@seav@en.osm.town
@seav@en.osm.town2025-11-20 15:47:51
In 2021 I gave a talk about “openness” briefly tracing the history from the Free Software movement, #GNU, and OSS, to open formats like XML and ODF, then to the #FreeCulture and #OpenData movement like
 @seav@en.osm.town
@seav@en.osm.townIn 2021 I gave a talk about “openness” briefly tracing the history from the Free Software movement, #GNU, and OSS, to open formats like XML and ODF, then to the #FreeCulture and #OpenData movement like
 @gedankenstuecke@scholar.social
@gedankenstuecke@scholar.social«LLMs are copyright removal devices - copy open source (or proprietary!) data into it, and you get copyright free data on the other side that you are free to plagiarize into newly copyrighted works. While this process robs all copyright owners, it is particularly damaging to people involved in sharing communities, since many are particpating not for money but for the love of the game - what librarian Fobazi Ettarh calls “vocational awe”.»
Really good framing by @…
https://www.quippd.com/writing/2025/12/17/AIs-unpaid-debt-how-llm-scrapers-destroy-the-social-contract-of-open-source.html
 @ErikJonker@mastodon.social
@ErikJonker@mastodon.socialInteressant om door de projecten heen te browsen die funding hebben ontvangen.
https://www.openscience.nl/en/news/45-projects-strengthen-dutch-open-science-infrastructure
 @Techmeme@techhub.social
@Techmeme@techhub.socialLangChain, whose open-source framework connects AI apps to real-time data, raised a $125M Series B led by IVP at a $1.25B valuation (Sharon Goldman/Fortune)
https://fortune.com/2025/10/20/exclusive-early-ai-darling-lan…
 @NuclearDisorder@mastodon.social
@NuclearDisorder@mastodon.social @adulau@infosec.exchange
@adulau@infosec.exchangeWhy it matters to create and maintain open-source infrastructure for security monitoring including collection of forums and malicious communication channels.
This is a strong example (Google dark web report is discontinued) of the risks of relying solely on commercial vendors. If a capability does not align with their business interests or generate sufficient revenue, it can be discontinued at any time. Open-source infrastructure helps ensure continuity, transparency, and long-term ac…
 @thomasfuchs@hachyderm.io
@thomasfuchs@hachyderm.ioIt's fascinating that we largely went from a network of personal computers processing data locally that could access an open hypertext system linking together millions of websites…
…to phones with proprietary closed apps that often largely are little more than little windows to timesharing mainframes.
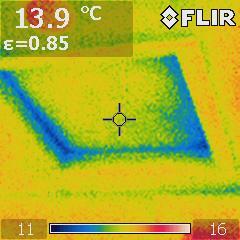 @EarthOrgUK@mastodon.energy
@EarthOrgUK@mastodon.energyOn 16WW Data Collections and Graphs - Open for research #dataset - https://www.earth.org.uk/note-on-data.html
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageGetting Your Indices in a Row: Full-Text Search for LLM Training Data for Real World
Ines Altemir Marinas, Anastasiia Kucherenko, Alexander Sternfeld, Andrei Kucharavy
https://arxiv.org/abs/2510.09471 …
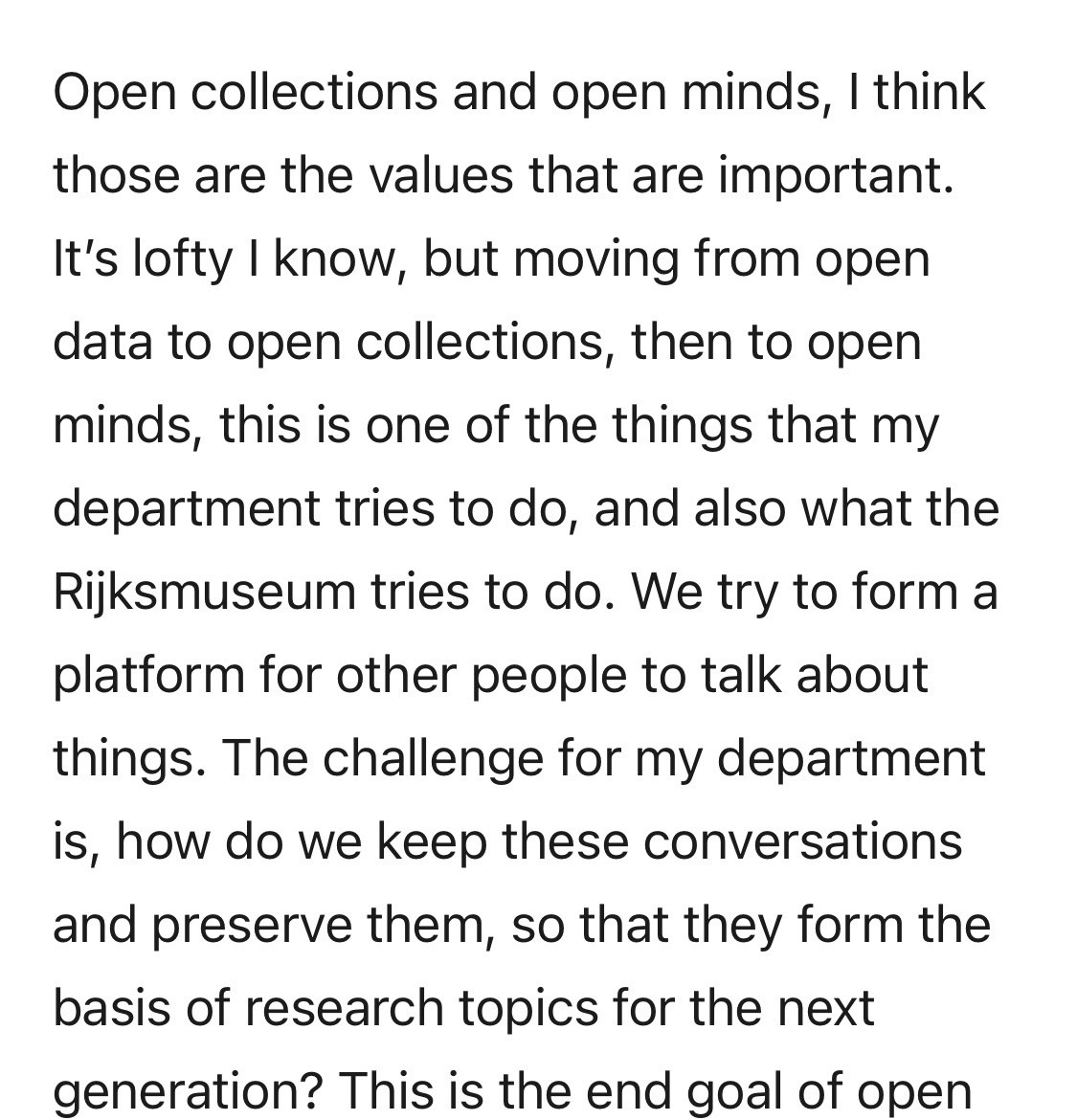
@NuclearDisorder@mastodon.socialHeute vor 50 Jahren: Am 20. Dezember 1975 testen die #USA die Atombombe "Chiberta". Die Operation Anvil war eine Serie von 21 US-amerikanischen #Kernwaffentests, die 1975 und 1976 auf der Nevada Test Site in Nevada unterirdisch durchgeführt wurde.

 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageZero Data Retention in LLM-based Enterprise AI Assistants: A Comparative Study of Market Leading Agentic AI Products
Komal Gupta, Aditya Shrivastava
https://arxiv.org/abs/2510.11558
 @prachisrivas@masto.ai
@prachisrivas@masto.ai @michabbb@social.vivaldi.net
@michabbb@social.vivaldi.net @kubikpixel@chaos.social
@kubikpixel@chaos.socialSecurity — A data breach at analytics giant Mixpanel leaves a lot of open questions
A cybersecurity incident at analytics provider Mixpanel announced just hours before the U.S. Thanksgiving holiday weekend could set a new standard for how not to announce a data breach.
📍 https://
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.pagePersonalized Federated Fine-Tuning of Vision Foundation Models for Healthcare
Adam Tupper, Christian Gagn\'e
https://arxiv.org/abs/2510.12741 https://a…
 @burger_jaap@mastodon.social
@burger_jaap@mastodon.socialNice article about the importance of connecting data, harmony without orchestration of millions of small flexible energy actions, inspired by a post of mine.
https://nemlog.substack.com/p/sustainability-will-not-be-commanded
@NuclearDisorder@mastodon.social @pre@boing.world
@pre@boing.worldThe thing about a life-logger, is you input sensitive data about your life, lifestyle and activities, so privacy and data-integrity are some of the most important issues.
There can be no server, the data has to be yours and yours alone. Because you can’t tell what is happening to the data in a closed-source app, it must be completely free and open source.
You can’t trust a corporate diary, they must sell to anyone offering enough money.
So it is with my life log app, all data completely in your own device. No home server ever sees anything.
There is no home server. Just the code.
To achieve this Exocortex Log is a Progressive Web App. It downloads when you are online at the website and can be installed onto the homepage of your phone.
It keeps all data on the local device using indexdb.
This means you must be responsible for your own backups. Be sure to export and back up your data regularly. I have gaps in my ten year record where my phone was stolen and most recent backup was months prior.
Once installed it will work offline, airplane mode, no internet, down in the tube station at midnight, anywhere.
There's a blog on the website saying this and more: https://exocortexlog.com/news/articles/2025-12-06-release/
 @metacurity@infosec.exchange
@metacurity@infosec.exchange"A Ministry of Defence official revealed confidential information by leaving a laptop open on a train in another Afghan data breach"
https://www.independent.co.uk/news/uk/home-news/afghan-ministry-of-defence-data-breach-ta…
 @nfdi4culture@nfdi.social
@nfdi4culture@nfdi.social🎼 Unser NFDI4Culture-Kollege @…, Martin Albrecht-Hohmaier präsentiert hier auf der #gfm25 die Open Educational Resource des Teams der Cultural Research Data Academy, die kürzlich auf unserem Culture Information Portal erschienen ist:

 @arXiv_csCR_bot@mastoxiv.page
@arXiv_csCR_bot@mastoxiv.pageSASER: Stego attacks on open-source LLMs
Ming Tan, Wei Li, Hu Tao, Hailong Ma, Aodi Liu, Qian Chen, Zilong Wang
https://arxiv.org/abs/2510.10486 https://ar…
@seav@en.osm.town#YouthMappers is 1️⃣0️⃣ years old! 🎉
This movement has done quite a lot in supporting the aims of #OpenStreetMap and encouraging the next generation of open geospatial data mappers and advocates over the past decade.
Here’s to ten more years! 👍
@NuclearDisorder@mastodon.social @gwire@mastodon.social
@gwire@mastodon.social> Cambridge’s preservationists don’t just mount disks and hope for the best; they sample the raw magnetic signal itself. Specialized hardware, such as the KryoFlux and open-hardware Greaseweazle interfaces, captures the flux transitions — the tiny changes in polarity that encode data — and reconstructs the file structure later in software.
@ErikJonker@mastodon.social"EU-US Data Transfers: Time to prepare for more trouble to come", #maxschrems…
@Techmeme@techhub.socialAnthropic open sources a method to score AI model political evenhandedness; Gemini 2.5 Pro got 97%, Grok 4 96%, Claude Opus 4.1 95%, GPT-5 89%, and Llama 4 66% (Ina Fried/Axios)
https://www.axios.com/2025/11/13/anthropic-bot-bias-data
 @rperezrosario@mastodon.social
@rperezrosario@mastodon.socialAI model builder Eric Hartford unpacks the results of the September 25, 2025 NIST report on DeepSeek ("Evaluation of DeepSeek AI Models") and reports that the lack of evidence of malicious code, backdoors or data exfiltration, should lead to questions about the report's motives, framing and implications.
"The Demonization of DeepSeek -
How NIST Turned Open Science into a Security Scare"

 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.pageChronologically Consistent Generative AI
Songrun He, Linying Lv, Asaf Manela, Jimmy Wu
https://arxiv.org/abs/2510.11677 https://arxiv.org/pdf/2510.11677
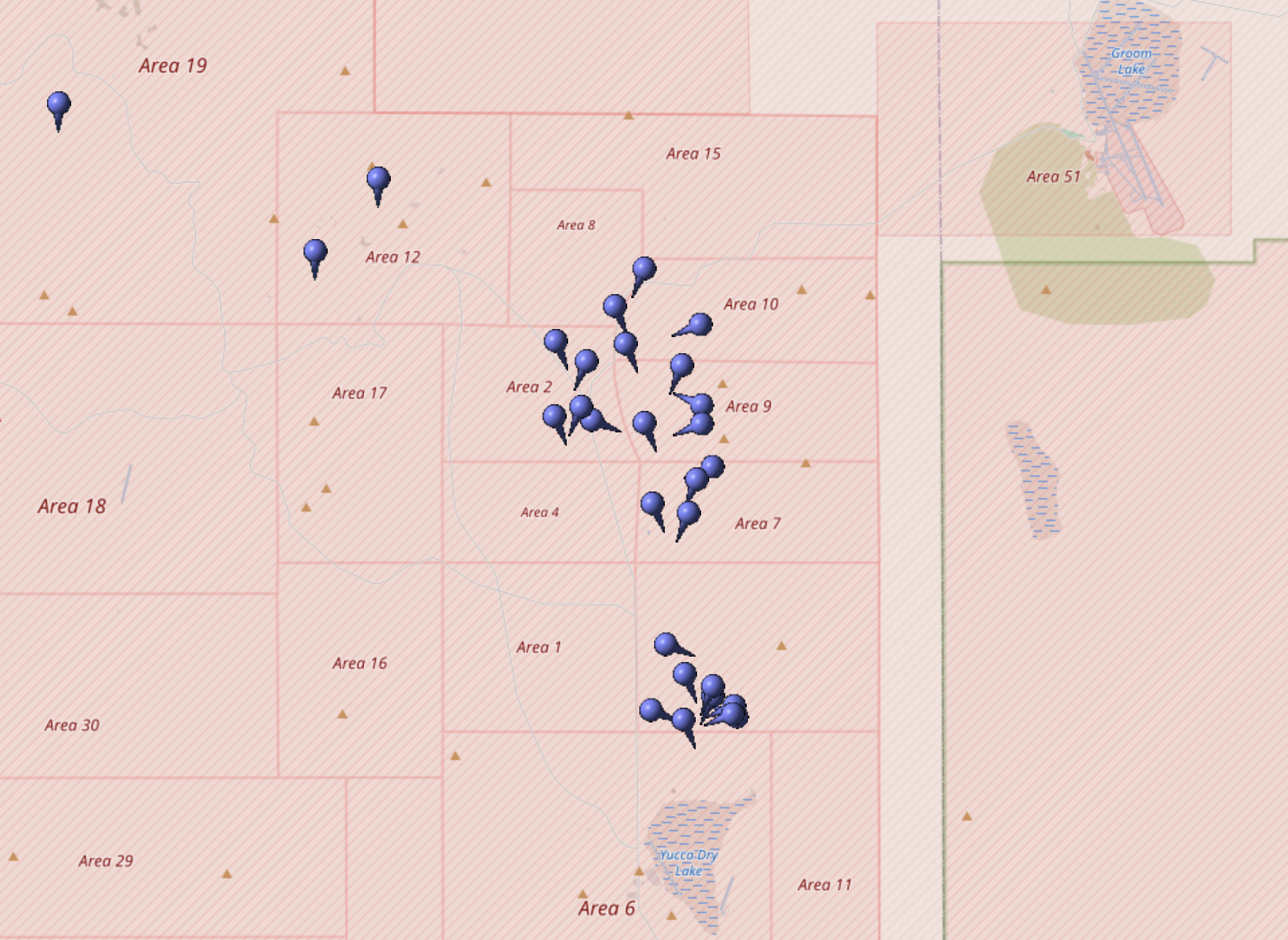
@NuclearDisorder@mastodon.socialHeute vor 50 Jahren: Am 20. November 1975 testen die #USA die Atombombe "Inlet". Die Operation Anvil war eine Serie von 21 US-amerikanischen #Kernwaffentests, die 1975 und 1976 auf der Nevada Test Site in Nevada unterirdisch durchgeführt wurde.

 @arXiv_csAR_bot@mastoxiv.page
@arXiv_csAR_bot@mastoxiv.pageFeNOMS: Enhancing Open Modification Spectral Library Search with In-Storage Processing on Ferroelectric NAND (FeNAND) Flash
Sumukh Pinge, Ashkan Moradifirouzabadi, Keming Fan, Prasanna Venkatesan Ravindran, Tanvir H. Pantha, Po-Kai Hsu, Zheyu Li, Weihong Xu, Zihan Xia, Flavio Ponzina, Winston Chern, Taeyoung Song, Priyankka Ravikumar, Mengkun Tian, Lance Fernandes, Huy Tran, Hari Jayasankar, Hang Chen, Chinsung Park, Amrit Garlapati, Kijoon Kim, Jongho Woo, Suhwan Lim, Kwangsoo Kim, Wa…
 @newsie@darktundra.xyz
@newsie@darktundra.xyzData Hoarder Uses AI to Create Searchable Database of Epstein Files https://www.404media.co/data-hoarder-uses-ai-to-create-searchable-database-of-epstein-files/
 @arXiv_eessSY_bot@mastoxiv.page
@arXiv_eessSY_bot@mastoxiv.pagePowerPlots: An Open Source Power Grid Visualization and Data Analysis Framework for Academic Research
Noah Rhodes
https://arxiv.org/abs/2510.05063 https://…
 @daniel@social.telemetrydeck.com
@daniel@social.telemetrydeck.comI do, in fact, not have time for a 15 minute call, so I've drafted a form letter that I'll try and send to every single one of these emails starting now.
 @EarthOrgUK@mastodon.energy
@EarthOrgUK@mastodon.energyOn 16WW Data Collections and Graphs - Open for research #dataset - https://www.earth.org.uk/note-on-data.html
 @arXiv_physicsfludyn_bot@mastoxiv.page
@arXiv_physicsfludyn_bot@mastoxiv.pageA framework for realisable data-driven active flow control using model predictive control applied to a simplified truck wake
Alberto Solera-Rico, Carlos Sanmiguel Vila, Stefano Discetti
https://arxiv.org/abs/2510.11600
 @chris@mstdn.chrisalemany.ca
@chris@mstdn.chrisalemany.caPleasantly Surprised!!
"Cryptocurrency mining – another sector with large electricity demands – would be banned.”
Unfortunately unsurprised:
"starting next year, the province will open up bidding for artificial intelligence and data centres that will be capped at a total of 400 megawatts of power over a two-year period. Prices will be set by regulation.”
#BCPoli #Energy #Electricity #AI #bubble
https://archive.ph/TJ6sy#selection-2589.0-2589.88
@NuclearDisorder@mastodon.socialHeute vor 56 Jahren: Am 20. September 1969 testen die #USA simultan die Atombomben "Kyack-1" u. "Kyack-2". Operation Mandrel war eine Serie von 53 US-amerikanischen #Kernwaffentests, die 1969/70 hauptsächlich auf der Nevada Test Site in Nevada unterirdisch durchgeführt wurde.…
 @berlinbuzzwords@floss.social
@berlinbuzzwords@floss.socialPlanning ahead for 2026? Ensure Berlin Buzzwords is on your schedule for June 7th–9th.
Berlin Buzzwords is Europe’s leading conference for modern data infrastructure, search and machine learning and is focused on open source software projects.
Get your Trust Us Ticket now and save 36% off the regular price: 🔗 https://tickets.plainschwarz.com/bbuzz26/c/8Hvk0ZvJA/
Learn more about Berlin Buzzwords: 🔗https://2026.berlinbuzzwords.de/

 @arXiv_csDL_bot@mastoxiv.page
@arXiv_csDL_bot@mastoxiv.pageThe QIC-Index: A Novel, Data-Centric Metric for Quantifying the Impact of Research Data Sharing
Martin G. Frasch
https://arxiv.org/abs/2510.03307 https://a…
 @primonatura@mstdn.social
@primonatura@mstdn.social"Sweden’s Stegra to supply green steel for Microsoft’s data centers"
#Sweden #Microsoft
https://www.
 @arXiv_statML_bot@mastoxiv.page
@arXiv_statML_bot@mastoxiv.pageUniversal Adaptive Environment Discovery
Madi Matymov, Ba-Hien Tran, Maurizio Filippone
https://arxiv.org/abs/2510.12547 https://arxiv.org/pdf/2510.12547…
@arXiv_csCL_bot@mastoxiv.pageKORMo: Korean Open Reasoning Model for Everyone
Minjun Kim, Hyeonseok Lim, Hangyeol Yoo, Inho Won, Seungwoo Song, Minkyung Cho, Junhun Yuk, Changsu Choi, Dongjae Shin, Huige Lee, Hoyun Song, Alice Oh, Kyungtae Lim
https://arxiv.org/abs/2510.09426
 @JSkier@social.linux.pizza
@JSkier@social.linux.pizzaNothing like marketing a product 'free' from the OPM #breach years ago. That kind of breach is going to haunt me for a lifetime, but the same people who lost my data decided 10 years of open-sourced commercialized OSINT should cover it 🥴 It took multiple FOIA requests before they even sent me a 70% redacted version of the data they lost 🤦♂️
I feel bad for the folks who don't…

 @almad@fosstodon.org
@almad@fosstodon.orgMost probable prediction about OpenAI future I’ve read.
Spoiler: it will be successful and we will not like it.
https://open.substack.com/pub/defragzone/p/welcome-to-cognitive-capitalism
 @arXiv_csSE_bot@mastoxiv.page
@arXiv_csSE_bot@mastoxiv.pageBuilding an Open AIBOM Standard in the Wild
Gopi Krishnan Rajbahadur, Keheliya Gallaba, Elyas Rashno, Arthit Suriyawongkul, Karen Bennet, Kate Stewart, Ahmed E. Hassan
https://arxiv.org/abs/2510.07070 …
@Techmeme@techhub.socialPolars, the Amsterdam-based startup behind the popular open-source library for data manipulation of the same name, raised a €18M Series A led by Accel (Anna Heim/TechCrunch)
https://techcrunch.com/2025/09/29/the-startup-behind-open-source-t…
 @arXiv_astrophGA_bot@mastoxiv.page
@arXiv_astrophGA_bot@mastoxiv.pageRefining open cluster parameters with Gaia XP metallicities
M. Nizovkina, S. S. Larsen, A. G. A. Brown, A. Helmi
https://arxiv.org/abs/2510.10385 https://a…
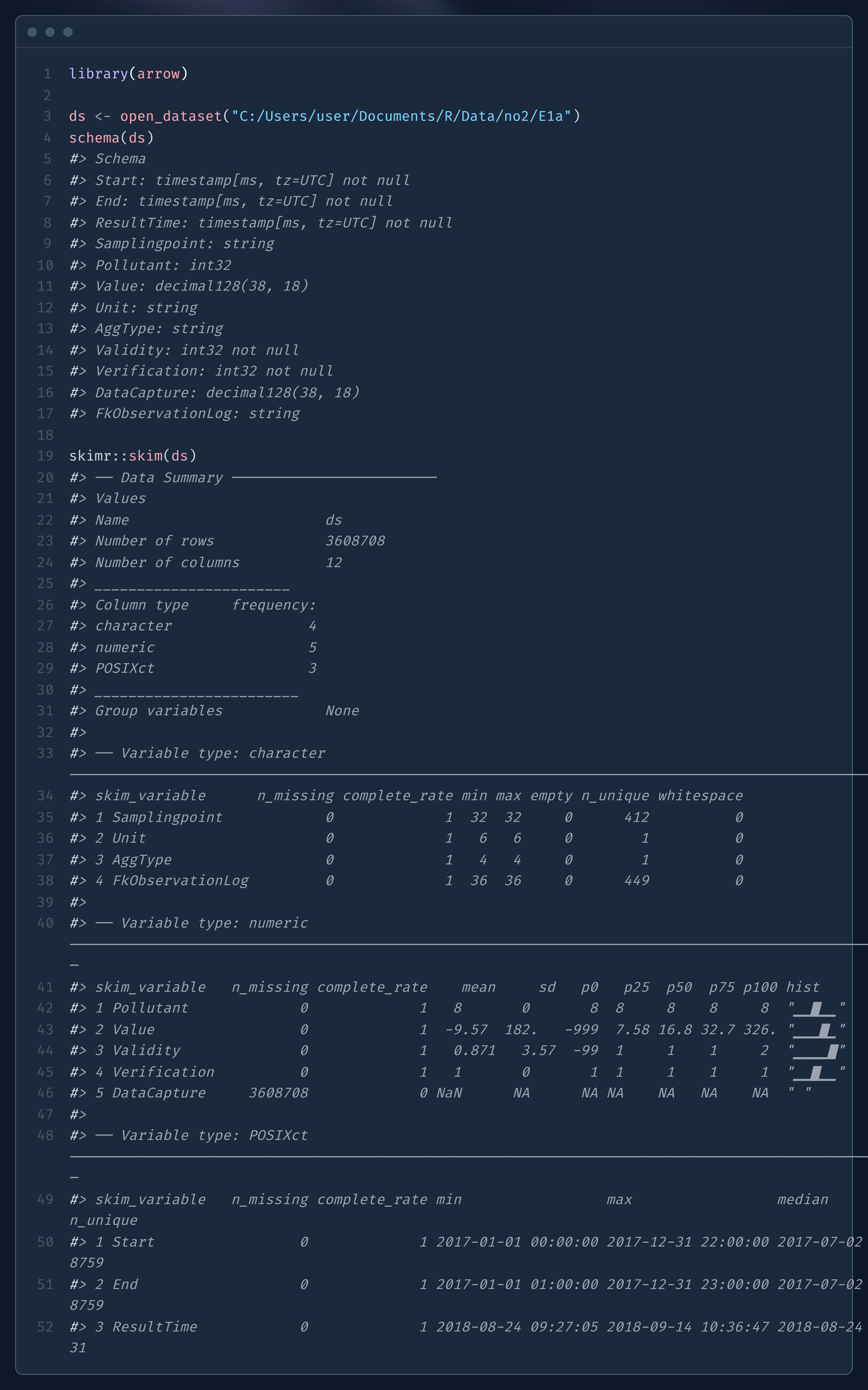
 @erc_bk@fosstodon.org
@erc_bk@fosstodon.orgDidn't know that {skimr::skim} worked an arrow object. It's pretty cool, but it hits your RAM pretty hard. That's only a 70MB directory of parquet files, and my RAM usage went up by ~1.3GB. #RStats Code: https://ray.so/fCoXwso
 @grumpybozo@toad.social
@grumpybozo@toad.socialOr one could use LibreOffice or Apache OpenOffice and not be dependent on some distant service provider.
Online office suites confuse me. It’s unclear what *modern* problem they address. Sharing files is a solved problem. Common data formats exist. https://mastodon.social/@DevOpsPink/11
@gedankenstuecke@scholar.socialIt's so depressing how orgs like #Mozilla squander volunteer goodwill for nothing. They'll never recover from this self-inflicted damage:
«Mozilla’s translation bot on Support Mozilla (that is currently overwriting user contributions is based on the closed source, copyright infringing LLM, Google Gemini. This is in spite of Mozilla claiming that they are at the forefront of open source AI, and belies their exhortations to choose to build open source AI and data sets»
https://www.quippd.com/writing/2025/12/08/mozillas-betrayal-of-open-source-googles-gemini-ai-is-overwriting-volunteer-work-on-support-mozilla.html
 @KlausBulle@nfdi.social
@KlausBulle@nfdi.social„Open collections and open minds, I think those are the values that are important.“ - @…
Auf dem Weg zur #forge2025 in Rostock, die heute mit dem Workshop „Sammlungen als #Forschungsdaten
 @arXiv_mathOC_bot@mastoxiv.page
@arXiv_mathOC_bot@mastoxiv.pageFragility Analysis of Data-Driven Feedback Gains
Yongzhang Li, Amir Shakouri, M. Kanat Camlibel
https://arxiv.org/abs/2510.00717 https://arxiv.org/pdf/2510…
 @geant@mstdn.social
@geant@mstdn.social📣 The call for nominations for the Sarah Jones Award 2026 is now open!
What is it?
‘The Sarah Jones Award for exceptional contribution to fostering collaboration in #OpenScience’ was established by the Research Data Alliance (RDA) in June 2024. This bi-annual award honours the memory of our dear colleague Sarah Jones, and her significant contributions to the global open science commu…

 @trezzer@social.linux.pizza
@trezzer@social.linux.pizzaUgh. I just finished moving 1.7TB of data from Google to Filen using Filen’s rclone fork. Some of it went fine, but a few files I tried to open failed to do so. Now I doubt the integrity of every file.
@kubikpixel@chaos.socialSync-in · The open-source platform that keeps your data safe
Sync-in is your open-source platform to store, share, collaborate, and sync your files. Manage your data, freely, privately and with no compromise.
📑 https://sync-in.com
:mastodon: @…
@EarthOrgUK@mastodon.energyOn 16WW Data Collections and Graphs - Open for research #dataset - https://www.earth.org.uk/note-on-data.html
@arXiv_csLG_bot@mastoxiv.pageRate optimal learning of equilibria from data
Till Freihaut, Luca Viano, Emanuele Nevali, Volkan Cevher, Matthieu Geist, Giorgia Ramponi
https://arxiv.org/abs/2510.09325 https:/…
@Techmeme@techhub.socialIntel unveils Crescent Island, a data center GPU designed for AI inference workloads, featuring Intel's Xe3P microarchitecture and 160GB of LPDDR5X memory (Dylan Martin/CRN)
https://www.crn.com/news/components-periph
@NuclearDisorder@mastodon.social @metacurity@infosec.exchangeDon't be scared, but today's Metacurity is super-packed with frightening cyber developments you should know before you head out to trick and treat, including
--Google and Amazon used secret code to dodge data disclosure laws, investigation,
--Suspected Conti member extradited to US from Ukraine,
--FCC will vote to eliminate cyber reporting requirements for carriers,
--UNC6384 targeted Hungarian and Belgian diplomatic entities,
--Medusa creators reportedl…
@arXiv_csCV_bot@mastoxiv.pageGeoPurify: A Data-Efficient Geometric Distillation Framework for Open-Vocabulary 3D Segmentation
Weijia Dou, Xu Zhang, Yi Bin, Jian Liu, Bo Peng, Guoqing Wang, Yang Yang, Heng Tao Shen
https://arxiv.org/abs/2510.02186
@arXiv_csCL_bot@mastoxiv.pageOpenJAI-v1.0: An Open Thai Large Language Model
Pontakorn Trakuekul, Attapol T. Rutherford, Jullajak Karnjanaekarin, Narongkorn Panitsrisit, Sumana Sumanakul
https://arxiv.org/abs/2510.06847
@Techmeme@techhub.socialStarcloud, which launched a satellite with a Nvidia H100 chip in November, says the satellite is running and querying responses from Google's Gemma (Pia Singh/CNBC)
https://www.cnbc.com/2025/12/10/nvidia-backed-starcloud-tr…
@arXiv_statML_bot@mastoxiv.pagetorchsom: The Reference PyTorch Library for Self-Organizing Maps
Louis Berthier, Ahmed Shokry, Maxime Moreaud, Guillaume Ramelet, Eric Moulines
https://arxiv.org/abs/2510.11147 …
@EarthOrgUK@mastodon.energyOn 16WW Data Collections and Graphs - Open for research #dataset - https://www.earth.org.uk/note-on-data.html
@adulau@infosec.exchangeWe are pleased to announce the release of CTI-Transmute.org, a new free and open-source service designed to facilitate conversions between MISP and STIX 2.x formats.
The service is available both through a web interface and an API, allowing users to convert CTI data easily. The web UI also gives users the option to share or keep private their conversions for further review or collaboration.
You can view an example conversion here: 🔗
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageUnveiling Interesting Insights: Monte Carlo Tree Search for Knowledge Discovery
Pietro Totis, Alberto Pozanco, Daniel Borrajo
https://arxiv.org/abs/2510.00876 https://
@kubikpixel@chaos.socialBandwagon.fm — Better Social for Musicians. Connect to Your Fans on the Fediverse
Bandwagon is 100% open source, so nobody can lock you in to their platform. Start here, then you'll be able to migrate your account or self-host your Bandwagon data anywhere.
🎶 https://bandwagon.fm
@gedankenstuecke@scholar.socialJust made the PR to sign @…'s open letter for a community fork from #Rails, to get away from fascist DHH.
I'm not really using Rails any longer, so I don't know that my voice carries any weight here. But, for 14 years we ran openSNP on Rails, providing the world with an open data/science resource. And the rise of the far-right authoritarianism played a big role in the decision to shut it down (see #ruby
@Techmeme@techhub.socialAn investor group and AI developer Voltai plan to use AI to design, build, and run a 3GW data center in South Korea, set to cost up to $35B and open in 2028 (Jiyoung Sohn/Wall Street Journal)
https://www.wsj.com/tech/a-…
@arXiv_csLG_bot@mastoxiv.pageCounterfactual Identifiability via Dynamic Optimal Transport
Fabio De Sousa Ribeiro, Ainkaran Santhirasekaram, Ben Glocker
https://arxiv.org/abs/2510.08294 https://
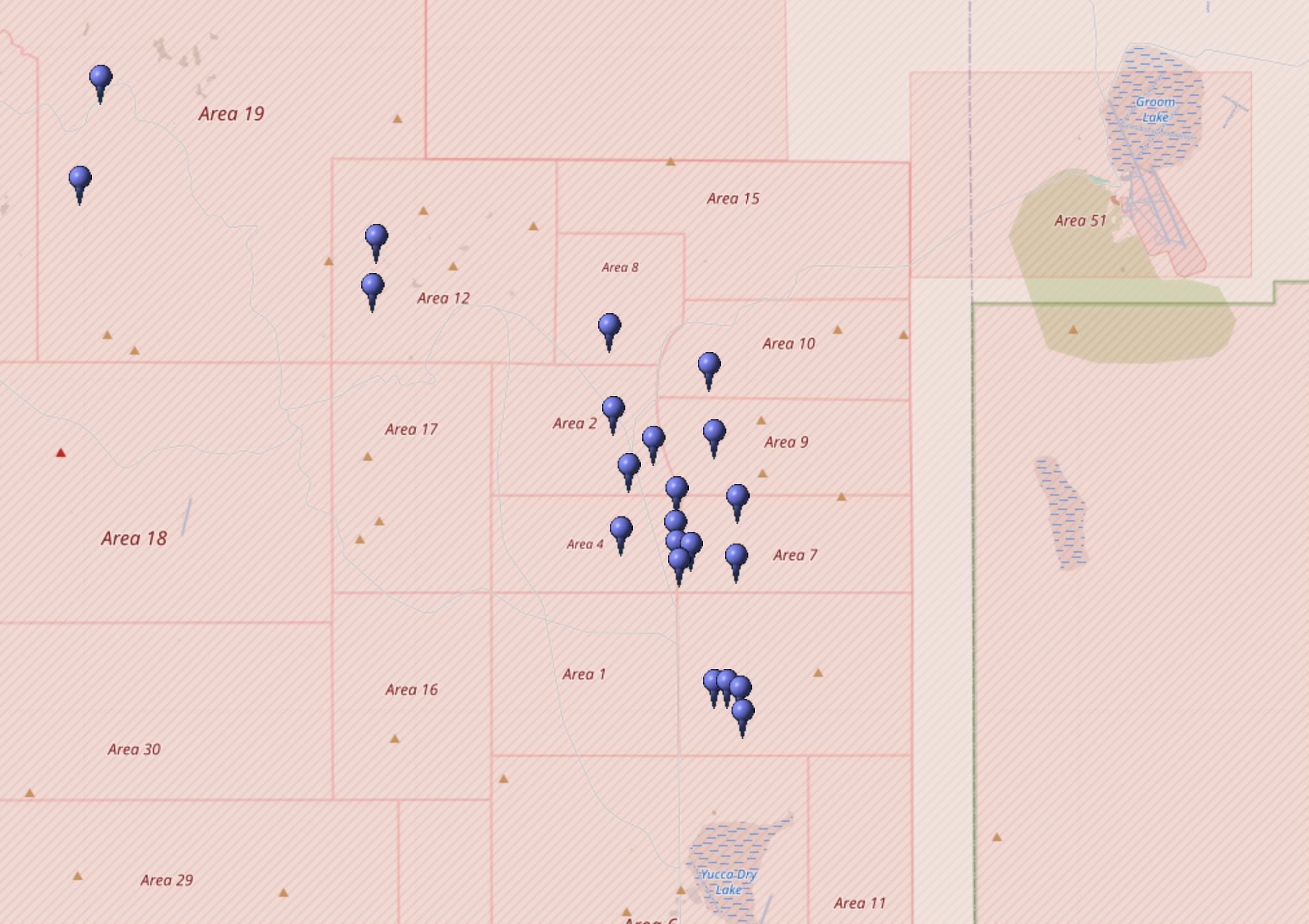
@NuclearDisorder@mastodon.socialHeute vor 53 Jahren: Am 17.11.1972 zündeten die USA im Rahmen von Operation Toggle die Atombomben "Canna Limoges" u. "Umbrinus". Toggle war eine Serie von #Kernwaffentests bei der 72/73 35 Bomben größtenteils im Testgebiet in #Nevada und Rio Blanco unterirdisch gezündet wu…
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.pageFSP-DETR: Few-Shot Prototypical Parasitic Ova Detection
Shubham Trehan, Udhav Ramachandran, Akash Rao, Ruth Scimeca, Sathyanarayanan N. Aakur
https://arxiv.org/abs/2510.09583 ht…
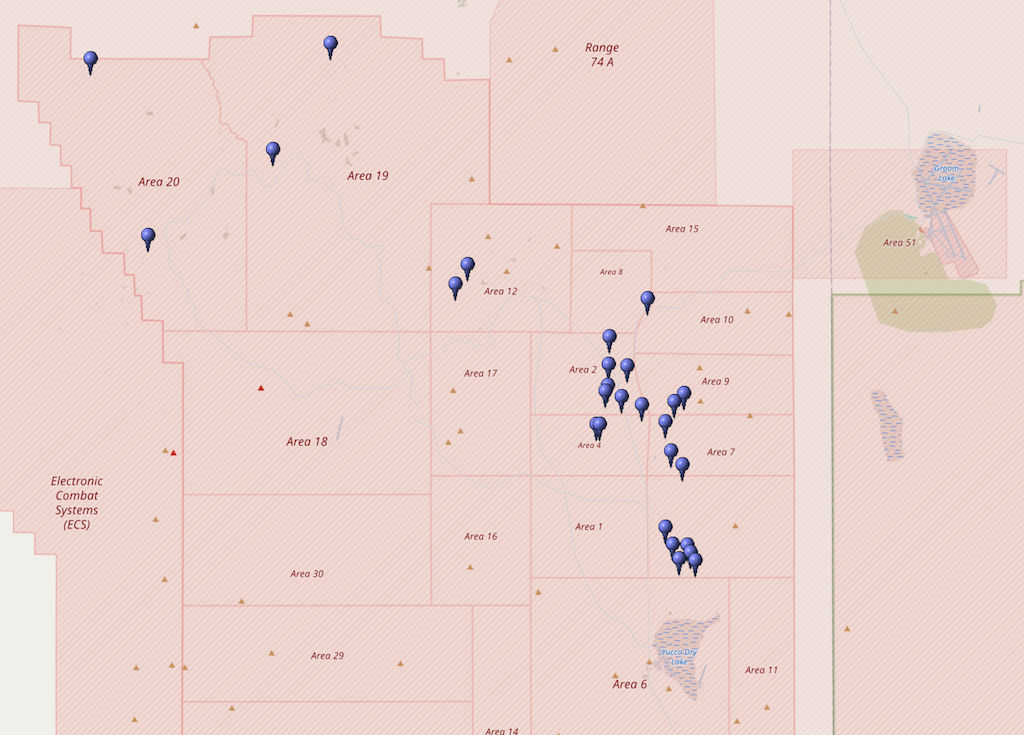
@NuclearDisorder@mastodon.socialHeute vor 48 Jahren: Am 17.11.1977 zündeten die #USA im Rahmen von Operation Cresset die 4. Atombombe "Seamount". Cresset war eine Serie von #Kernwaffentests bei der 1977/78 insgesamt 23 Bomben im Testgebiet in
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageF2LLM Technical Report: Matching SOTA Embedding Performance with 6 Million Open-Source Data
Ziyin Zhang, Zihan Liao, Hang Yu, Peng Di, Rui Wang
https://arxiv.org/abs/2510.02294 …
@NuclearDisorder@mastodon.socialHeute vor 4 Jahren: Am 18. Dezember 2021 führte #Indien vor der Küste von Odisha in Balasore erfolgreich den zweiten Test seiner Agni-P durch, einer ballistischen #Mittelstreckenrakete mit nuklearer Fähigkeit.
 @EarthOrgUK@mastodon.energy
@EarthOrgUK@mastodon.energyOn 16WW Data Collections and Graphs - Open for research #dataset - https://www.earth.org.uk/note-on-data.html
@NuclearDisorder@mastodon.socialHeute vor 51 Jahren: Am 17. Oktober 1974 testen die #USA die Atombombe "Estaca". Die Operation Bedrock war eine Serie von 27 US-amerikanischen #Kernwaffentests, die 1974/75 auf der Nevada Test Site in Nevada unterirdisch durchgeführt wurde.
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageScaling Generalist Data-Analytic Agents
Shuofei Qiao, Yanqiu Zhao, Zhisong Qiu, Xiaobin Wang, Jintian Zhang, Zhao Bin, Ningyu Zhang, Yong Jiang, Pengjun Xie, Fei Huang, Huajun Chen
https://arxiv.org/abs/2509.25084
@NuclearDisorder@mastodon.socialHeute vor 62 Jahren: Am 17. Oktober 1963 zündeten die USA im Rahmen von #Niblick die 11. #Atombombe "Clearwater". Niblick war eine Serie von Tests zwischen 63/64 bei der insgesamt 41 #Kernwaffentests
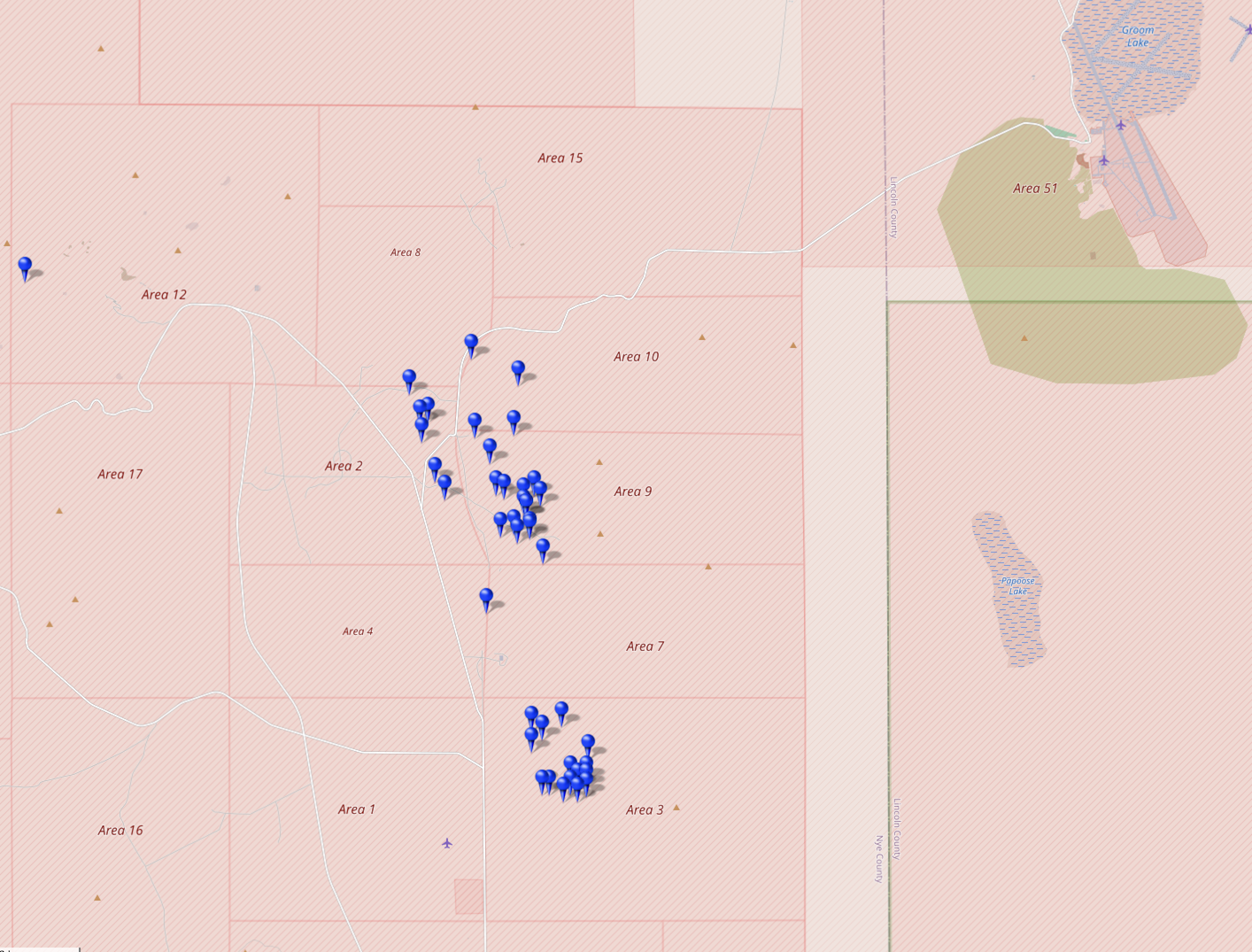 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageWho are you, ChatGPT? Personality and Demographic Style in LLM-Generated Content
Dana Sotto Porat, Ella Rabinovich
https://arxiv.org/abs/2510.11434 https://
@NuclearDisorder@mastodon.socialHeute vor 55 Jahren: Am 16.12.1970 kam es simultan zu 4 #Atomtests "Avens-Andorre/Alkermes/Asamite/Cream". Die Operation #Emery war eine US-Serie von 24 Tests zwischen 1970/71. Sie wurden auf dem Nevada Test Site (NST) unterirdisch durchgeführt und dienten der Waffenentwicklung.
 @NuclearDisorder@mastodon.social @NuclearDisorder@mastodon.social
@NuclearDisorder@mastodon.social @NuclearDisorder@mastodon.socialHeute vor 47 Jahren: Am 16.12.1978 zündeten die #USA im Rahmen von Operation Quicksilver die 3. Atombombe "Farm". Quicksilver war eine Serie von #Kernwaffentests bei der 1978/79 insgesamt 16 Bomben im Testgebiet in
 @Techmeme@techhub.social
@Techmeme@techhub.socialOpenAI, Oracle, and Vantage Data Centers plan to build a data center in Wisconsin called Lighthouse, costing $15B and set to open in 2028, as part of Stargate (Juby Babu/Reuters)
https://www.reuters.com/business/openai-oracle-announce-…
@NuclearDisorder@mastodon.socialHeute vor 62 Jahren: Am 16. Oktober 1963 zündeten die USA im Rahmen von #Niblick die 11. #Atombombe "Clearwater". Niblick war eine Serie von Tests zwischen 63/64 bei der insgesamt 41 #Kernwaffentests
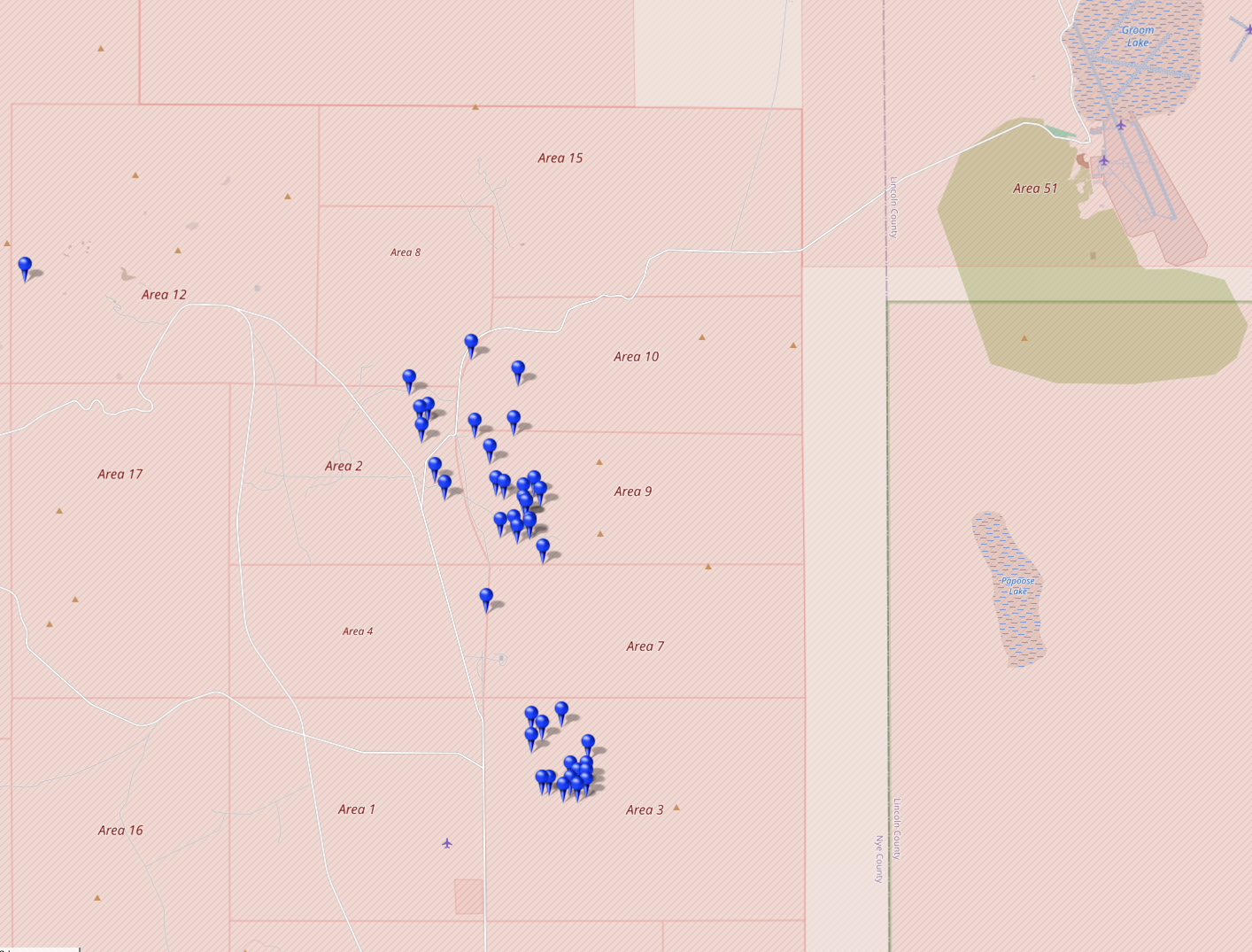 @NuclearDisorder@mastodon.social
@NuclearDisorder@mastodon.socialHeute vor 39 Jahren: Am 16.10.1986 zündeten die #USA im Rahmen von Operation Musketeer die Atombombe "Belmont". Musketeer war eine Serie von #Kernwaffentests bei der 1986/87 insgesamt 16 Bomben im Testgebiet in
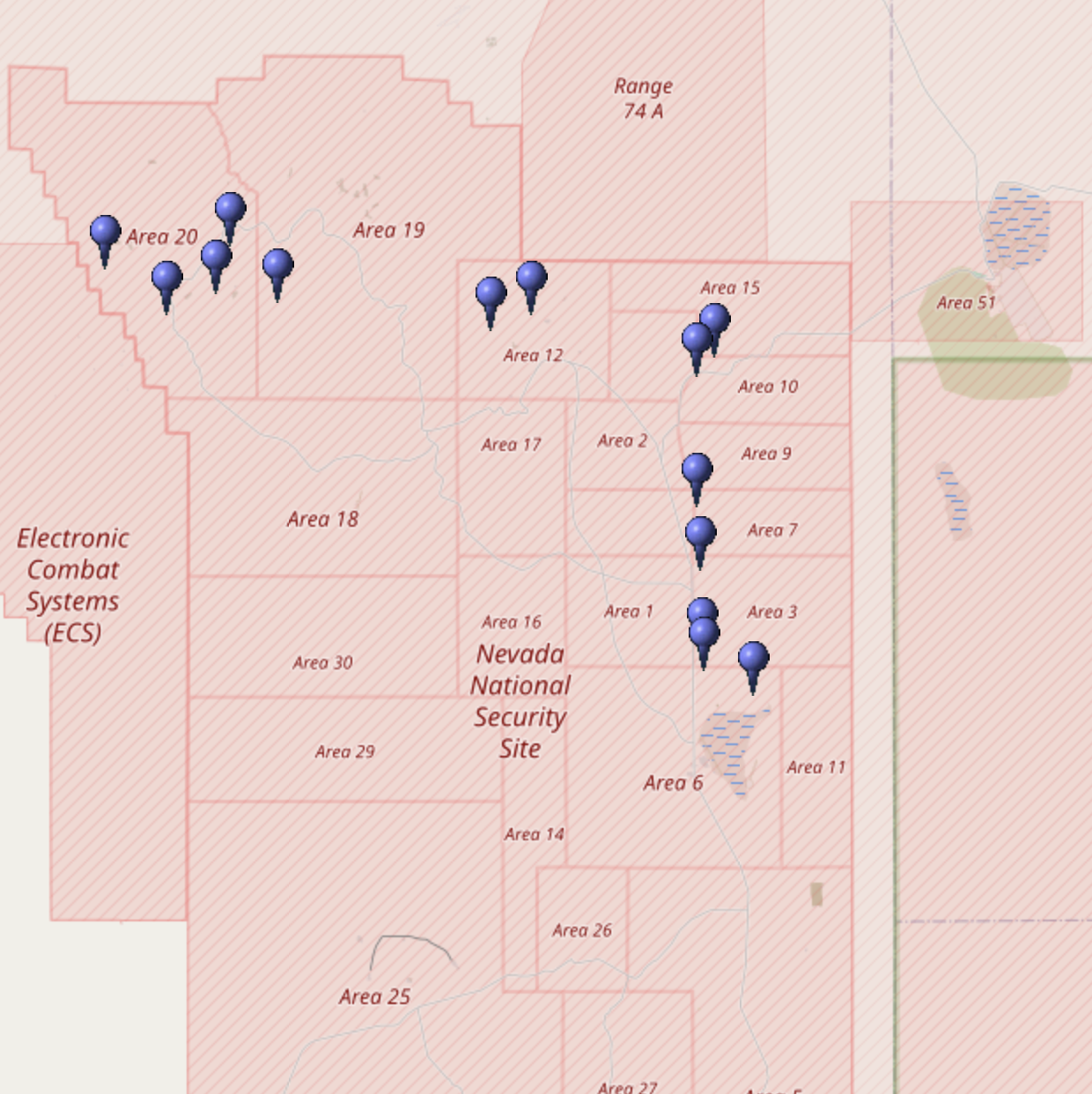 @NuclearDisorder@mastodon.social
@NuclearDisorder@mastodon.socialHeute vor 57 Jahren: Am 15. November 1968 zündeten die #USA im Rahmen von Operation Bowline die Atombombe "Ming Vase". Bowline war eine Serie von #Kernwaffentests bei der 68/69 insgesamt 58 Bomben im Testgebiet in
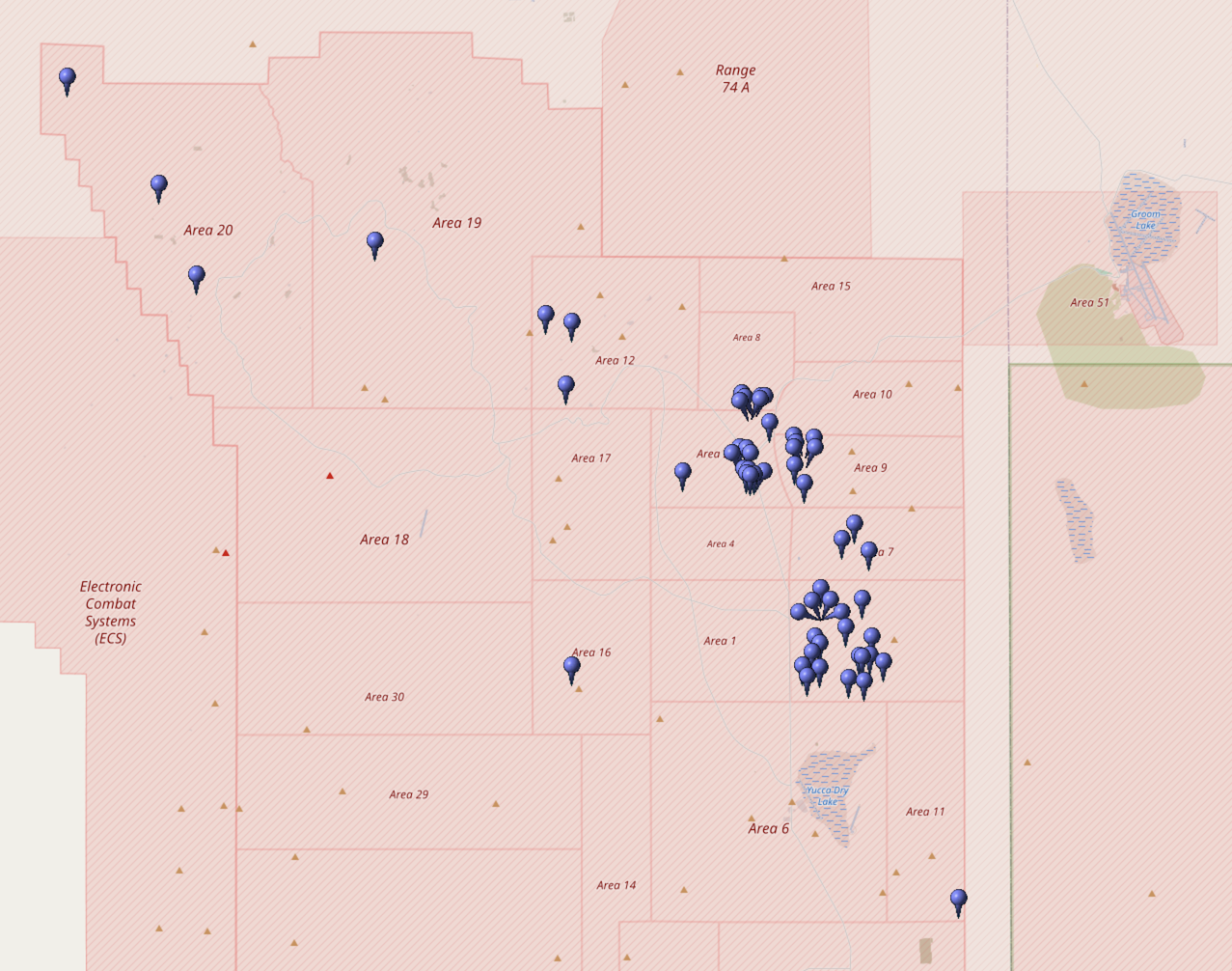 @NuclearDisorder@mastodon.social
@NuclearDisorder@mastodon.socialHeute vor 57 Jahren: Am 15. November 1968 zündeten die #USA im Rahmen von Operation Bowline die Atombombe "Auger". Bowline war eine Serie von #Kernwaffentests bei der 68/69 insgesamt 58 Bomben im Testgebiet in
 @NuclearDisorder@mastodon.social
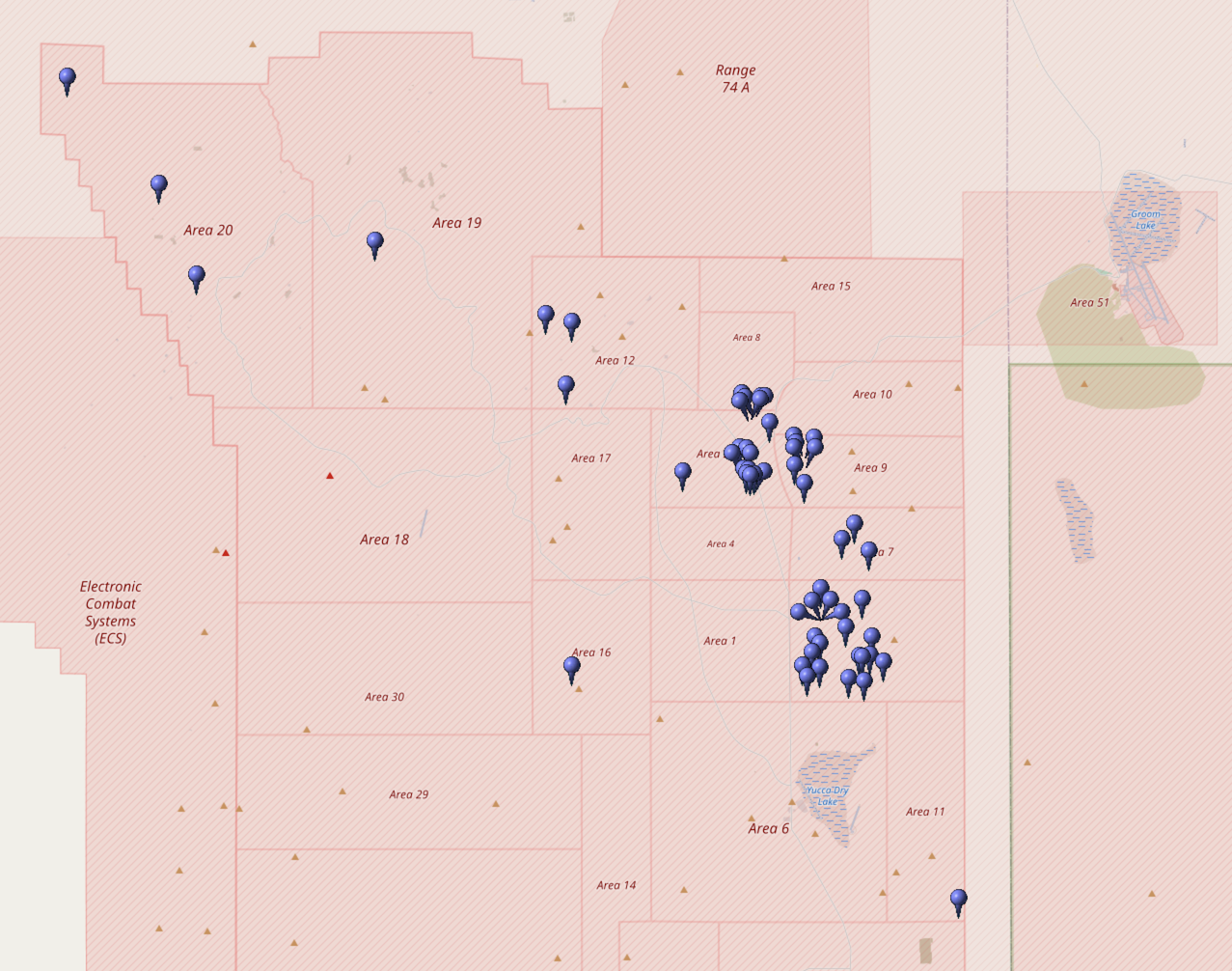
@NuclearDisorder@mastodon.socialHeute vor 36 Jahren: Am 14. November 1989 testen die #USA die Atombombe "Muleshoe". Die Operation Aqueduct war eine Serie von 10 US-amerikanischen #Kernwaffentests, die 1989 und 1990 auf der Nevada Test Site in Nevada unterirdisch durchgeführt wurde.
 @NuclearDisorder@mastodon.social
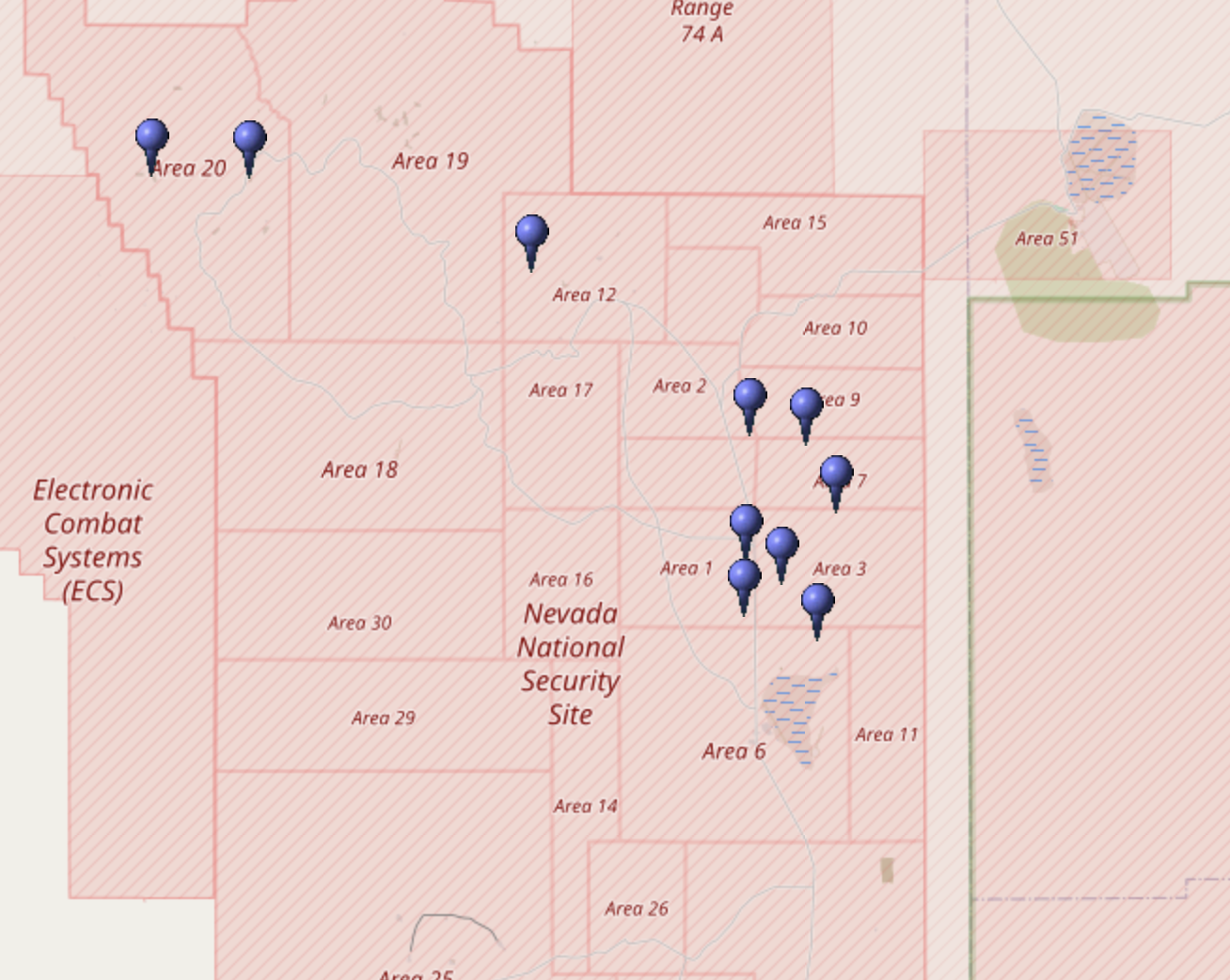
@NuclearDisorder@mastodon.socialHeute vor 57 Jahren: Am 15. November 1968 zündeten die #USA im Rahmen von Operation Bowline die Atombombe "Knife-B". Bowline war eine Serie von #Kernwaffentests bei der 68/69 insgesamt 58 Bomben im Testgebiet in
 @NuclearDisorder@mastodon.social
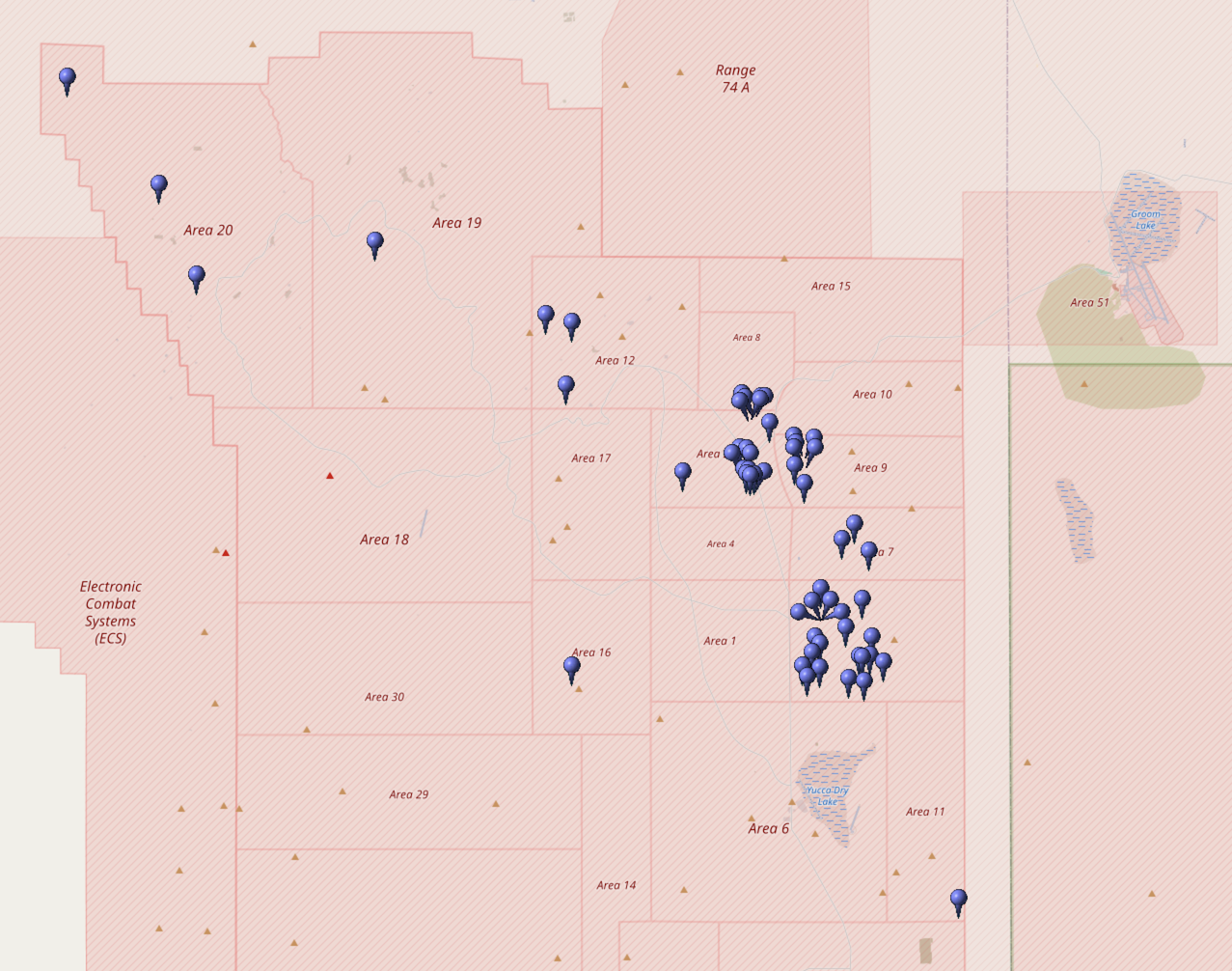
@NuclearDisorder@mastodon.socialHeute vor 59 Jahren: Am 15. Oktober 1966 testen die #USA die Atombombe "Khaki". Die Operation #Latchkey war eine Serie von 38 US-amerikanischen #Kernwaffentests, die 1966/67 auf der Nevad…
 @NuclearDisorder@mastodon.social
@NuclearDisorder@mastodon.socialHeute vor 45 Jahren: Am 14. November 1980 testen die #USA die #Atombombe "Dauphin". Die Operation #Guardian war eine Serie von 14 US-amerikanischen
 @NuclearDisorder@mastodon.social
@NuclearDisorder@mastodon.socialHeute vor 39 Jahren: Am 14.10.1986 zündeten die #USA im Rahmen von Operation Musketeer die Atombombe "Gascon". Musketeer war eine Serie von #Kernwaffentests bei der 1986/87 insgesamt 16 Bomben im Testgebiet in
 @NuclearDisorder@mastodon.social @NuclearDisorder@mastodon.social
@NuclearDisorder@mastodon.social @NuclearDisorder@mastodon.socialHeute vor 56 Jahren: Am 13. November 1969 testen die #USA die Atombombe "Scuttle". Operation Mandrel war eine Serie von 53 US-amerikanischen #Kernwaffentests, die 1969/70 hauptsächlich auf der Nevada Test Site in Nevada unterirdisch durchgeführt wurde.
 @NuclearDisorder@mastodon.social @NuclearDisorder@mastodon.social @NuclearDisorder@mastodon.social
@NuclearDisorder@mastodon.social @NuclearDisorder@mastodon.social @NuclearDisorder@mastodon.socialHeute vor 43 Jahren: Am 12.11.1982 zündeten die #USA im Rahmen von Operation Phalanx die 1. Atombombe "Seyval". Phalanx war eine Serie von #Kernwaffentests bei der 1982/83 insgesamt 19 Bomben größtenteils im Testgebiet in
 @NuclearDisorder@mastodon.social
@NuclearDisorder@mastodon.social