 @seeingwithsound@mas.to
@seeingwithsound@mas.to2026-05-12 07:45:00
Scientists build 'mind-reading' hearing system for noisy environments https://www.sci.news/medicine/mind-reading-hearing-system-noisy-environments-14757.html "a device that reads brain signals to automatically amplify the voice a list…

 @nemobis@mamot.fr
@nemobis@mamot.fr2026-07-19 10:00:57
Major search engines are so broken these days, that LLMs are better at producing deterministic results. I was looking for a document containing three strings, and got zero results. The "AI" chat immediately found it. This is not due to some language analysis feature (it was an exact match on English words, no declensions or anything needed).
Today again I was looking for a news article matching some keywords and got no results.
 @puhuri@mastodon.social
@puhuri@mastodon.social2026-07-21 05:00:28
Aika monta muutakin hanketta on tällä kriteerillä toteuttamiskelpoisia:
"Käytännössä katsoen ainoa este on ollut puuttuva rahoitus."
#GardenHelsinki
 @newsie@darktundra.xyz
@newsie@darktundra.xyz2026-06-24 13:06:43
Podcast: If AI Is Sentient Then So Is ‘Age of Empires II https://www.404media.co/podcast-if-ai-is-sentient-then-so-is-age-of-empires-ii/
 @BBC3MusicBot@mastodonapp.uk
@BBC3MusicBot@mastodonapp.uk2026-06-19 20:45:11
🔊 #NowPlaying on #BBCRadio3:
#BetweenTheEars
- Miniatures (Midsummer Dreaming)
An ascent of Mount Stilwell, chasing the last of the summer light in Australia before it moves to the northern hemisphere.
Relisten now 👇
https://www.bbc.co.uk/programmes/m002xfn8
 @tinoeberl@mastodon.online
@tinoeberl@mastodon.online2026-06-16 17:57:36
📰 Forschung kann Leben retten oder verlängern – durch Warnungen vor #Risiken und Fortschritte in #Klimaanpassung, #Energiewende und

 @Dragofix@mastodontti.fi
@Dragofix@mastodontti.fi2026-05-17 19:30:58
Lapin matkan takaa voi paljastua pentutehtailua, verta ja rikosepäilyjä – suosittujen huskysafarien taustalla muhii vakava koirakriisi https://sey.fi/huskysafarien-takana-muhii-vakava-koirakriisi/

 @DieGesellschafterinLang@swiss.social
@DieGesellschafterinLang@swiss.social2026-06-02 17:11:12
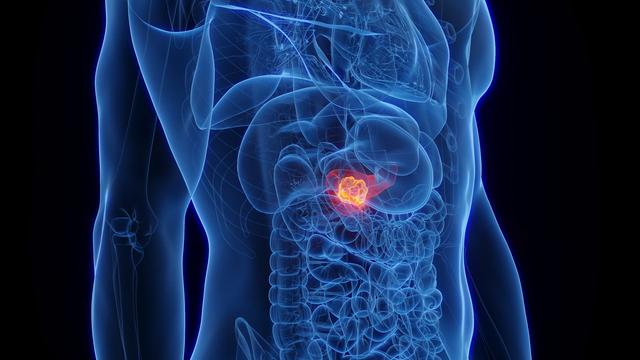
#Pankreaskarzinom - Neue Pille verdoppelt Überlebenszeit bei Bauchspeicheldrüsenkrebs
#Medizin #Krebs
 @jake4480@c.im
@jake4480@c.im2026-06-07 05:12:10
Mute Smith is a rapper from California and his stuff is very good- his EP from last month dealt with grief and loss, and this new song is kind of a chill, brief banger about sipping that tea. 🍵
https://mutesmith.bandcamp.com/track/hot-tea
 @cdarwin@c.im
@cdarwin@c.im2026-06-07 21:26:40
The primary reason Trump is going:
he wants to cause big pain for New Yorkers.
Yes, he always wants to make everything about himself,
and that's a factor,
but I still think the driving emotional impetus is his need to punish New Yorkers for not loving him.
https://
