 @awinkler@openbiblio.social
@awinkler@openbiblio.social2026-07-01 19:28:33
193 Zeitschriften in der #Zeitschriftendatenbank #zdb, die eine #Wikisource-Version haben:
@awinkler@openbiblio.social193 Zeitschriften in der #Zeitschriftendatenbank #zdb, die eine #Wikisource-Version haben:
@awinkler@openbiblio.social#Neulatein|ische Werksnormdaten in der #GND? Die sind gar nicht mal so leicht zu finden, weil literarische Werke offenbar gar nicht eigens ausgezeichnet sind. Sprache = Latein ist kein ausreichendes Kriterium, weil da auch einige Druckermarken im Ergebnis auftauchen. Die lassen sich bei der übersi…
 @acka47@openbiblio.social
@acka47@openbiblio.socialIn der #bibliocon26 Session "Daten im Netzwerk" präsentiert @… den SPARQL-Endpoint der Deutschen Nationalbibliothek, mit dem komplexe Graph-Abfragen auf die GND, die Deutsche Nationalbibliographie und neuerdings auch die ZDB inklusive dem ISIL-Verzeic…
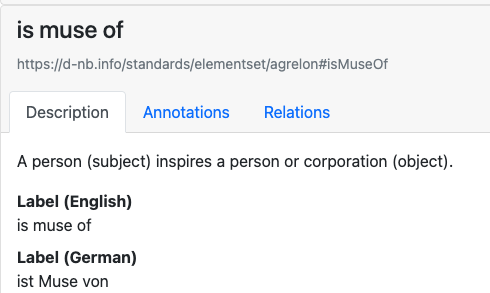
@awinkler@openbiblio.socialwas es da nicht alles an Properties gibt ... im aktuellen sparql-Service finden sich (noch) keine Musen, scheint mir. Auch "hasLover" ist noch nicht vertreten.RDF-konforme Sacherschließung von Bunte&Co. ist also noch nicht angelaufen.
https://d-nb.info/standards/elementset
 @johl@mastodon.xyz
@johl@mastodon.xyzVous ne vous souvenez plus du code #Minitel qui suit 3615 pour un élément #Wikidata spécifique ? Voici une requête en SPARQL !
https://w.wiki/Rm5r
 @awinkler@openbiblio.social
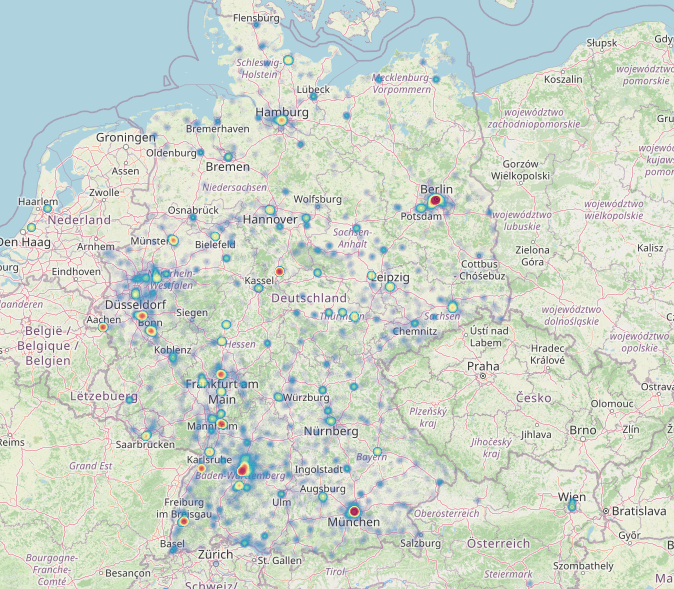
@awinkler@openbiblio.socialGeographische Visualisierung des ISIL-Verzeichnisses (Datenquelle ist der neue @… SPARQL-Endpunkt, Visualisierung erfolgt in der #Qlever-GUI, die Petrimaps unterstützt):
Karte:
 @kidehen@mastodon.social
@kidehen@mastodon.socialTools used:
1. Anthropic’s Claude Code as the AI agent
2. DeepSeek-v4 as the LLM
3. Virtuoso Data Spaces platform, comprising:
* A WebDAV-based filesystem for hosting generated RDF, HTML, and Markdown documents
* A high-performance DBMS engine that automatically ingests and manages these documents
* Support for RDF graphs and relational tables accessible via SQL, SPARQL, GraphQL, etc. (note: we also have openCypher and GQL in the works to bury…
@awinkler@openbiblio.socialOh, da gibt es noch was zu tun. Über 8000 Objekte der Berliner Denkmalliste stehen auf Wikidata, haben aber noch keine Verlinkung zu #OpenStreetMap ( #OSM ): https://
@awinkler@openbiblio.socialoh, das ist mir neu in #SPARQL. Ich habe bislang immer nach 'LANG(?string) = "en"' gefiltert. Finde diese Syntax auch nicht in der SPARQL-Spezfikation 🤷
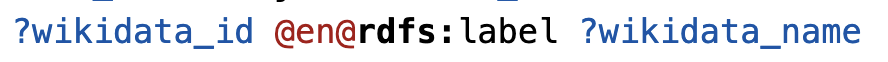 @awinkler@openbiblio.social
@awinkler@openbiblio.socialStrukturierte Daten auf #wikicommons sind ungemein nützlich. Mit ihnen lassen sich z.B. Bildinhalte strukturiert und (dank Linked Open Data) wunderbar maschinenlesbar erfassen und dann auch mit #SPARQL abfragen. Bilder von SPD-Mitgliedern des Weimarer Reichtstags? Kein Problem:
@awinkler@openbiblio.socialstatistische Herleitung eines Wikidata-Datenmodells für Berliner Gebäude: https://qlever.dev/wikidata/fKDU39
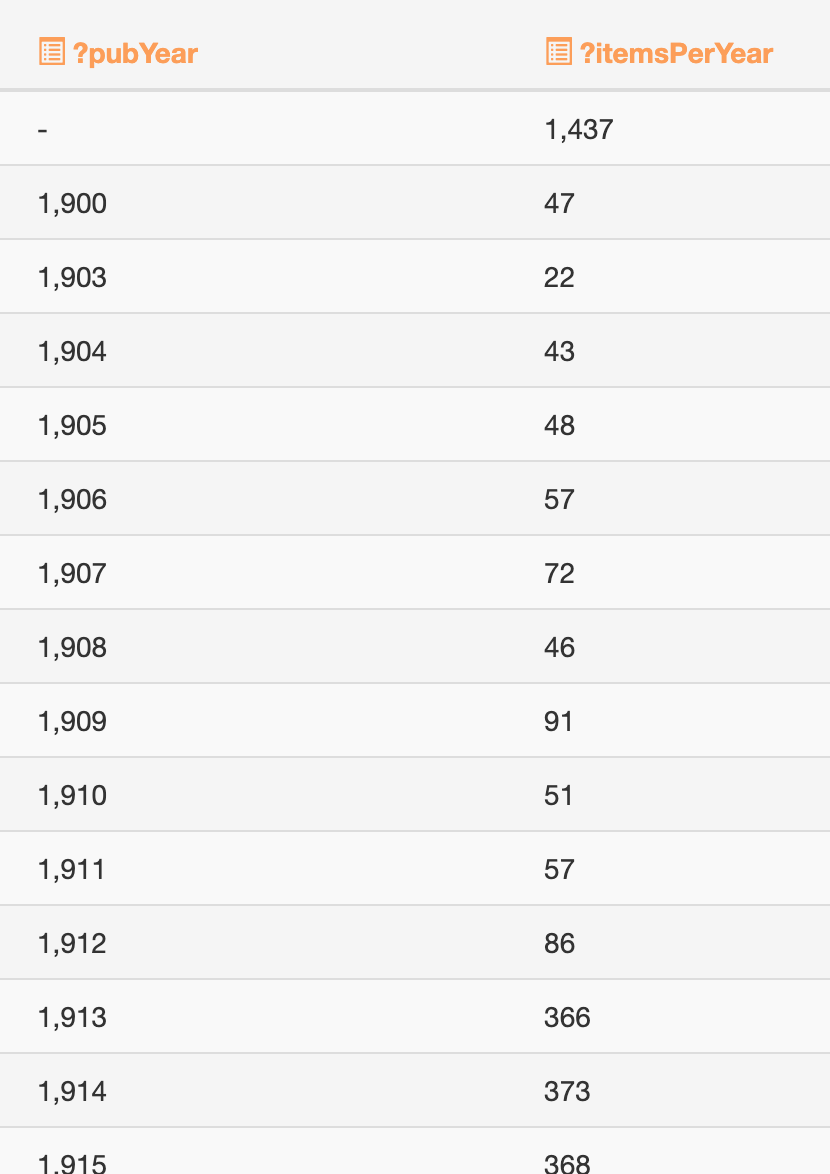
@awinkler@openbiblio.socialSimon Herrmann berichtet auf der #bibliocon26 über den Lizenzierungsservice VW-LIS der @… . Dank des SPARQL-Endpunkts lässt sich eine Statistik generieren, wie viele Werke über dieses Verfahren bereitgestellt werden konnten, hier geordnet nach Ers…
 @awinkler@openbiblio.social
@awinkler@openbiblio.socialfür #wikicommons -affine #Berlin -Expert:innen: Bilder der Berliner Akzisemauer, die nicht das Brandenburger Tor darstellen. Da muss es doch noch mehr geben, oder?
@awinkler@openbiblio.socialIn der Annotation von Karten/Stadtplänen auf #wikicommons liegt ein wahnsinniges Potential (ad-hoc-'Gelegenheitsannotation' möglich, eindeutige Identifikation der Objekte durch #wikidata-Items, niedrigschwelliger Zugriff, optimale Nachnutzungsmöglichkeiten). Bislang ist das aber noc…
@awinkler@openbiblio.socialWer heute auf der #bibliocon26 noch etwas Hands-On-Erfahrung mit Python und SRU- und SPARQL-Schnittstellen im Bibliotheks- bzw. #GLAM -Sektor sammeln möchte, den könnte folgendes Hands-on Lab (Raum 14, 16:30-18:30) interessieren:
@awinkler@openbiblio.socialKünstler:innen (d.h. alles, was unter creator, Q12777906, fällt), die in Berlin geboren sind und für die es in #wikidata keinen Nachweis eines Nachlasses gibt: https://qlever.dev/wikidata/AKEpTU
@awinkler@openbiblio.socialAuf dem Weg an die FH Potsdam, wo ich in einem Seminar zum #Wikiversum in #GLAM|s angehenden Biblioheks- und Archivmenschen die Arbeit mit #Wikidata,
@awinkler@openbiblio.social