 @funkvolk@mastodon.social
@funkvolk@mastodon.social2025-11-26 19:55:27
Wenn Du dieses "Hacker-Guy schleust kurz vor knapp entscheidendes Virus in Bad-Guy-Weltzerstörungscomputer"-Feeling hast, aber an der Packstation.
https://bsky.brid.gy/r/https://bsky.app/profile/did:plc:oflombnj6v6xyohhatfkbzyd/po…

 @newsie@darktundra.xyz
@newsie@darktundra.xyz2025-11-26 14:13:19
Municipal emergency warning service offline after hackers steal user data https://therecord.media/emergency-warning-service-offline
 @heiseonline@social.heise.de
@heiseonline@social.heise.de2025-12-24 12:49:00
Bundesregierung zu Sanktionen: „was offline illegal ist, auch online illegal“
Die Regierung von US-Präsident Trump wirft „Ideologen in Europa“ Zensur vor und verhängt Einreiseverbote. Aus Deutschland kommen klare Reaktionen.
 @metacurity@infosec.exchange
@metacurity@infosec.exchange2025-12-23 11:29:24
Cyberattack knocks France's postal service and its banking arm offline
https://www.euronews.com/2025/12/22/cyberattack-knocks-frances-postal-service-and-its-banking-arm-offline

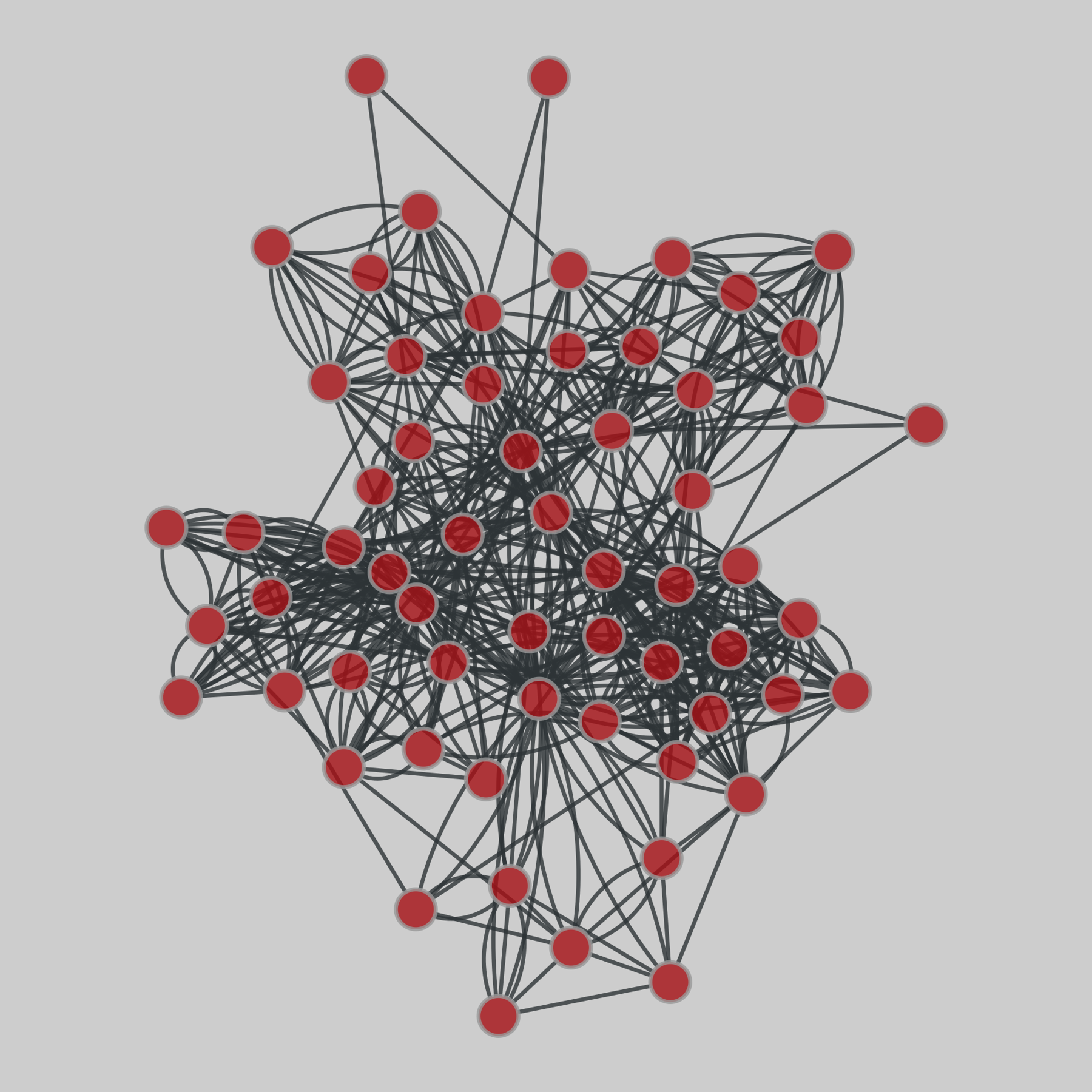
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2026-01-26 19:00:04
cs_department: Aarhus Computer Science department relationships
Multiplex network consisting of 5 edge types corresponding to online and offline relationships (Facebook, leisure, work, co-authorship, lunch) between employees of the Computer Science department at Aarhus. Data hosted by Manlio De Domenico.
This network has 61 nodes and 620 edges.
Tags: Social, Relationships, Multilayer, Unweighted
 @vosje62@mastodon.nl
@vosje62@mastodon.nl2025-12-28 00:28:27
/2
(Niet) opvallend is natuurlijk dat hoewel de uitzending al van begin december was, de frontlijn geheel gelijk is.
Alle factoren rond de oorlog komen over het voetlicht.
 @boris@cosocial.ca
@boris@cosocial.ca2026-01-26 17:30:12
I am about to fly across the country in a bit, and I think I’m going to play Last Epoch the whole way.
It’s an Action RPG that has a fully offline mode. https://lastepoch.com
 @kubikpixel@chaos.social
@kubikpixel@chaos.social2025-12-26 08:35:10
»Zu viel KI, zu wenig Substanz: wie AI Slop Wissen langfristig verändert
[…] Fast Food für Daten: schnell, billig, füllend, aber meistens eher fragwürdig […]«
Dies scheint mir noch zu wenig in der Allgemeinheit wirklich Bewusst zu sein, denn die Masse der Daten sagt noch lange nichts über deren Qualität aus. Dies ist schon lange ein Thema ua betreffend der Medien, auch offline.
🤖

 @harrysentonbury@social.linux.pizza
@harrysentonbury@social.linux.pizza2025-12-27 16:14:12
windows has the blue screen of Death.
Linux has the black oblong of Fear.
#fear
 @kexpmusicbot@mastodonapp.uk
@kexpmusicbot@mastodonapp.uk2025-12-26 17:30:04
🇺🇦 #NowPlaying on KEXP's #MorningShow
The Offline:
🎵 Dans Les Grands Espaces
#TheOffline
https://theoffline.bandcamp.com/track/dans-les-grands-espaces
https://open.spotify.com/track/3v4NeVAHBsYGzo7MMsnkx6