I hadn't really on my radar that @… changed its root/intermediate structure and is now issuing from roots that need a two-intermediate chain. That seems quite a bit of overhead, but, if I'm not missing something, as long as the new "YR"/"YE" roots aren't widely in cert stores, this is unavoidable, right? (may however incre…
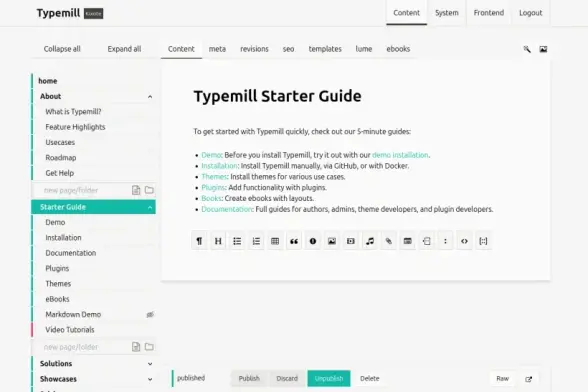
Typemill – Das unterschätzte Flat-File-CMS für alle, die Kirby lieben, aber nicht zahlen wollen
Wer sich intensiver mit Content-Management-Systemen beschäftigt, kommt an Kirby kaum vorbei. Elegante Architektur, wunderbares Backend, flat-file – keine Datenbank, kein Overhead. Das Problem: Kirby kostet pro Domain. Wer mehrere private Webseiten betreiben möchte, zahlt schnell mehrere Hundert Euro. Genau hier kommt Typemill ins Spiel.
Edge-Based QoS-Aware Adaptive Task Placement: A Closed-Loop Control in Multi-Robot Systems
Thien Tran, Jonathan Kua, Thuong Hoang, Minh Tran, Honghao Lyu, Jiong Jin
https://arxiv.org/abs/2606.00552 https://arxiv.org/pdf/2606.00552 https://arxiv.org/html/2606.00552
arXiv:2606.00552v1 Announce Type: new
Abstract: Multi-robot systems (MRS) increasingly offload compute-intensive perception tasks to edge nodes to meet strict time-sensitive Quality-of-Service (QoS) constraints. However, static task orchestration on a shared edge node can severely degrade QoS due to network latency, jitter, and edge-resource contention. We present a pilot edge-centric MRS testbed using Raspberry Pi nodes to evaluate a camera-to-manipulator pipeline under three modes: local execution, static offloading, and a QoS-aware Adaptive Task Placement (ATP) controller. ATP scores candidate placements using a multi-metric cost (normalized latency, CPU utilization, and switching overhead) over two-second control windows. The closed-loop visual servoing testbed is instrumented with sub-millisecond clock synchronization, network emulation, and detailed monitoring of multiple metrics across nodes to capture realistic jitter. Experimental results under compute-stress and network-fault scenarios show that static edge offloading reduces on-board CPU load but amplifies tail latency and deadline misses. In contrast, the QoS-aware ATP controller, by switching task placement based on measured latency and utilization thresholds, consistently lowers deadline violations and tail latency. Overall, the results position ATP as a practical edge-side control primitive for MRS and concrete design guidelines for Cloud-Edge Robotics deployments within the broader cloud-fog automation, while motivating QoS-aware multi-objective workload orchestration for industrial cyber-physical systems.
toXiv_bot_toot
There are lots of red kites around Reading in the UK because it is where they were first reintroduced back in the 80s.
@… I was looking at these old photos of NYC, and I was struck by there being no overhead "wires" for the streetcars to draw power from. Were they taking it from the rails somehow? From circa 1907.
About two years ago, I was trying to get concurrent output for several LED strips working in #rust on #esp32 using the RMT peripheral. I got it working kind of ok for two outputs, but some switching overhead in embassy made that the limit.
Last week I figured I'd try using the "LCD" output o…
It’s the day after Mother’s Day, the first one Elizabeth Soto has spent apart from her three children.
Sitting in jail in Wichita Falls, Texas, her face is washed out by the overhead fluorescent lighting,
and her dingy jumpsuit blends into the cinder block walls surrounding her.
Speaking through a glass separator, she tells me she celebrated the holiday with her children over the jail’s video-call system while they had dinner at their grandmother’s.
“I’ve been a full…
i managed to catch the sunset tonight.
#sunset
How much does it take to hold one tram junction's worth of overhead line? 9 tons of counterweight per pole, apparently.
#Helsinki #umarell
A Not So Brave New World II 🌐
不太美丽的新世界 II 🌐
📷 Nikon F4E
🎞️ Lucky SHD 400 (FF)
If you like my work, Support by buying me a coffee or a roll of film from
PayPal https://www.paypal.com/paypalme/ydcdingsite
Wise
The Conditional Button
The mid-block crosswalk at a flashing-yellow pedestrian signal does work. A pedestrian presses the button, the overhead lights flash yellow, drivers slow or stop, and the pedestrian crosses. The system responds visibly, with no covert work happening underneath. The button does what it claims. But the same system also fails, often, in ways that have nothing to do with the button itself and everything to do with what is wired several layers behind…
Decompressing, right here, right now.
#nature #photography
Aome kinda advanced calculus gang seems yo have moved into the hood and is tagging things
#ShitPost #Shitposting
Der Overhead, den wir als Gesellschaft betreiben müssen, weil Menschen einfach scheiße zueinander bzw egoistische Arschlöcher sind, ist halt schon gigantisch. Und je weiter oben in der Hierarchie, je mehr Schaden kann das anrichten.
#pol
My wife went swimming in Footscray this morning so I had her drop me off by the pool and then I ran home along the Maribyrnong river and up the Stockyard trail, back through Royal Park to the inner North. Brilliant day for a run and a nice change of scenery. #melbourne #running
All I wanted is a quick note when a new book from one of the authors or book series I like is published. And the same for new works from movie directors or TV series I enjoy.
An email newsletter or an RSS feed could easily handle that with no or little overhead.
But those often did not exist or were way too noisy because somebody wanted to sell something else.
And that's why soon everybody will use AI agents with all their overhead for that.
from a bit earlier.
Goodnight
#night
Good afternoon #BikeNYC #BikeTooter. Gorgeous day out there, make sure you've got your official #NYC garbage bin before the June 1st deadline!
I got a quite extensive answer back from a question to an LLM. So I went and checked the docs on the suggested solutions. In the docs I find this gem:
> Consequently, j.u.l. to SLF4J translation can seriously increase the cost of disabled logging statements (60 fold or 6000% increase) ... Please note that ... it is possible to completely eliminate the 60-fold translation overhead for disabled log statements with the help of LevelChangePropagator.
#Virga is rain that doesn’t reach the ground. It’s a thing here in the US mountain west. Very cool and photogenic and strikingly dramatic to see in the distance, especially depending on where the sun is when you see it. I just stepped out of my house and a bit of virga exceeded expectations and reached the ground around me. So, just rain, but no clouds overhead, sun casting solstice 7 o’clock shadows…
Blurry Figures II 🪬
模糊的形象 II🪬
📷 Yashica 635
🎞️ Ilford FP4 Plus 125 (FF), expired 1994
If you like my work, Support by buying me a coffee or a roll of film from
PayPal https://www.paypal.com/paypalme/ydcdingsite
Wise
Wachusett Reservoir is the largest hand-built dam in the world, assembled from great granite blocks
#photo #photography #dam
Carefully hugged this smol oak tree on Shotwell Street 💚 Coast live oaks were likely the most common tree in so-called San Francisco before colonization and provide habitat/food for 270 species. But they’re rarely planted as street trees: only 9 scattered around the Mission according to DPW. The city only allows them on sidewalks 15’ wide without overhead power lines, a unicorn situation. Even then they usually plant Australian and other exotic species.
on the river with lynn and max
If you are an anarchist and you speak only one language, learn another one. Learn the language of your land, the indigenous language where you live. Learn the language of your ancestors, especially those languages that the state has tried to murder away. Learn an international language other than English, which have also been targets of state repression.
Prioritize languages that you both have some connection with (because it's hard to learn a language you don't care about) and languages that the state has tried to erase (because there are *reasons* those languages were targeted). Language (which can't be fully separated from culture) adds complexity. The state often tries to murder away language because (among other reasons) hierarchy is threatened by complexity. Every language adds some surveillance overhead, some more than others.
New F1-overhead Apple TV screensavers wen
Bounded Priority-Aware Locking for Real-Time Kernels
Shriram Raja, Richard West
https://arxiv.org/abs/2605.27620 https://arxiv.org/pdf/2605.27620 https://arxiv.org/html/2605.27620
arXiv:2605.27620v1 Announce Type: new
Abstract: A real-time multicore system requires delay bounds on access to shared resources. These resources include the kernel, which has potentially many non-preemptible critical sections guarded by one or more different synchronization primitives. While primitives such as FIFO locks bound the waiting time to enter a critical section, they do not distinguish the importance of individual tasks competing for shared resource access. To address this, we consider a priority-aware spinlock, which reduces the average delay of more important tasks while maintaining a worst-case bound on lock waiting time. We propose a Batched Priority Lock (BPL) that first groups waiting tasks based on the order of their lock requests, and then determines the next lock holder according to priority within the waiting group. We compare BPL to alternative lock approaches, showing that the average waiting time is reduced for higher priority tasks, in simulations up to 64 cores, and for a working implementation on an 8-core machine with a real RTOS. BPL is a compromise between strict priority and FIFO ordering. While strict priorities may lead to starvation and, hence, unbounded lock acquisition delays, BPL has the same waiting bound as FIFO, but with benefits to higher priority tasks. Although its complexity is greater than that of a simple spinlock, its common case execution overhead is shown to be inexpensive in a working system. We believe this is an acceptable cost in systems that require predictability.
toXiv_bot_toot
Carefully hugged this smol oak tree on Shotwell Street 💚 Coast live oaks were likely the most common tree in so-called San Francisco before colonization and provide habitat/food for 270 species. But they’re rarely planted as street trees: only 9 scattered around the Mission according to DPW. The city only allows them on sidewalks 15’ wide without overhead power lines, a unicorn situation. Even then they usually plant Australian and other exotic species.
Urban Ridicules ❌
都市的愚弄 ❌
📷 Pentax 6x7
🎞️ Ilford HP5 Plus 400 (6x7)
If you like my work, Support by buying me a coffee or a roll of film from PayPal https://www.paypal.com/paypalme/ydcdingsite
An iterative Ising decoder for quantum error correction codes
Yuanqi Liu, Weilei Zeng, Peixiang Li, Yantong Liu, Guangyao Huang, Yingwen Liu, Dongyang Wang, Junjie Wu, Lingling Lao
https://arxiv.org/abs/2606.12301 https://arxiv.org/pdf/2606.12301 https://arxiv.org/html/2606.12301
arXiv:2606.12301v1 Announce Type: new
Abstract: The Ising framework maps the decoding problem in quantum error correction onto ground-state optimization of a classical Hamiltonian, in which $X$-$Z$ error correlations enter as cross terms. Under phenomenological depolarizing noise, the exact joint formulation contains up to 8-body interactions for the toric code and 10-body for the $6.6.6$ color code. These high-order terms degrade solver convergence, inflate runtime, and raise the auxiliary spin overhead when embedding into native 2-body Ising hardware. In this work, we propose the iterative low-order decoding (ILOD) algorithm, which alternates between $X$- and $Z$-type sub-Hamiltonians, approximating cross-type correlations through Bayesian priors that reweight each type's couplings using the other type's inferred error configuration. This halves the maximum body count of interaction terms in the Hamiltonian, accelerating the solver, restoring convergence at larger code distances, and reducing the total spin count for 2-body embedding by a factor of $2.5$. For the toric code, ILOD attains a threshold of $4.73%$ versus $4.83%$ for the joint formulation, with the empirical runtime ratio scaling as $(0.81)^d$. For the $6.6.6$ color code, their thresholds agree within statistical uncertainty for small code distances, and ILOD remains convergent for larger distances where the joint formulation fails to converge despite a larger annealing budget.
toXiv_bot_toot
Color-Rule-Function Encoding for Combinatorial Memory
Alexander Khitun
https://arxiv.org/abs/2606.11365 https://arxiv.org/pdf/2606.11365 https://arxiv.org/html/2606.11365
arXiv:2606.11365v1 Announce Type: new
Abstract: Combinatorial memory is a class of memory in which information is encoded in the set of paths through a structured mesh. In this work, we introduce a systematic encoding framework, referred to as the Color-Rule-Function (CRF) approach, for representing information in combinatorial memory. The method consists of four key steps: selecting a sequence of paths in the mesh, assigning values (e.g., colors) to each cell, defining a set of rules based on the values encountered along each path, and constructing a Boolean function that determines the state of each path. . The coding procedure is illustrated by several examples. The design space scales of the CRF scale fundamentally faster compared to conventional memory. This apparent advantage arises from the use of rule-based and functional representations but is accompanied by increased hardware complexity. A possible hardware realization of the CRF framework is discussed. Importantly, the hardware overhead can be substantially reduced through the use of customized modules. The examples of the customized design are described in the text. The combination of CRF coding with customized module design may lead to a practical advantage in data storage density. According to the estimates, the data storage density may exceed Exabit per centimeter squared. A key problem that requires further investigation is related to the minimum Hamming distance between an arbitrary target bit sequence and the closest sequence realizable within the CRF framework under fixed hardware constraints.
toXiv_bot_toot
Whizz Air have this scam where they have a smaller under-seat-bag test than all the other airlines.
So when you head there with your standard under-seat bag that you use everywhere else, and that fits fine under the seat in reality,, they still make you pay another 70 euros for it to go in overhead just because it won't fit in their super-tiny extra-small testing bay.
The plane was half empty too, so it not like they really super needed to ration the overhead space.
If you're flying Wizz Air, maybe don't, and certainly make sure to note they have this small-bag scam going on.
#whizzAir #scam
ANNS-AMP: Accelerating Approximate Nearest Neighbor Search via Adaptive Mixed-Precision Computing
Mingkai Chen, Cheng Liu, Shengwen Liang, Lei Zhang, Xiaowei Li, Huawei Li
https://arxiv.org/abs/2606.07156 https://arxiv.org/pdf/2606.07156 https://arxiv.org/html/2606.07156
arXiv:2606.07156v1 Announce Type: new
Abstract: Approximate nearest neighbor search(ANNS) is a critical kernel in modern applications such as LLM and recommendation systems.However,its efficiency is fundamentally limited by the need to compute distances between a query and a massive number of high-dimensional vectors,most of which are non-neighbors.Existing approaches reduce redundancy via index optimization or early termination,but remain constrained by fixed-precision computation,leading to unnecessary arithmetic and memory bandwidth overhead.This paper presents ANNS-AMP,an adaptive mixed-precision framework and accelerator that adapts the precision of distance computation to the characteristics of queries and data distribution.The key insight is that different regions of the vector space require different levels of precision to preserve top-k accuracy.ANNS-AMP leverages the clustered structure of PQ-based indices and introduces a lightweight predictor to determine cluster-level precision at runtime based on features such as scale,radius,and query distance.To efficiently realize variable-precision execution,we design a bit-serial accelerator with a bit-interleaved data layout,enabling throughput to scale with reduced precision while mitigating memory bandwidth bottlenecks and load imbalance through a greedy scheduling strategy.Moreover,the runtime predictor can also reuse the bit-serial computing array for efficient runtime prediction and can be fitted to the ANNS pipeline without performance penalty.According to our experiments on representative datasets,ANNS-AMP achieves 163.76x,10.57x,and 2.06x performance speedups on average,and reduces average energy consumption by 1100.00x,39.41x,and 6.66x compared to CPU,GPU,and customized ANNS accelerator baselines,respectively,while maintaining accuracy loss below 2.7%.These results demonstrate that adaptive mixed-precision computing is a promising direction for efficient large-scale ANNS.
toXiv_bot_toot
RE: https://mastodon.online/@sherold/116481485878550299
If laptop stickers say something about the owner's attitude, then I have absolutely no idea what this is supposed to say about me. I guess it doesn't matter.
Hard Guarantees at a Measured Price: Entropy-Stable Learned Finite Volumes for Compressible Flow
Denis Gueyffier (ONERA -- Institut Polytechnique de Paris)
https://arxiv.org/abs/2607.20171 https://arxiv.org/pdf/2607.20171 https://arxiv.org/html/2607.20171
arXiv:2607.20171v1 Announce Type: new
Abstract: Learned solvers for compressible flow are usually compared to classical methods at equal mesh resolution rather than at equal computational cost, and they typically offer no guarantee that their solutions remain physically admissible. We present a learned finite volume scheme for the two-dimensional Euler equations on unstructured meshes, admissible by construction and with an entropy-stable interior flux. We evaluate it under protocols fixed before any computation: frozen thresholds, falsification clauses, negative controls, a factor decomposition of the learned components, and an iso-cost comparison against the refined classical baseline. The decomposition produced the central result: the guarantee machinery alone, with both learned heads switched off (the unlearned skeleton), is the strongest scheme at equal mesh on every periodic case. At equal wall-clock cost the picture inverts into a map. Learning pays robustly only on the wall case whose boundary-condition type it never saw (10.8%). Its periodic gains flip sign with the evaluation draw ( 10% on one held-out case, -12% on the hardest). The skeleton is the only method whose iso-cost gain never changes sign, at a measured overhead of 1.74x per step. The guaranteed variant completes 36 of 36 rollouts, Mach extrapolation and unseen wall included, with zero negativity events. We fix the guaranteed scheme's one remaining out-of-distribution weakness, Mach extrapolation, at inference time: with scale-invariant network inputs, a specific-entropy floor, and no retraining, the corrected arm overtakes the unconstrained arm on one Mach case, cuts its deficit on the other by a third, passes the skeleton on the unseen wall, and keeps the guarantee. A spatial gate closes the loop: activating the heads only near the walls beats both the skeleton and the corrected arm, and transfers unchanged to a second wall geometry.
toXiv_bot_toot
Decode-Time Grammars: Constrained LLM Generation over a Refinement Order of Grammar Fragments
Shuoming Zhang, Ruiyuan Xu, Haofeng Li, Qiuchu Yu, Yangyu Zhang, Chunwei Xia, Xiaobing Feng, Chenxi Wang, Huimin Cui, Jiacheng Zhao
https://arxiv.org/abs/2607.18357 https://arxiv.org/pdf/2607.18357 https://arxiv.org/html/2607.18357
arXiv:2607.18357v1 Announce Type: new
Abstract: Large language models now write a growing share of the world's code, increasingly inside agents and serving systems that compile, execute, or dispatch generated code without line-by-line review. This works well for mainstream languages but remains brittle for low-resource programming surfaces such as domain-specific languages, custom library APIs, and command-line tools. Even under grammar-constrained decoding, a model can still produce references invalid in the current environment: a buffer never declared, a column absent from the schema, a function the library does not provide, or an unsupported CLI option.
This paper introduces decode-time grammars: grammar fragments instantiated during generation from a runtime environment Gamma. A region-specific policy selects a fragment for each hole, and a tightening operator replaces open reference positions with Gamma-typed slots whose candidates are exactly the names, fields, APIs, or options available at that point. Newly generated declarations enter Gamma before later regions are decoded, so the constraining grammar can depend on the prefix already generated. This ensures not only grammatical correctness but also semantic correctness, by preventing references to undefined symbols.
We formalize grammar fragments as environment-indexed grammars ordered by refinement, prove No-Ghost soundness for Gamma-slotted fragments, show that refinement preserves this support-set guarantee, and characterize the boundary of mask-enforceable properties. We implement the approach in gproj with offline grammar induction and online policy resolution. Across TileLang, SQL, and P4, with models from 0.6B to 236B parameters, gproj eliminates ghost references by construction at moderate overhead over standard constrained decoding.
toXiv_bot_toot
Inside Outside VIII 🔲
中间 VIII 🔲
📷 Pentax MX
🎞️ Fujifilm Neopan F, expired 1993
If you like my work, Support by buying me a coffee or a roll of film from
PayPal https://www.paypal.com/paypalme/ydcdingsite
Wise
Inside Outside V 🔲
中间 V 🔲
📷 Pentax MX
🎞️ Fujifilm Neopan F, expired 1993
If you like my work, Support by buying me a coffee or a roll of film from
PayPal https://www.paypal.com/paypalme/ydcdingsite
Wise
GNStor: Design of GPU-Native High-Performance Remote All-Flash Array
Shushu Yi, Wenbo Wu, Guoci Chen, Junrong Zhu, Shengwen Liang, Mao Bo, Chenying Huan, Chen Tian, Jie Zhang
https://arxiv.org/abs/2606.04908 https://arxiv.org/pdf/2606.04908 https://arxiv.org/html/2606.04908
arXiv:2606.04908v1 Announce Type: new
Abstract: GPU has become the leading computing device for a wide range of data-intensive applications, which tightly collaborates with remote all-flash array (AFA) to accommodate ever-expanding datasets, facilitate multi-client data sharing, and guarantee fault tolerance. Although GPU is the center of computation, all I/O processes in existing GPU-AFA systems are still CPU-centric. CPU orchestrates remote I/O requests and executes a centralized AFA engine to take charge of AFA-level functionalities (e.g., access control and metadata persistence). This design disparity suffers from substantial CPU-GPU interaction overhead and I/O traffic amplification, compromising end-to-end I/O performance.
In this work, we present \emph{GNStor}, a GPU-native AFA system that enables GPU to directly access remote AFA without CPU intervention in the I/O path, thereby fully exploiting the performance of AFA. Specifically, GNStor first proposes a GPU-centric NVMe over RDMA (NoR) software stack (named \emph{GNoR}), paving a fast path for GPUs to directly initiate NoR I/O requests to SSDs within remote AFA. GNoR employs an atomic-operation-based I/O orchestration design and follows the single-instruction-multiple-thread (SIMT) execution model of GPU, fully exploiting the massive parallelism of GPU architectures. To facilitate essential AFA functionalities in a CPU-bypass I/O path, GNStor further designs \emph{deEngine}, a decentralized AFA engine that seamlessly decomposes and integrates AFA-level tasks into each SSD firmware, thereby achieving efficient AFA access at low cost. Evaluation results show that GNStor achieves 3.2$\times$ higher I/O throughput and reduces application execution time by 31.1\%, compared to state-of-the-art AFA systems.
toXiv_bot_toot
 @hanno@mastodon.social
@hanno@mastodon.social