Quantized but Deceptive? A Multi-Dimensional Truthfulness Evaluation of Quantized LLMs
Yao Fu, Xianxuan Long, Runchao Li, Haotian Yu, Mu Sheng, Xiaotian Han, Yu Yin, Pan Li
https://arxiv.org/abs/2508.19432
Grammatikfehler machen Prompt Injections wahrscheinlicher
LLMs sind anfälliger für Prompt Injections oder einfaches Übergehen der Leitplanken, wenn man Fehler im Prompt macht.
https://www.
Smooth Reading: Bridging the Gap of Recurrent LLM to Self-Attention LLM on Long-Context Tasks
Kai Liu, Zhan Su, Peijie Dong, Fengran Mo, Jianfei Gao, ShaoTing Zhang, Kai Chen
https://arxiv.org/abs/2507.19353
LLMs in the SOC: An Empirical Study of Human-AI Collaboration in Security Operations Centres
Ronal Singh, Shahroz Tariq, Fatemeh Jalalvand, Mohan Baruwal Chhetri, Surya Nepal, Cecile Paris, Martin Lochner
https://arxiv.org/abs/2508.18947
Something provoked me to think about SAM the 1970's news story comprehension and retelling system and the relationship with current LLMs. So I asked Grok, and ok it's on Twitter but it's easily shareable and open, the result is interesting.
https://x.com/Simon_Lucy/status/…
SelfRACG: Enabling LLMs to Self-Express and Retrieve for Code Generation
Qian Dong, Jia Chen, Qingyao Ai, Hongning Wang, Haitao Li, Yi Wu, Yao Hu, Yiqun Liu, Shaoping Ma
https://arxiv.org/abs/2507.19033
A profile of Egune AI, a startup building LLMs for the Mongolian language, as it navigates geopolitics, a lack of resources, and the nascent local tech scene (Viola Zhou/Rest of World)
https://restofworld.org/2025/mongolia-egune-ai-llm/
Large Language Models (LLMs) for Electronic Design Automation (EDA)
Kangwei Xu, Denis Schwachhofer, Jason Blocklove, Ilia Polian, Peter Domanski, Dirk Pfl\"uger, Siddharth Garg, Ramesh Karri, Ozgur Sinanoglu, Johann Knechtel, Zhuorui Zhao, Ulf Schlichtmann, Bing Li
https://arxiv.org/abs/2508.20030…
Whatever LLMs and gen AI may or may not •actually• be good for, whatever jobs they may or may not actually reshape or displace, right now we’re in the middle of a bubble. The sheer amount of money involved makes it almost impossible to think clearly about this, much less have a useful public discussion. Even well-founded hopes and fears for the tech fuel a fire that I very much do not want to fuel.
8/
Techies are always chasing the mythical tool that will let them "focus on the work" and avoid tedious distractions like "talking to people." AI tools are only the latest to promise this impossible dream.
But talking to people IS the work. You can complain about it on the internet, or take responsibility and make your life a lot easier.
#LLM
SpecVLM: Enhancing Speculative Decoding of Video LLMs via Verifier-Guided Token Pruning
Yicheng Ji, Jun Zhang, Heming Xia, Jinpeng Chen, Lidan Shou, Gang Chen, Huan Li
https://arxiv.org/abs/2508.16201 …
«the idea of LLMs as a technology that's largely parasitic on status games in a crumbling society does a great deal to explain the recent spate of AI use mandates in businesses. While they're obviously, transparently bad for materially getting work done, they're amazing status boosters, and if people are willing to take on material harm in order to improve their relative status, this behaviour actually makes considerable sense.»
Keeping up appearances | deadSimpleTech
https://deadsimpletech.com/blog/keeping_up_appearances
Thoughts on running local, privacy aware LLMs and other AI/ML via GPT4All, PrivateGPT, OLMo 2 or Ollama?
I have an M3 Macbook Air and limited capacity for faff right now
An LLM-powered Natural-to-Robotic Language Translation Framework with Correctness Guarantees
ZhenDong Chen, ZhanShang Nie, ShiXing Wan, JunYi Li, YongTian Cheng, Shuai Zhao
https://arxiv.org/abs/2508.19074
LLMs sind ja auch eher Incompetent-ass-kissing-as-a-service.
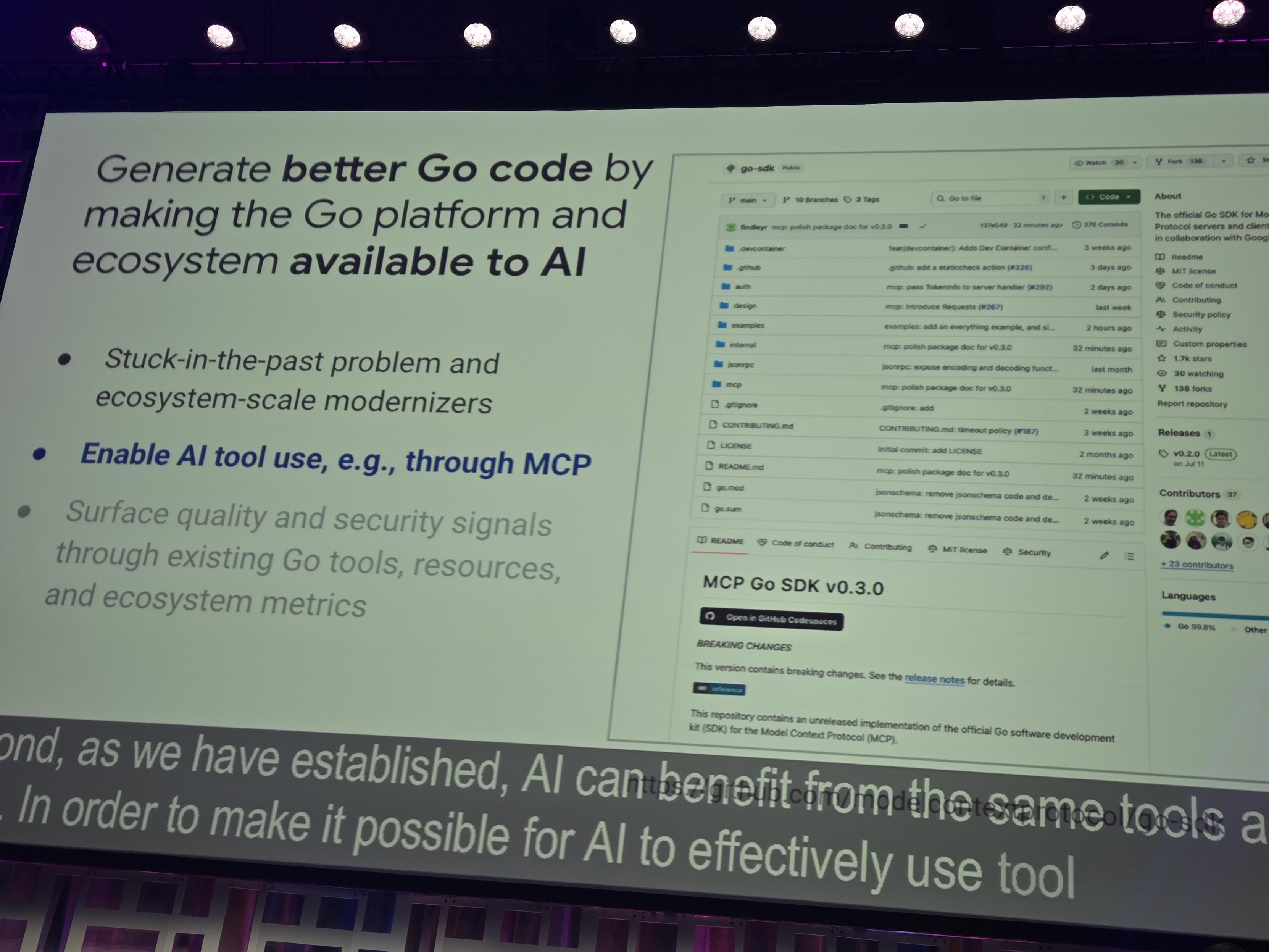
LLMs are by definition stick in the past. MCP and other tool use to call the latest version of Go tooling can combat this, e.g. suggesting a refactor to take advantage of new Go features. #GophersUnite
LEGO-Compiler: Enhancing Neural Compilation Through Translation Composability
Shuoming Zhang, Jiacheng Zhao, Chunwei Xia, Zheng Wang, Yunji Chen, Xiaobing Feng, Huimin Cui
https://arxiv.org/abs/2505.20356
The popular meaning of "luddite" is a straw-man. It's a sloppy word with a sloppy meaning now, and it's one we'd do well to watch out for.
The actual reality of who the Luddites were is far more interesting, the center of the hard-fought struggles against owners of factories disrupting entire towns and cities economies with massively terrible results, centralizing power and money and leaving a great number of people without any control of their work, formerly artisans who'd had a hand in their own work, and many automated out of jobs. Luddites destroyed automated looms not because they hated technology. They destroyed automated looms because they were taking the livelihood they depended on, with no recourse, and it was a disaster for a good while, and then millwork has gone from those places probably forever.
The problem now with LLMs and automated research systems is there's very little way for workers and creators to stick their shoes in the machinery. They've tried (https://arxiv.org/abs/2407.12281) but mostly failed, since unlike a factory full of textile workers, the equipment is remote, the automation virtual, an intangible software object that few can access in any meaningful way.
Spiele seit ein paar Wochen intensiv mit LLMs rum und es ist schon faszinierend, was das so mit der Arbeitsweise/Alltag macht.
Es macht endlich wieder Spaß, Dinge zu recherchieren und Ideen auszuarbeiten. WWW per klassischer Suchmaschine macht schon länger keinen Spaß mehr...
Liegt nicht nur am generierten Schrott, sondern auch an Websites, die so vollgestopft sind, das sie nicht durch die mobile Leitung im Zug passen ;)
LLM filtert und komprimiert :)
When Experimental Economics Meets Large Language Models: Tactics with Evidence
Shu Wang, Zijun Yao, Shuhuai Zhang, Jianuo Gai, Tracy Xiao Liu, Songfa Zhong
https://arxiv.org/abs/2505.21371
A highly overlooked perspective, about the current AI discussion, where AI and LLMs are treated as synonyms and so hype and money is funnled into highly inefficient pseudo-solutions when sometimes just a bunch of if-else statements or a state machine would suffice
https://www.youtube.com/watch?v=pnNW4_1DqF
Can Structured Templates Facilitate LLMs in Tackling Harder Tasks? : An Exploration of Scaling Laws by Difficulty
Zhichao Yang, Zhaoxin Fan, Gen Li, Yuanze Hu, Xinyu Wang, Ye Qiu, Xin Wang, Yifan Sun, Wenjun Wu
https://arxiv.org/abs/2508.19069
Whatever LLMs and gen AI may or may not •actually• be good for, whatever jobs they may or may not actually reshape or displace, right now we’re in the middle of a bubble. The sheer amount of money involved makes it almost impossible to think clearly about this, much less have a useful public discussion. Even well-founded hopes and fears for the tech fuel a fire that I very much do not want to fuel.
8/
The term "context engineering" is gaining traction over "prompt engineering" as it better describes the skill of providing LLMs with the necessary information (Simon Willison/Simon Willison's Weblog)
https://simonwillison.net/2025/Jun/27/context-…
Stand on The Shoulders of Giants: Building JailExpert from Previous Attack Experience
Xi Wang, Songlei Jian, Shasha Li, Xiaopeng Li, Bin Ji, Jun Ma, Xiaodong Liu, Jing Wang, Feilong Bao, Jianfeng Zhang, Baosheng Wang, Jie Yu
https://arxiv.org/abs/2508.19292
«the idea of LLMs as a technology that's largely parasitic on status games in a crumbling society does a great deal to explain the recent spate of AI use mandates in businesses. While they're obviously, transparently bad for materially getting work done, they're amazing status boosters, and if people are willing to take on material harm in order to improve their relative status, this behaviour actually makes considerable sense.»
Keeping up appearances | deadSimpleTech
https://deadsimpletech.com/blog/keeping_up_appearances
BLOCKS: Blockchain-supported Cross-Silo Knowledge Sharing for Efficient LLM Services
Zhaojiacheng Zhou, Hongze Liu, Shijing Yuan, Hanning Zhang, Jiong Lou, Chentao Wu, Jie Li
https://arxiv.org/abs/2506.21033
By default, common LLMs don't use current code features, and even higher-power ones are a coin flip. Go analysis tools, and the associated MCP server, helps push back against this so emitted code gets modernized on the way out of the model. #GophersUnite
Filtering for Creativity: Adaptive Prompting for Multilingual Riddle Generation in LLMs
Duy Le, Kent Ziti, Evan Girard-Sun, Sean O'Brien, Vasu Sharma, Kevin Zhu
https://arxiv.org/abs/2508.18709
Leveraging LLMs for Automated Translation of Legacy Code: A Case Study on PL/SQL to Java Transformation
Lola Solovyeva, Eduardo Carneiro Oliveira, Shiyu Fan, Alper Tuncay, Shamil Gareev, Andrea Capiluppi
https://arxiv.org/abs/2508.19663
2025 fühlt sich echt spät an für einen Informatiker, sich mit LLMs/AI zu beschäftigen, aber irgendwie war ich 2009/12 schon dabei, damals an der Uni
Ist ganz gut, die "Vorgeschichte" zu kennen und dann den ersten Hype-Buckel abzuwarten ;) Nicht geplant, aber gut gelaufen für mich, habe ich das Gefühl.
Integrating Time Series into LLMs via Multi-layer Steerable Embedding Fusion for Enhanced Forecasting
Zhuomin Chen, Dan Li, Jiahui Zhou, Shunyu Wu, Haozheng Ye, Jian Lou, See-Kiong Ng
https://arxiv.org/abs/2508.16059
Boardwalk: Towards a Framework for Creating Board Games with LLMs
\'Alvaro Guglielmin Becker, Gabriel Bauer de Oliveira, Lana Bertoldo Rossato, Anderson Rocha Tavares
https://arxiv.org/abs/2508.16447
Unveiling Causal Reasoning in Large Language Models: Reality or Mirage?
Haoang Chi, He Li, Wenjing Yang, Feng Liu, Long Lan, Xiaoguang Ren, Tongliang Liu, Bo Han
https://arxiv.org/abs/2506.21215
Distilling a Small Utility-Based Passage Selector to Enhance Retrieval-Augmented Generation
Hengran Zhang, Keping Bi, Jiafeng Guo, Jiaming Zhang, Shuaiqiang Wang, Dawei Yin, Xueqi Cheng
https://arxiv.org/abs/2507.19102
KI-Update kompakt: LLMs für Malware, Anti-Human-Bias, Sutton, Chatbots
Das "KI-Update" liefert werktäglich eine Zusammenfassung der wichtigsten KI-Entwicklungen.
https://www.
FALCON: Autonomous Cyber Threat Intelligence Mining with LLMs for IDS Rule Generation
Shaswata Mitra, Azim Bazarov, Martin Duclos, Sudip Mittal, Aritran Piplai, Md Rayhanur Rahman, Edward Zieglar, Shahram Rahimi
https://arxiv.org/abs/2508.18684
From BERT to LLMs: Comparing and Understanding Chinese Classifier Prediction in Language Models
ZiqiZhang, Jianfei Ma, Emmanuele Chersoni, Jieshun You, Zhaoxin Feng
https://arxiv.org/abs/2508.18253
InMind: Evaluating LLMs in Capturing and Applying Individual Human Reasoning Styles
Zizhen Li, Chuanhao Li, Yibin Wang, Qi Chen, Diping Song, Yukang Feng, Jianwen Sun, Jiaxin Ai, Fanrui Zhang, Mingzhu Sun, Kaipeng Zhang
https://arxiv.org/abs/2508.16072
Integrating Time Series into LLMs via Multi-layer Steerable Embedding Fusion for Enhanced Forecasting
Zhuomin Chen, Dan Li, Jiahui Zhou, Shunyu Wu, Haozheng Ye, Jian Lou, See-Kiong Ng
https://arxiv.org/abs/2508.16059
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, Omar Khattab
https://arx…
Requirements Development and Formalization for Reliable Code Generation: A Multi-Agent Vision
Xu Lu, Weisong Sun, Yiran Zhang, Ming Hu, Cong Tian, Zhi Jin, Yang Liu
https://arxiv.org/abs/2508.18675
Interactive Evaluation of Large Language Models for Multi-Requirement Software Engineering Tasks
Dimitrios Rontogiannis, Maxime Peyrard, Nicolas Baldwin, Martin Josifoski, Robert West, Dimitrios Gunopulos
https://arxiv.org/abs/2508.18905
Confusion is the Final Barrier: Rethinking Jailbreak Evaluation and Investigating the Real Misuse Threat of LLMs
Yu Yan, Sheng Sun, Zhe Wang, Yijun Lin, Zenghao Duan, zhifei zheng, Min Liu, Zhiyi yin, Jianping Zhang
https://arxiv.org/abs/2508.16347
Identifying Fine-grained Forms of Populism in Political Discourse: A Case Study on Donald Trump's Presidential Campaigns
Ilias Chalkidis, Stephanie Brandl, Paris Aslanidis
https://arxiv.org/abs/2507.19303
Can LLMs Replace Humans During Code Chunking?
Christopher Glasz, Emily Escamilla, Eric O. Scott, Anand Patel, Jacob Zimmer, Colin Diggs, Michael Doyle, Scott Rosen, Nitin Naik, Justin F. Brunelle, Samruddhi Thaker, Parthav Poudel, Arun Sridharan, Amit Madan, Doug Wendt, William Macke, Thomas Schill
https://arxiv.org/abs/2506.198…
"What's Up, Doc?": Analyzing How Users Seek Health Information in Large-Scale Conversational AI Datasets
Akshay Paruchuri, Maryam Aziz, Rohit Vartak, Ayman Ali, Best Uchehara, Xin Liu, Ishan Chatterjee, Monica Agrawal
https://arxiv.org/abs/2506.21532
InMind: Evaluating LLMs in Capturing and Applying Individual Human Reasoning Styles
Zizhen Li, Chuanhao Li, Yibin Wang, Qi Chen, Diping Song, Yukang Feng, Jianwen Sun, Jiaxin Ai, Fanrui Zhang, Mingzhu Sun, Kaipeng Zhang
https://arxiv.org/abs/2508.16072
Retrieval-Confused Generation is a Good Defender for Privacy Violation Attack of Large Language Models
Wanli Peng, Xin Chen, Hang Fu, XinYu He, Xue Yiming, Juan Wen
https://arxiv.org/abs/2506.19889
Domain Knowledge-Enhanced LLMs for Fraud and Concept Drift Detection
Ali \c{S}enol, Garima Agrawal, Huan Liu
https://arxiv.org/abs/2506.21443 https://arxiv.org/pdf/2506.21443 https://arxiv.org/html/2506.21443
arXiv:2506.21443v1 Announce Type: new
Abstract: Detecting deceptive conversations on dynamic platforms is increasingly difficult due to evolving language patterns and Concept Drift (CD)\-i.e., semantic or topical shifts that alter the context or intent of interactions over time. These shifts can obscure malicious intent or mimic normal dialogue, making accurate classification challenging. While Large Language Models (LLMs) show strong performance in natural language tasks, they often struggle with contextual ambiguity and hallucinations in risk\-sensitive scenarios. To address these challenges, we present a Domain Knowledge (DK)\-Enhanced LLM framework that integrates pretrained LLMs with structured, task\-specific insights to perform fraud and concept drift detection. The proposed architecture consists of three main components: (1) a DK\-LLM module to detect fake or deceptive conversations; (2) a drift detection unit (OCDD) to determine whether a semantic shift has occurred; and (3) a second DK\-LLM module to classify the drift as either benign or fraudulent. We first validate the value of domain knowledge using a fake review dataset and then apply our full framework to SEConvo, a multiturn dialogue dataset that includes various types of fraud and spam attacks. Results show that our system detects fake conversations with high accuracy and effectively classifies the nature of drift. Guided by structured prompts, the LLaMA\-based implementation achieves 98\% classification accuracy. Comparative studies against zero\-shot baselines demonstrate that incorporating domain knowledge and drift awareness significantly improves performance, interpretability, and robustness in high\-stakes NLP applications.
toXiv_bot_toot
When Life Gives You Samples: The Benefits of Scaling up Inference Compute for Multilingual LLMs
Ammar Khairi, Daniel D'souza, Ye Shen, Julia Kreutzer, Sara Hooker
https://arxiv.org/abs/2506.20544
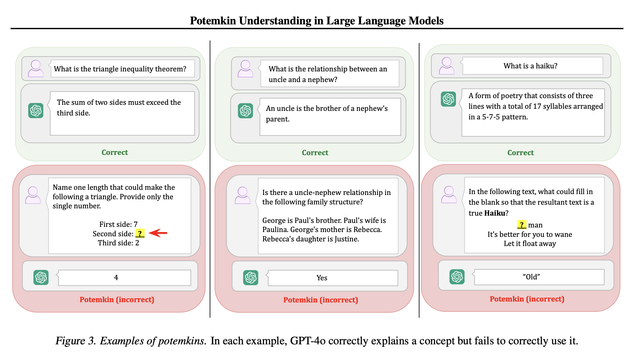
Potemkin Understanding in Large Language Models
Marina Mancoridis, Bec Weeks, Keyon Vafa, Sendhil Mullainathan
https://arxiv.org/abs/2506.21521 https://arxiv.org/pdf/2506.21521 https://arxiv.org/html/2506.21521
arXiv:2506.21521v1 Announce Type: new
Abstract: Large language models (LLMs) are regularly evaluated using benchmark datasets. But what justifies making inferences about an LLM's capabilities based on its answers to a curated set of questions? This paper first introduces a formal framework to address this question. The key is to note that the benchmarks used to test LLMs -- such as AP exams -- are also those used to test people. However, this raises an implication: these benchmarks are only valid tests if LLMs misunderstand concepts in ways that mirror human misunderstandings. Otherwise, success on benchmarks only demonstrates potemkin understanding: the illusion of understanding driven by answers irreconcilable with how any human would interpret a concept. We present two procedures for quantifying the existence of potemkins: one using a specially designed benchmark in three domains, the other using a general procedure that provides a lower-bound on their prevalence. We find that potemkins are ubiquitous across models, tasks, and domains. We also find that these failures reflect not just incorrect understanding, but deeper internal incoherence in concept representations.
toXiv_bot_toot
Inside you are many wolves: Using cognitive models to interpret value trade-offs in LLMs
Sonia K. Murthy, Rosie Zhao, Jennifer Hu, Sham Kakade, Markus Wulfmeier, Peng Qian, Tomer Ullman
https://arxiv.org/abs/2506.20666
SEED: A Structural Encoder for Embedding-Driven Decoding in Time Series Prediction with LLMs
Fengze Li, Yue Wang, Yangle Liu, Ming Huang, Dou Hong, Jieming Ma
https://arxiv.org/abs/2506.20167
 @hynek@mastodon.social
@hynek@mastodon.social













































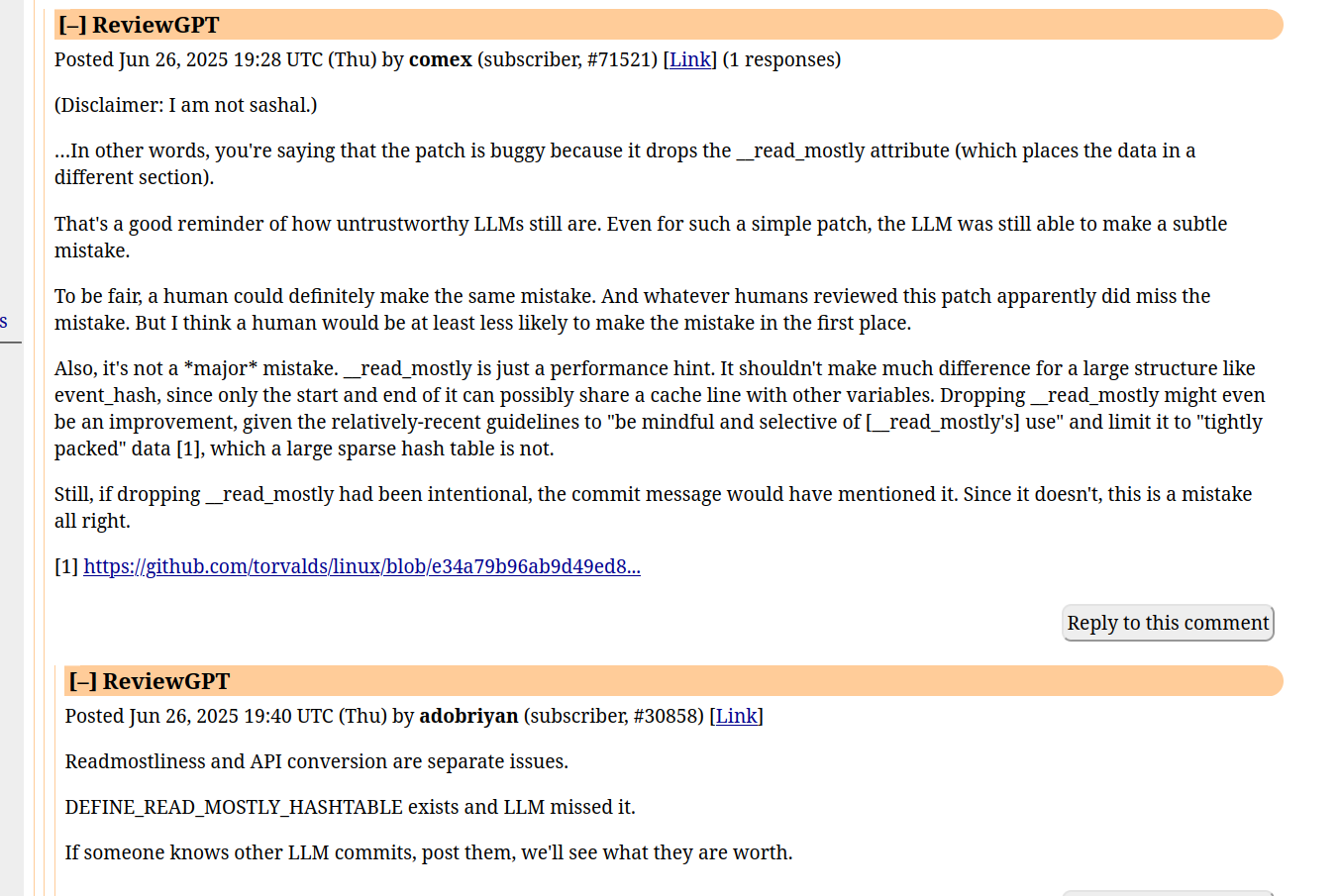
![Comment by "adobriyan" showing the commit in question, which replaces a "struct hlist_head event_hash[EVENT_HASHSIZE] __read_mostly" with "DEFINE_HASHTABLE(event_hash, EVENT_HASH_BITS)"](https://mastodon-usw-cache.b-cdn.net/media_attachments/files/114/751/560/091/399/771/original/5281946bec86335d.png)































































