 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2025-12-16 03:00:04
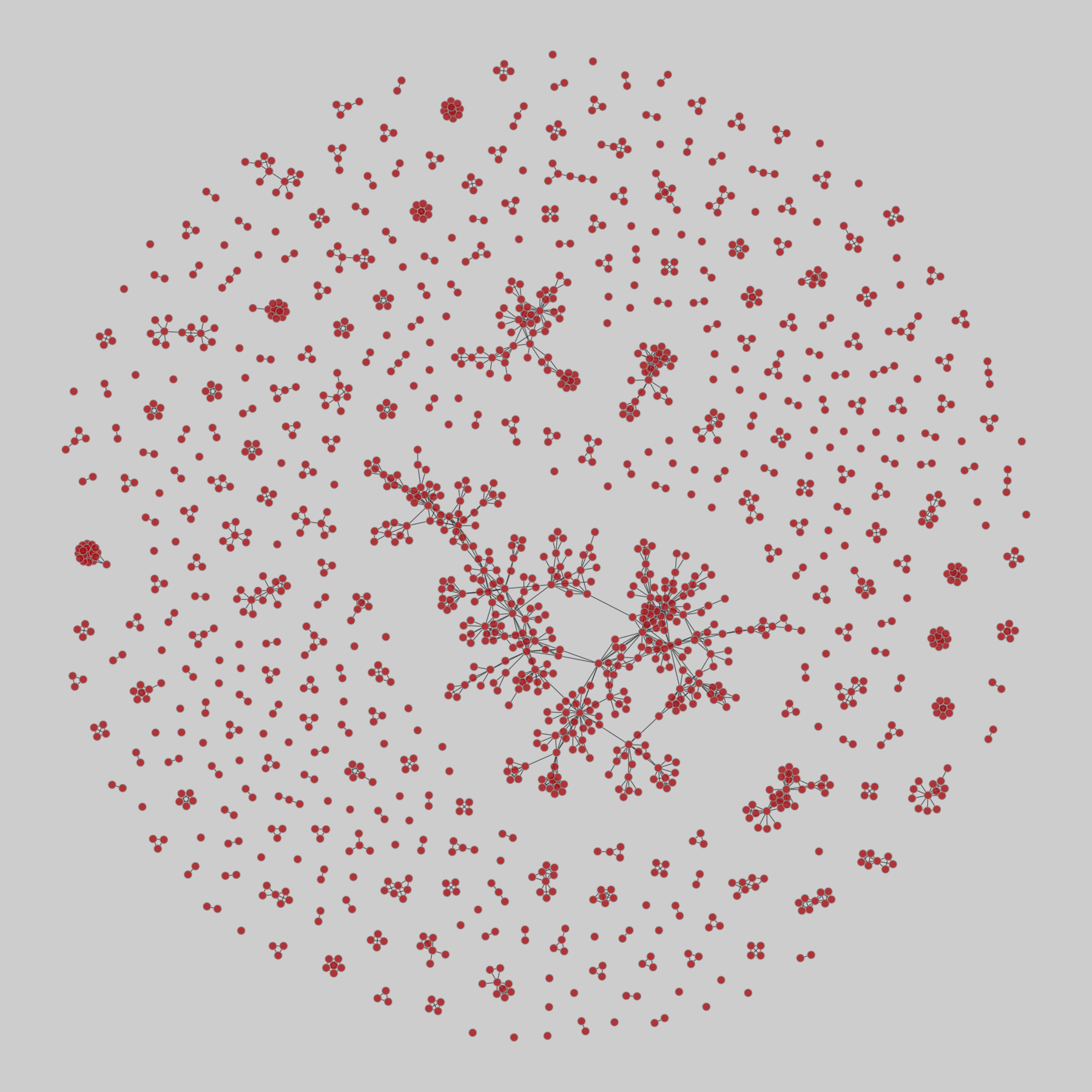
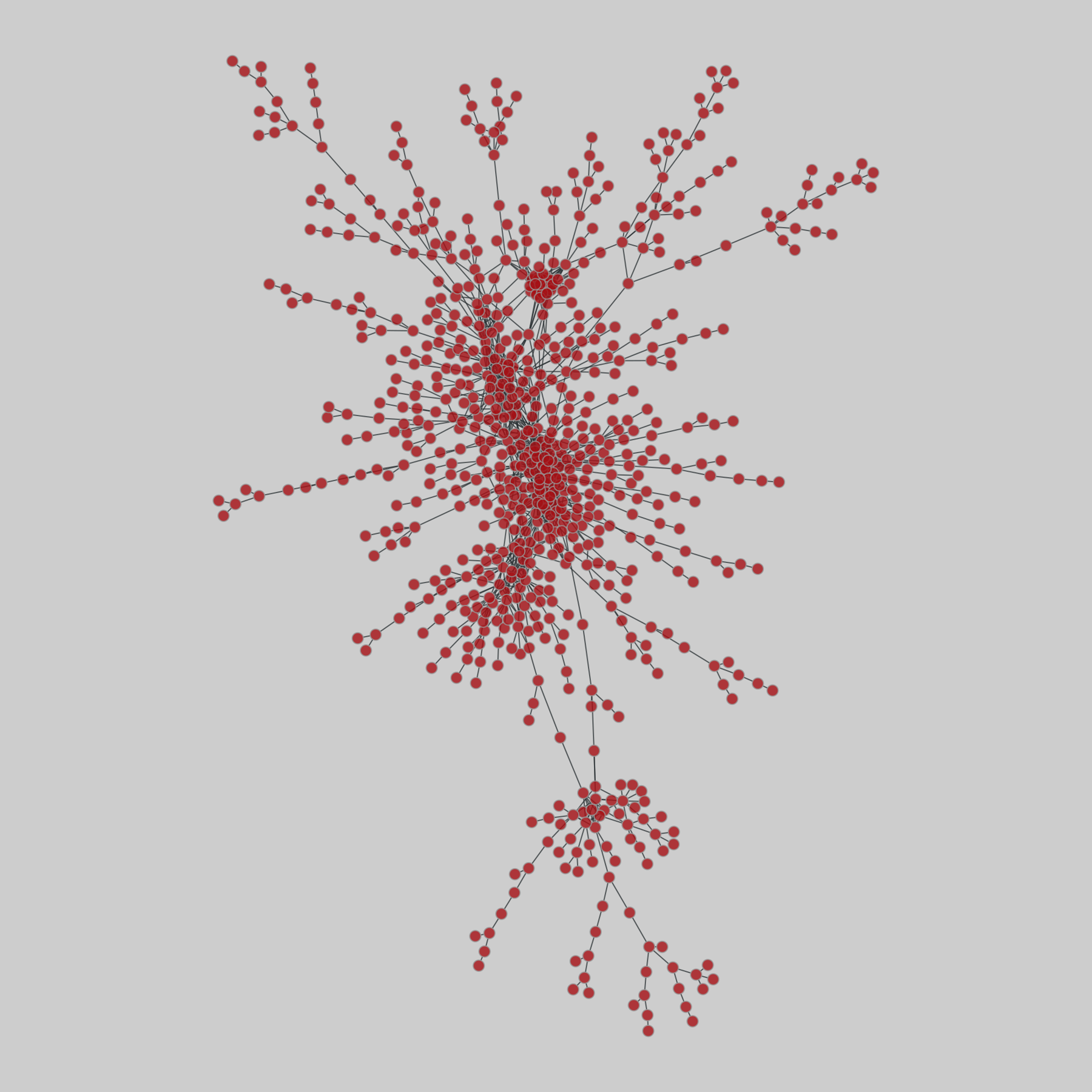
netscience: Scientific collaborations in network science (2006)
A coauthorship network among scientists working on network science, from 2006. This network is a one-mode projection from the bipartite graph of authors and their scientific publications.
This network has 1589 nodes and 2742 edges.
Tags: Social, Collaboration, Weighted, Projection
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2025-10-17 05:00:04
faculty_hiring_us: Faculty hiring networks in the US (2022)
Networks of faculty hiring for all PhD-granting US universities over the decade 2011–2020. Each node is a PhD-granting institution, and a directed edge (i,j) indicates that a person received their PhD from node i and was tenure-track faculty at node j during time of collection (2011-2020). This dataset is divided into separate networks for all 107 fields, as well as aggregate networks for 8 domains, and an overall network for …
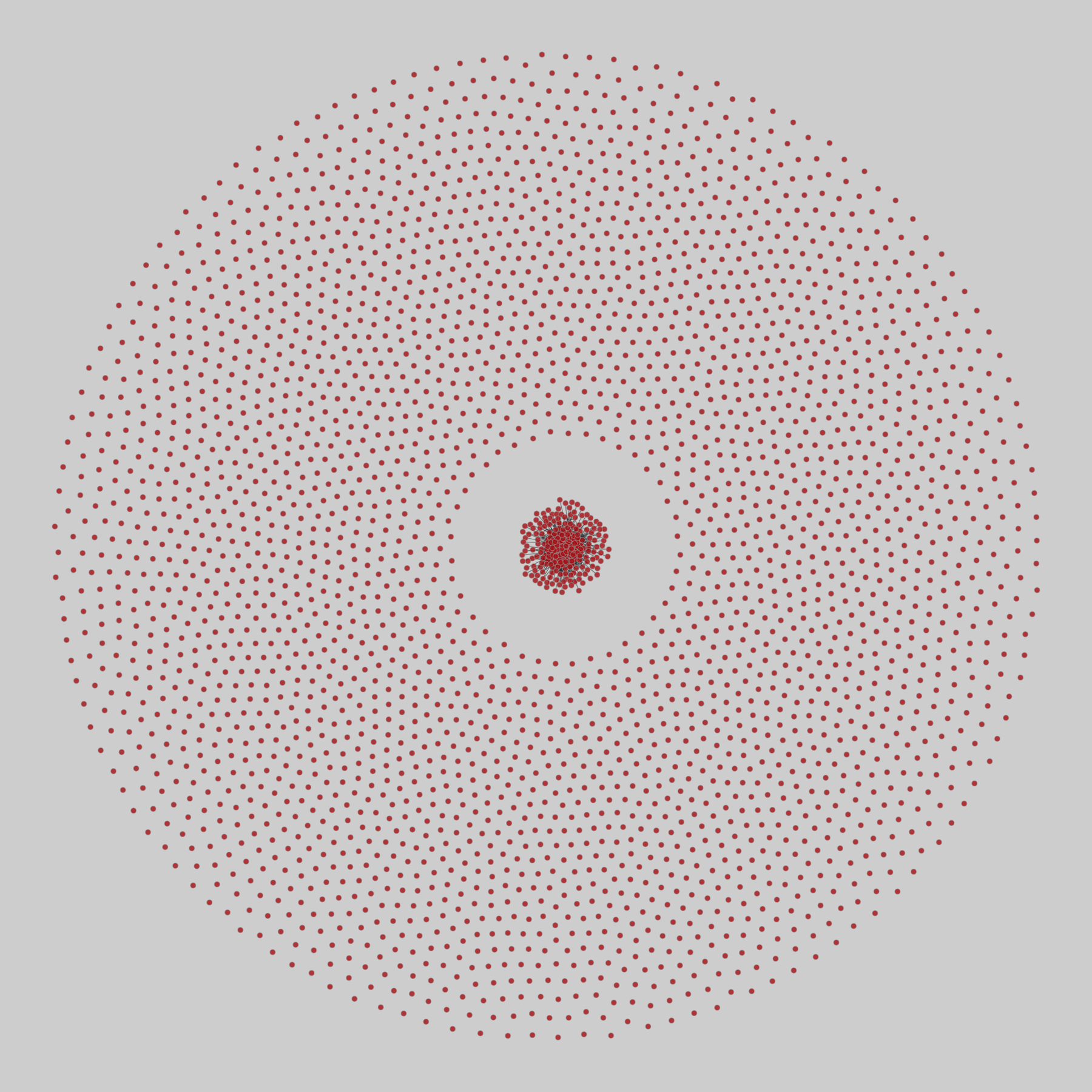 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2026-01-15 19:00:06
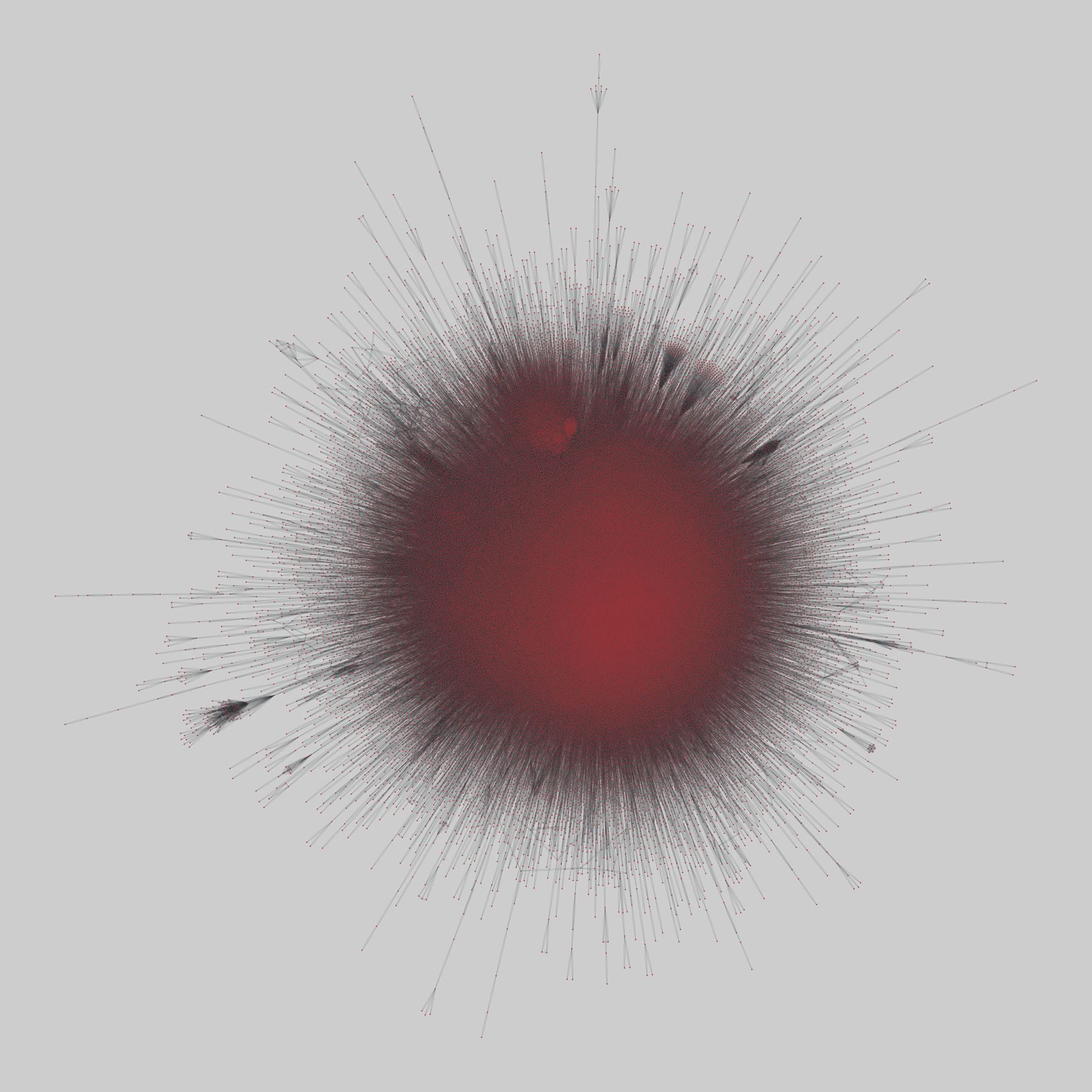
social_location: Location-based social networks
Two location-based online social networks, where nodes are accounts and edges are declared friendships. Networks includes checkins by these users.
This network has 58228 nodes and 428156 edges.
Tags: Social, Online, Spatial
https://networks.skewed…
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2026-01-16 21:00:06
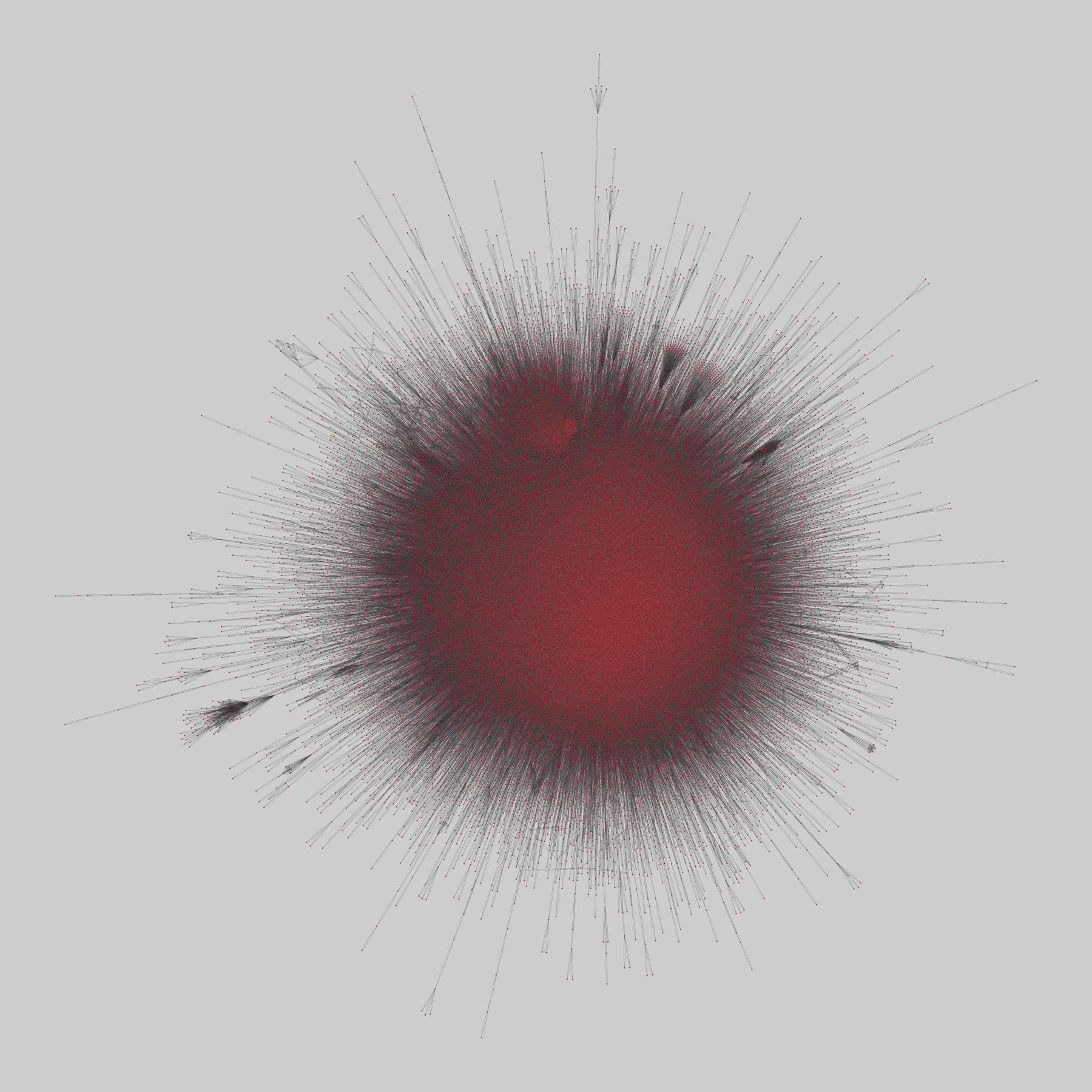
social_location: Location-based social networks
Two location-based online social networks, where nodes are accounts and edges are declared friendships. Networks includes checkins by these users.
This network has 58228 nodes and 428156 edges.
Tags: Social, Online, Spatial
https://networks.skewed…
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2025-11-16 15:00:06
social_location: Location-based social networks
Two location-based online social networks, where nodes are accounts and edges are declared friendships. Networks includes checkins by these users.
This network has 58228 nodes and 428156 edges.
Tags: Social, Online, Spatial
https://networks.skewed…
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2025-12-15 22:00:04
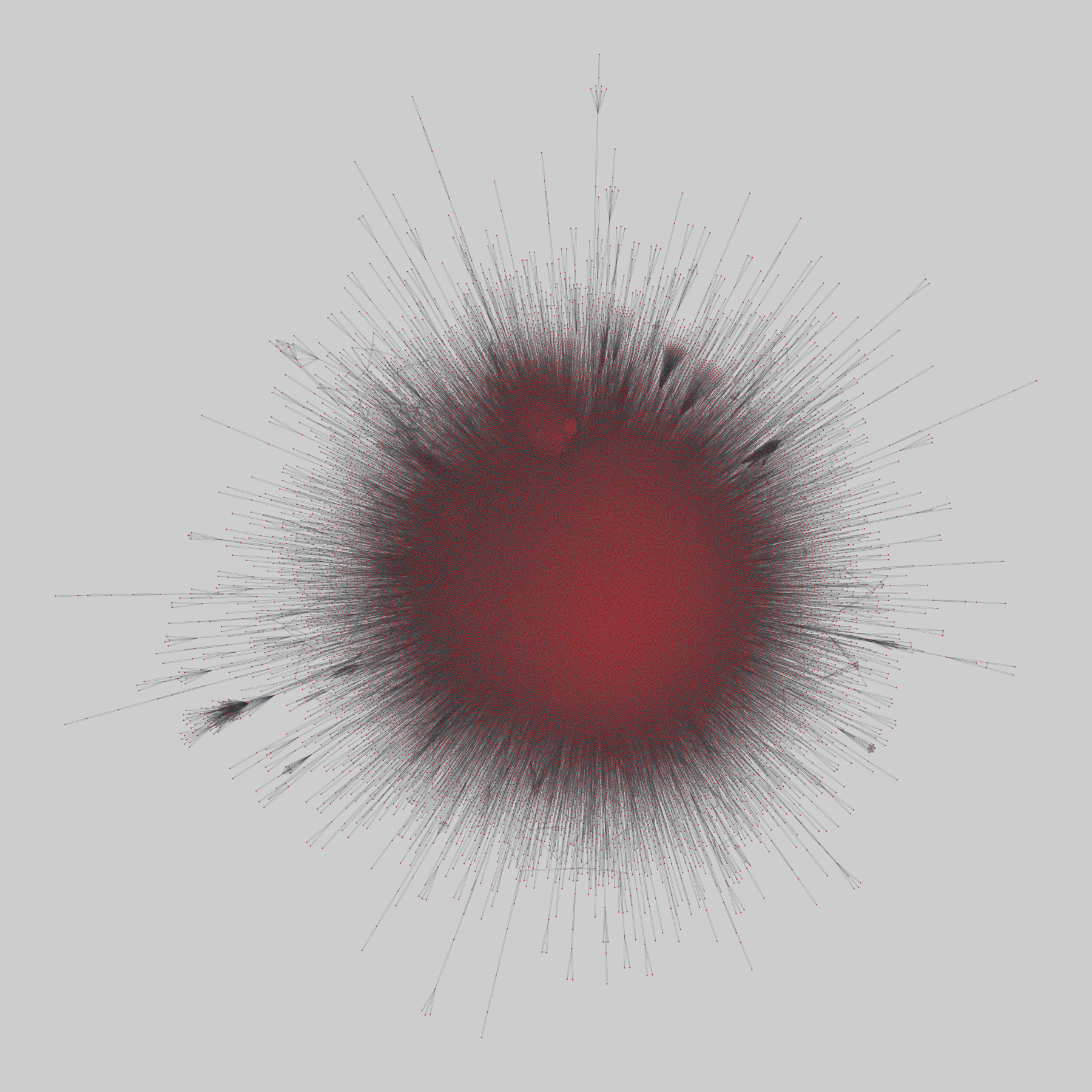
product_space: Atlas of Economic Complexity export network
Two networks of economic products, where a pair of products are connected if they are exported at similar rates by the same countries. The data are a projection from a bipartite network of nations and the products they export. Edges weights represent a similarity score (called "proximity"). Data based on UN Comtrade worldwide trade patterns. SITC network based on the Standard International Trade Classification and HS …
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2026-01-15 18:00:50
hyves: Hyves friendship network (2010)
A network of friendships among users of Hyves, an online social networking site in the Netherlands (comparable to Facebook at the time). Nodes represent users and an edge exists if two users are friends. These data were crawled in December 2010.
This network has 1402673 nodes and 2777419 edges.
Tags: Social, Online, Unweighted
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2026-01-16 15:00:49
hyves: Hyves friendship network (2010)
A network of friendships among users of Hyves, an online social networking site in the Netherlands (comparable to Facebook at the time). Nodes represent users and an edge exists if two users are friends. These data were crawled in December 2010.
This network has 1402673 nodes and 2777419 edges.
Tags: Social, Online, Unweighted
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2025-11-17 07:00:17
visualizeus: vi.sualize.us picture tagging network
Three bipartite networks of tag-picture, user-picture, and user-tag linkages that represent the folksonomy of the picture tagging network of vi.sualize.us. The date of this snapshot is uncertain.
This network has 577437 nodes and 2298816 edges.
Tags: Informational, Folksonomy, Unweighted, Multigraph
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2026-01-17 01:00:04
copenhagen: Copenhagen Networks Study
A network of social interactions among university students within the Copenhagen Networks Study, over a period of four weeks, sampled every 5 minutes. Interactions include physical proximity (undirected), phone calls (directed, weighted), text messages (directed), and information about Facebook friendships (undirected). Nodes include some metadata, including gender.
This network has 536 nodes and 3600 edges.
Tags: Social, Offline, Unwei…
