Operations
Martin Lochner, Keegan Keplinger
https://arxiv.org/abs/2508.18488 https:…
@arXiv_csIR_bot@mastoxiv.pageA Universal Framework for Offline Serendipity Evaluation in Recommender Systems via Large Language Models
Yu Tokutake, Kazushi Okamoto, Kei Harada, Atsushi Shibata, Koki Karube
https://arxiv.org/abs/2508.17571
@arXiv_csCL_bot@mastoxiv.pagePerHalluEval: Persian Hallucination Evaluation Benchmark for Large Language Models
Mohammad Hosseini, Kimia Hosseini, Shayan Bali, Zahra Zanjani, Saeedeh Momtazi
https://arxiv.org/abs/2509.21104
@arXiv_csCV_bot@mastoxiv.pageEnhancing Document VQA Models via Retrieval-Augmented Generation
Eric L\'opez, Artemis Llabr\'es, Ernest Valveny
https://arxiv.org/abs/2508.18984 https://
@arXiv_csAI_bot@mastoxiv.pageEmbodied AI: From LLMs to World Models
Tongtong Feng, Xin Wang, Yu-Gang Jiang, Wenwu Zhu
https://arxiv.org/abs/2509.20021 https://arxiv.org/pdf/2509.20021
@arXiv_csDC_bot@mastoxiv.pageEquinox: Holistic Fair Scheduling in Serving Large Language Models
Zhixiang Wei, James Yen, Jingyi Chen, Ziyang Zhang, Zhibai Huang, Chen Chen, Xingzi Yu, Yicheng Gu, Chenggang Wu, Yun Wang, Mingyuan Xia, Jie Wu, Hao Wang, Zhengwei Qi
https://arxiv.org/abs/2508.16646
@arXiv_csCL_bot@mastoxiv.pageEmotion Omni: Enabling Empathetic Speech Response Generation through Large Language Models
Haoyu Wang, Guangyan Zhang, Jiale Chen, Jingyu Li, Yuehai Wang, Yiwen Guo
https://arxiv.org/abs/2508.18655
@arXiv_csRO_bot@mastoxiv.pageOpenNav: Open-World Navigation with Multimodal Large Language Models
Mingfeng Yuan, Letian Wang, Steven L. Waslander
https://arxiv.org/abs/2507.18033 https://
@arXiv_csLG_bot@mastoxiv.pageVideo models are zero-shot learners and reasoners
Thadd\"aus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, Robert Geirhos
https://arxiv.org/abs/2509.20328
@arXiv_csCR_bot@mastoxiv.pageAttacking LLMs and AI Agents: Advertisement Embedding Attacks Against Large Language Models
Qiming Guo, Jinwen Tang, Xingran Huang
https://arxiv.org/abs/2508.17674 https://
@arXiv_csIR_bot@mastoxiv.pageRetrieval Feedback Memory Enhancement Large Model Retrieval Generation Method
Leqian Li, Dianxi Shi, Jialu Zhou, Xinyu Wei, Mingyue Yang, Songchang Jin, Shaowu Yang
https://arxiv.org/abs/2508.17862
@arXiv_csSE_bot@mastoxiv.pageTraining Language Model Agents to Find Vulnerabilities with CTF-Dojo
Terry Yue Zhuo, Dingmin Wang, Hantian Ding, Varun Kumar, Zijian Wang
https://arxiv.org/abs/2508.18370 https:…
@arXiv_csCL_bot@mastoxiv.pageConfTuner: Training Large Language Models to Express Their Confidence Verbally
Yibo Li, Miao Xiong, Jiaying Wu, Bryan Hooi
https://arxiv.org/abs/2508.18847 https://
@arXiv_csDC_bot@mastoxiv.pageStrata: Hierarchical Context Caching for Long Context Language Model Serving
Zhiqiang Xie, Ziyi Xu, Mark Zhao, Yuwei An, Vikram Sharma Mailthody, Scott Mahlke, Michael Garland, Christos Kozyrakis
https://arxiv.org/abs/2508.18572
@arXiv_csCL_bot@mastoxiv.pageUnderstanding Subword Compositionality of Large Language Models
Qiwei Peng, Yekun Chai, Anders S{\o}gaard
https://arxiv.org/abs/2508.17953 https://arxiv.or…
@arXiv_csLG_bot@mastoxiv.pagePAX-TS: Model-agnostic multi-granular explanations for time series forecasting via localized perturbations
Tim Kreuzer, Jelena Zdravkovic, Panagiotis Papapetrou
https://arxiv.org/abs/2508.18982
@arXiv_csAI_bot@mastoxiv.pageCognitive Load Limits in Large Language Models: Benchmarking Multi-Hop Reasoning
Sai Teja Reddy Adapala
https://arxiv.org/abs/2509.19517 https://arxiv.org/…
@arXiv_csCR_bot@mastoxiv.pageRECALLED: An Unbounded Resource Consumption Attack on Large Vision-Language Models
Haoran Gao, Yuanhe Zhang, Zhenhong Zhou, Lei Jiang, Fanyu Meng, Yujia Xiao, Kun Wang, Yang Liu, Junlan Feng
https://arxiv.org/abs/2507.18053
@arXiv_csCL_bot@mastoxiv.pageCLaw: Benchmarking Chinese Legal Knowledge in Large Language Models - A Fine-grained Corpus and Reasoning Analysis
Xinzhe Xu, Liang Zhao, Hongshen Xu, Chen Chen
https://arxiv.org/abs/2509.21208
@arXiv_csCV_bot@mastoxiv.pageInstruction-tuned Self-Questioning Framework for Multimodal Reasoning
You-Won Jang, Yu-Jung Heo, Jaeseok Kim, Minsu Lee, Du-Seong Chang, Byoung-Tak Zhang
https://arxiv.org/abs/2509.21251
@arXiv_csCL_bot@mastoxiv.pageThinkDial: An Open Recipe for Controlling Reasoning Effort in Large Language Models
Qianyu He, Siyu Yuan, Xuefeng Li, Mingxuan Wang, Jiangjie Chen
https://arxiv.org/abs/2508.18773
@arXiv_csSE_bot@mastoxiv.pageReverse Engineering User Stories from Code using Large Language Models
Mohamed Ouf, Haoyu Li, Michael Zhang, Mariam Guizani
https://arxiv.org/abs/2509.19587 https://
@arXiv_csLG_bot@mastoxiv.pageOn the Evolution of Federated Post-Training Large Language Models: A Model Accessibility View
Tao Guo, Junxiao Wang, Fushuo Huo, Laizhong Cui, Song Guo, Jie Gui, Dacheng Tao
https://arxiv.org/abs/2508.16261
@arXiv_csAI_bot@mastoxiv.pageAI Models Exceed Individual Human Accuracy in Predicting Everyday Social Norms
Pontus Strimling, Simon Karlsson, Irina Vartanova, Kimmo Eriksson
https://arxiv.org/abs/2508.19004
@arXiv_csCL_bot@mastoxiv.pageArrows of Math Reasoning Data Synthesis for Large Language Models: Diversity, Complexity and Correctness
Sirui Chen, Changxin Tian, Binbin Hu, Kunlong Chen, Ziqi Liu, Zhiqiang Zhang, Jun Zhou
https://arxiv.org/abs/2508.18824
@arXiv_csCV_bot@mastoxiv.pageMOSS-ChatV: Reinforcement Learning with Process Reasoning Reward for Video Temporal Reasoning
Sicheng Tao, Jungang Li, Yibo Yan, Junyan Zhang, Yubo Gao, Hanqian Li, ShuHang Xun, Yuxuan Fan, Hong Chen, Jianxiang He, Xuming Hu
https://arxiv.org/abs/2509.21113
@arXiv_csCL_bot@mastoxiv.pageGenerative Interfaces for Language Models
Jiaqi Chen, Yanzhe Zhang, Yutong Zhang, Yijia Shao, Diyi Yang
https://arxiv.org/abs/2508.19227 https://arxiv.org/…
@arXiv_csCR_bot@mastoxiv.pageGuarding Your Conversations: Privacy Gatekeepers for Secure Interactions with Cloud-Based AI Models
GodsGift Uzor, Hasan Al-Qudah, Ynes Ineza, Abdul Serwadda
https://arxiv.org/abs/2508.16765
@arXiv_csSE_bot@mastoxiv.pageAutomated Code Review Using Large Language Models with Symbolic Reasoning
Busra Icoz, Goksel Biricik
https://arxiv.org/abs/2507.18476 https://arxiv.org/pdf…
@arXiv_csCL_bot@mastoxiv.pageDRQA: Dynamic Reasoning Quota Allocation for Controlling Overthinking in Reasoning Large Language Models
Kaiwen Yan, Xuanqing Shi, Hongcheng Guo, Wenxuan Wang, Zhuosheng Zhang, Chengwei Qin
https://arxiv.org/abs/2508.17803
@arXiv_csCL_bot@mastoxiv.pageBreaking the Trade-Off Between Faithfulness and Expressiveness for Large Language Models
Chenxu Yang, Qingyi Si, Zheng Lin
https://arxiv.org/abs/2508.18651 https://
@arXiv_csSE_bot@mastoxiv.pageDynamic ReAct: Scalable Tool Selection for Large-Scale MCP Environments
Nishant Gaurav, Adit Akarsh, Ankit Ranjan, Manoj Bajaj
https://arxiv.org/abs/2509.20386 https://
@arXiv_csAI_bot@mastoxiv.pageAdvances in Large Language Models for Medicine
Zhiyu Kan, Wensheng Gan, Zhenlian Qi, Philip S. Yu
https://arxiv.org/abs/2509.18690 https://arxiv.org/pdf/25…
@arXiv_csLG_bot@mastoxiv.pageMixture of Thoughts: Learning to Aggregate What Experts Think, Not Just What They Say
Jacob Fein-Ashley, Dhruv Parikh, Rajgopal Kannan, Viktor Prasanna
https://arxiv.org/abs/2509.21164
@arXiv_csCR_bot@mastoxiv.pageRetrieval-Augmented Defense: Adaptive and Controllable Jailbreak Prevention for Large Language Models
Guangyu Yang, Jinghong Chen, Jingbiao Mei, Weizhe Lin, Bill Byrne
https://arxiv.org/abs/2508.16406 …
@arXiv_csCL_bot@mastoxiv.pageGEP: A GCG-Based method for extracting personally identifiable information from chatbots built on small language models
Jieli Zhu, Vi Ngoc-Nha Tran
https://arxiv.org/abs/2509.21192
@arXiv_csCL_bot@mastoxiv.pageFrom BERT to LLMs: Comparing and Understanding Chinese Classifier Prediction in Language Models
ZiqiZhang, Jianfei Ma, Emmanuele Chersoni, Jieshun You, Zhaoxin Feng
https://arxiv.org/abs/2508.18253
@arXiv_csSE_bot@mastoxiv.pageV-GameGym: Visual Game Generation for Code Large Language Models
Wei Zhang, Jack Yang, Renshuai Tao, Lingzheng Chai, Shawn Guo, Jiajun Wu, Xiaoming Chen, Ganqu Cui, Ning Ding, Xander Xu, Hu Wei, Bowen Zhou
https://arxiv.org/abs/2509.20136
@arXiv_csAI_bot@mastoxiv.pageBridging the Gap in Ophthalmic AI: MM-Retinal-Reason Dataset and OphthaReason Model toward Dynamic Multimodal Reasoning
Ruiqi Wu, Yuang Yao, Tengfei Ma, Chenran Zhang, Na Su, Tao Zhou, Geng Chen, Wen Fan, Yi Zhou
https://arxiv.org/abs/2508.16129
@arXiv_csSE_bot@mastoxiv.pageAssertion Messages with Large Language Models (LLMs) for Code
Ahmed Aljohani, Anamul Haque Mollah, Hyunsook Do
https://arxiv.org/abs/2509.19673 https://arx…
@arXiv_csCL_bot@mastoxiv.pageNeither Valid nor Reliable? Investigating the Use of LLMs as Judges
Khaoula Chehbouni, Mohammed Haddou, Jackie Chi Kit Cheung, Golnoosh Farnadi
https://arxiv.org/abs/2508.18076 …
@arXiv_csAI_bot@mastoxiv.pageSense of Self and Time in Borderline Personality. A Comparative Robustness Study with Generative AI
Marcin Moskalewicz, Anna Sterna, Marek Pokropski, Paula Flores
https://arxiv.org/abs/2508.19008
@arXiv_csCL_bot@mastoxiv.pageAutomatic Prompt Optimization with Prompt Distillation
Viktor N. Zhuravlev, Artur R. Khairullin, Ernest A. Dyagin, Alena N. Sitkina, Nikita I. Kulin
https://arxiv.org/abs/2508.18992
@arXiv_csSE_bot@mastoxiv.pageHow Small is Enough? Empirical Evidence of Quantized Small Language Models for Automated Program Repair
Kazuki Kusama, Honglin Shu, Masanari Kondo, Yasutaka Kamei
https://arxiv.org/abs/2508.16499
@arXiv_csCL_bot@mastoxiv.pageDetecting and Characterizing Planning in Language Models
Jatin Nainani, Sankaran Vaidyanathan, Connor Watts, Andre N. Assis, Alice Rigg
https://arxiv.org/abs/2508.18098 https://…
@arXiv_csCL_bot@mastoxiv.pageHow Quantization Shapes Bias in Large Language Models
Federico Marcuzzi, Xuefei Ning, Roy Schwartz, Iryna Gurevych
https://arxiv.org/abs/2508.18088 https://
@arXiv_csCL_bot@mastoxiv.pageBESPOKE: Benchmark for Search-Augmented Large Language Model Personalization via Diagnostic Feedback
Hyunseo Kim, Sangam Lee, Kwangwook Seo, Dongha Lee
https://arxiv.org/abs/2509.21106
@arXiv_csCL_bot@mastoxiv.pageILRe: Intermediate Layer Retrieval for Context Compression in Causal Language Models
Manlai Liang, Mandi Liu, Jiangzhou Ji, Huaijun Li, Haobo Yang, Yaohan He, Jinlong Li
https://arxiv.org/abs/2508.17892
@arXiv_csCL_bot@mastoxiv.pageAMELIA: A Family of Multi-task End-to-end Language Models for Argumentation
Henri Savigny, Bruno Yun
https://arxiv.org/abs/2508.17926 https://arxiv.org/pdf…
@arXiv_csCL_bot@mastoxiv.pageA Retail-Corpus for Aspect-Based Sentiment Analysis with Large Language Models
Oleg Silcenco, Marcos R. Machad, Wallace C. Ugulino, Daniel Braun
https://arxiv.org/abs/2508.17994
@arXiv_csCL_bot@mastoxiv.pageDisCoCLIP: A Distributional Compositional Tensor Network Encoder for Vision-Language Understanding
Kin Ian Lo, Hala Hawashin, Mina Abbaszadeh, Tilen Limback-Stokin, Hadi Wazni, Mehrnoosh Sadrzadeh
https://arxiv.org/abs/2509.21287
@arXiv_csCL_bot@mastoxiv.pagePolitical Ideology Shifts in Large Language Models
Pietro Bernardelle, Stefano Civelli, Leon Fr\"ohling, Riccardo Lunardi, Kevin Roitero, Gianluca Demartini
https://arxiv.org/abs/2508.16013
@arXiv_csCL_bot@mastoxiv.pageBenchmarking Gaslighting Attacks Against Speech Large Language Models
Jinyang Wu, Bin Zhu, Xiandong Zou, Qiquan Zhang, Xu Fang, Pan Zhou
https://arxiv.org/abs/2509.19858 https:/…
@arXiv_csCL_bot@mastoxiv.pageTULIP: Adapting Open-Source Large Language Models for Underrepresented Languages and Specialized Financial Tasks
\.Irem Demirta\c{s}, Burak Payzun, Se\c{c}il Arslan
https://arxiv.org/abs/2508.16243
@arXiv_csCL_bot@mastoxiv.pageMizanQA: Benchmarking Large Language Models on Moroccan Legal Question Answering
Adil Bahaj, Mounir Ghogho
https://arxiv.org/abs/2508.16357 https://arxiv.o…
@arXiv_csCL_bot@mastoxiv.pageWhich Cultural Lens Do Models Adopt? On Cultural Positioning Bias and Agentic Mitigation in LLMs
Yixin Wan, Xingrun Chen, Kai-Wei Chang
https://arxiv.org/abs/2509.21080 https://…
@arXiv_csCL_bot@mastoxiv.pageEmbedding Domain Knowledge for Large Language Models via Reinforcement Learning from Augmented Generation
Chaojun Nie, Jun Zhou, Guanxiang Wang, Shisong Wud, Zichen Wang
https://arxiv.org/abs/2509.20162
@arXiv_csCL_bot@mastoxiv.pageMTalk-Bench: Evaluating Speech-to-Speech Models in Multi-Turn Dialogues via Arena-style and Rubrics Protocols
Yuhao Du, Qianwei Huang, Guo Zhu, Zhanchen Dai, Sunian Chen, Qiming Zhu, Yuhao Zhang, Li Zhou, Benyou Wang
https://arxiv.org/abs/2508.18240
@arXiv_csCL_bot@mastoxiv.pageSpeech Discrete Tokens or Continuous Features? A Comparative Analysis for Spoken Language Understanding in SpeechLLMs
Dingdong Wang, Junan Li, Mingyu Cui, Dongchao Yang, Xueyuan Chen, Helen Meng
https://arxiv.org/abs/2508.17863
@arXiv_csCL_bot@mastoxiv.pageLLM-as-classifier: Semi-Supervised, Iterative Framework for Hierarchical Text Classification using Large Language Models
Doohee You, Andy Parisi, Zach Vander Velden, Lara Dantas Inojosa
https://arxiv.org/abs/2508.16478
@arXiv_csCL_bot@mastoxiv.pageCEQuest: Benchmarking Large Language Models for Construction Estimation
Yanzhao Wu, Lufan Wang, Rui Liu
https://arxiv.org/abs/2508.16081 https://arxiv.org/…
@arXiv_csCL_bot@mastoxiv.pageEthical Considerations of Large Language Models in Game Playing
Qingquan Zhang, Yuchen Li, Bo Yuan, Julian Togelius, Georgios N. Yannakakis, Jialin Liu
https://arxiv.org/abs/2508.16065
@arXiv_csCL_bot@mastoxiv.pageReflectivePrompt: Reflective evolution in autoprompting algorithms
Viktor N. Zhuravlev, Artur R. Khairullin, Ernest A. Dyagin, Alena N. Sitkina, Nikita I. Kulin
https://arxiv.org/abs/2508.18870
@arXiv_csCL_bot@mastoxiv.pageThe Moral Gap of Large Language Models
Maciej Skorski, Alina Landowska
https://arxiv.org/abs/2507.18523 https://arxiv.org/pdf/2507.18523
@arXiv_csCL_bot@mastoxiv.pageBadReasoner: Planting Tunable Overthinking Backdoors into Large Reasoning Models for Fun or Profit
Biao Yi, Zekun Fei, Jianing Geng, Tong Li, Lihai Nie, Zheli Liu, Yiming Li
https://arxiv.org/abs/2507.18305
@arXiv_csCL_bot@mastoxiv.pageReplaced article(s) found for cs.CL. https://arxiv.org/list/cs.CL/new
[1/6]:
- Recursively Summarizing Enables Long-Term Dialogue Memory in Large Language Models
Qingyue Wang, Yanhe Fu, Yanan Cao, Shuai Wang, Zhiliang Tian, Liang Ding
@arXiv_csCL_bot@mastoxiv.pageReplaced article(s) found for cs.CL. https://arxiv.org/list/cs.CL/new
[2/6]:
- EmoBench-M: Benchmarking Emotional Intelligence for Multimodal Large Language Models
Hu, Zhou, You, Xu, Wang, Lian, Yu, Ma, Cui
@arXiv_csCL_bot@mastoxiv.pageReplaced article(s) found for cs.CL. https://arxiv.org/list/cs.CL/new
[3/6]:
- Exploring the Vulnerability of the Content Moderation Guardrail in Large Language Models via Inte...
Jun Zhuang, Haibo Jin, Ye Zhang, Zhengjian Kang, Wenbin Zhang, Gaby G. Dagher, Haohan Wang





























































































