 @arXiv_hepth_bot@mastoxiv.page
@arXiv_hepth_bot@mastoxiv.page2025-09-18 08:16:41
Thermodynamic Split Conjecture and an Observational Test for Cosmological Entropy
Oem Trivedi
https://arxiv.org/abs/2509.13689 https://arxiv.org/pdf/2509.1…
@arXiv_hepth_bot@mastoxiv.pageThermodynamic Split Conjecture and an Observational Test for Cosmological Entropy
Oem Trivedi
https://arxiv.org/abs/2509.13689 https://arxiv.org/pdf/2509.1…
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageBoN Appetit Team at LeWiDi-2025: Best-of-N Test-time Scaling Can Not Stomach Annotation Disagreements (Yet)
Tomas Ruiz, Siyao Peng, Barbara Plank, Carsten Schwemmer
https://arxiv.org/abs/2510.12516
 @arXiv_csSE_bot@mastoxiv.page
@arXiv_csSE_bot@mastoxiv.pageAn LLM Agentic Approach for Legal-Critical Software: A Case Study for Tax Prep Software
Sina Gogani-Khiabani (University of Illinois Chicago), Ashutosh Trivedi (University of Colorado Boulder), Diptikalyan Saha (IBM Research), Saeid Tizpaz-Niari (University of Illinois Chicago)
https://arxiv.org/abs/2509.13471
 @arXiv_csHC_bot@mastoxiv.page
@arXiv_csHC_bot@mastoxiv.pageData-Model Co-Evolution: Growing Test Sets to Refine LLM Behavior
Minjae Lee, Minsuk Kahng
https://arxiv.org/abs/2510.12728 https://arxiv.org/pdf/2510.1272…
 @arXiv_econEM_bot@mastoxiv.page
@arXiv_econEM_bot@mastoxiv.pageGeneralized Covariance Estimator under Misspecification and Constraints
Aryan Manafi Neyazi
https://arxiv.org/abs/2509.13492 https://arxiv.org/pdf/2509.134…
 @arXiv_statME_bot@mastoxiv.page
@arXiv_statME_bot@mastoxiv.pageA Martingale Kernel Two-Sample Test
Anirban Chatterjee, Aaditya Ramdas
https://arxiv.org/abs/2510.11853 https://arxiv.org/pdf/2510.11853
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.pageLearning-To-Measure: In-context Active Feature Acquisition
Yuta Kobayashi, Zilin Jing, Jiayu Yao, Hongseok Namkoong, Shalmali Joshi
https://arxiv.org/abs/2510.12624 https://
 @arXiv_qfinST_bot@mastoxiv.page
@arXiv_qfinST_bot@mastoxiv.pageHoldout cross-validation for large non-Gaussian covariance matrix estimation using Weingarten calculus
Lamia Lamrani, Beno\^it Collins, Jean-Philippe Bouchaud
https://arxiv.org/abs/2509.13923
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.pageEfficient Real-World Deblurring using Single Images: AIM 2025 Challenge Report
Daniel Feijoo, Paula Garrido-Mellado, Marcos V. Conde, Jaesung Rim, Alvaro Garcia, Sunghyun Cho, Radu Timofte
https://arxiv.org/abs/2510.12788
 @arXiv_physicsgeoph_bot@mastoxiv.page
@arXiv_physicsgeoph_bot@mastoxiv.pageCorrecting exponentiality test for binned earthquake magnitudes
Angela Stallone, Ilaria Spassiani
https://arxiv.org/abs/2512.13599 https://arxiv.org/pdf/25…
 @arXiv_astrophHE_bot@mastoxiv.page
@arXiv_astrophHE_bot@mastoxiv.pageDIPLODOCUS II: Implementation of transport equations and test cases relevant to micro-scale physics of jetted astrophysical sources
Christopher N. Everett, Marc Klinger-Plaisier, Garret Cotter
https://arxiv.org/abs/2510.12505
 @arXiv_csCR_bot@mastoxiv.page
@arXiv_csCR_bot@mastoxiv.pageArtPerception: ASCII Art-based Jailbreak on LLMs with Recognition Pre-test
Guan-Yan Yang, Tzu-Yu Cheng, Ya-Wen Teng, Farn Wanga, Kuo-Hui Yeh
https://arxiv.org/abs/2510.10281 htt…
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageTitans Revisited: A Lightweight Reimplementation and Critical Analysis of a Test-Time Memory Model
Gavriel Di Nepi, Federico Siciliano, Fabrizio Silvestri
https://arxiv.org/abs/2510.09551
@arXiv_csCL_bot@mastoxiv.pageResource-sensitive but language-blind: Community size and not grammatical complexity better predicts the accuracy of Large Language Models in a novel Wug Test
Nikoleta Pantelidou, Evelina Leivada, Paolo Morosi
https://arxiv.org/abs/2510.12463
 @arXiv_mathFA_bot@mastoxiv.page
@arXiv_mathFA_bot@mastoxiv.pageOn Korovkin-type theorems including exponential test functions on infinite intervals through power series convergence
Dilek S\"oylemez, Mehmet \"Unver
https://arxiv.org/abs/2510.12568
 @arXiv_astrophEP_bot@mastoxiv.page
@arXiv_astrophEP_bot@mastoxiv.pageThe resilience of the sailboat stable region
Rafael Sfair, Tiago F. L. L. Pinheiro, Giovana Ramon, Ernesto Vieira
https://arxiv.org/abs/2510.11855 https://…
 @arXiv_astrophCO_bot@mastoxiv.page
@arXiv_astrophCO_bot@mastoxiv.pageHierarchical summaries for primordial non-Gaussianities
M. S. Cagliari, A. Bairagi, B. Wandelt
https://arxiv.org/abs/2510.12715 https://arxiv.org/pdf/2510.…
 @arXiv_mathRT_bot@mastoxiv.page
@arXiv_mathRT_bot@mastoxiv.pageUnitary representations attached to parabolic subgroups: the case of abelian unipotent radical
Dan Ciubotaru
https://arxiv.org/abs/2510.11862 https://arxiv…
 @publicvoit@graz.social
@publicvoit@graz.socialIf you're using #lazyblorg as your static website generator: I've updated the project today.
It now used "uv" for dependency management, script invocation and unit test execution. Furthermore, I adapted the code to match the #pandoc version of Debian 13 Trixie.
Although you ne…
 @arXiv_condmatstrel_bot@mastoxiv.page
@arXiv_condmatstrel_bot@mastoxiv.pageQuantum criticality at the end of a pseudogap phase in superconducting infinite-layer nickelates
C. Iorio-Duval, E. Beauchesne-Blanchet, F. Perreault, J. L. Santana Gonz\'alez, W. Sun, Y. F. Nie, A. Gourgout, G. Grissonnanche
https://arxiv.org/abs/2510.12786
@arXiv_csHC_bot@mastoxiv.pageGauging the Competition: Understanding Social Comparison and Anxiety through Eye-tracking in Virtual Reality Group Interview
Shi-Ting Ni, Kairong Fang, Yuyang Wang, Pan Hui
https://arxiv.org/abs/2510.12590
 @arXiv_csCY_bot@mastoxiv.page
@arXiv_csCY_bot@mastoxiv.pageNon-traditional data in pandemic preparedness and response: identifying and addressing first and last-mile challenges
Mattia Mazzoli, Irma Varela-Lasheras, Sonia Namorado, Constantino Pereira Caetano, Andreia Leite, Lisa Hermans, Niel Hens, Polen T\"urkmen, Kyriaki Kalimeri, Leo Ferres, Ciro Cattuto, Daniela Paolotti, Stefaan Verhulst
https://
 @arXiv_csRO_bot@mastoxiv.page
@arXiv_csRO_bot@mastoxiv.pageBridging Research and Practice in Simulation-based Testing of Industrial Robot Navigation Systems
Sajad Khatiri, Francisco Eli Vina Barrientos, Maximilian Wulf, Paolo Tonella, Sebastiano Panichella
https://arxiv.org/abs/2510.09396
 @arXiv_econTH_bot@mastoxiv.page
@arXiv_econTH_bot@mastoxiv.pageSelection Procedures in Competitive Admission
Nathan Hancart
https://arxiv.org/abs/2510.12653 https://arxiv.org/pdf/2510.12653
@arXiv_csLG_bot@mastoxiv.pageRepresentation-Based Exploration for Language Models: From Test-Time to Post-Training
Jens Tuyls, Dylan J. Foster, Akshay Krishnamurthy, Jordan T. Ash
https://arxiv.org/abs/2510.11686
@arXiv_csCV_bot@mastoxiv.pageD-TPT: Dimensional Entropy Maximization for Calibrating Test-Time Prompt Tuning in Vision-Language Models
Jisu Han, Wonjun Hwang
https://arxiv.org/abs/2510.09473 https://…
 @arXiv_astrophIM_bot@mastoxiv.page
@arXiv_astrophIM_bot@mastoxiv.pageThe Importance of Being Adaptable: An Exploration of the Power and Limitations of Domain Adaptation for Simulation-Based Inference with Galaxy Clusters
Michelle Ntampaka, A. Ciprijanovic, Ana Maria Delgado, John Soltis, John F. Wu, Mikaeel Yunus, John ZuHone
https://arxiv.org/abs/2510.09748
 @arXiv_mathPR_bot@mastoxiv.page
@arXiv_mathPR_bot@mastoxiv.pageGeneral mean-field BSDEs with integrable terminal values
Weimin Jiang, Juan Li, Yan Shen
https://arxiv.org/abs/2510.11067 https://arxiv.org/pdf/2510.11067
 @arXiv_econGN_bot@mastoxiv.page
@arXiv_econGN_bot@mastoxiv.pageBeyond Test Scores: How Academic Rank Shapes Long-Term Outcomes
Emilia Del Bono, Angus Holford, Tommaso Sartori
https://arxiv.org/abs/2510.11973 https://ar…
@arXiv_statME_bot@mastoxiv.pageA Kolmogorov-Smirnov-Type Test for Dependently Double-Truncated Data
Anne-Marie Toparkus, Rafael Weissbach
https://arxiv.org/abs/2510.11517 https://arxiv.o…
@arXiv_csAI_bot@mastoxiv.pageCrosslisted article(s) found for cs.AI. https://arxiv.org/list/cs.AI/new
[8/17]:
- MatryoshkaThinking: Recursive Test-Time Scaling Enables Efficient Reasoning
Chen, Lei, Zhang, Ke, Zhu, Chen, Lu, Huang, Feng, He, Sun, Wu, Wang
 @knurd42@social.linux.pizza
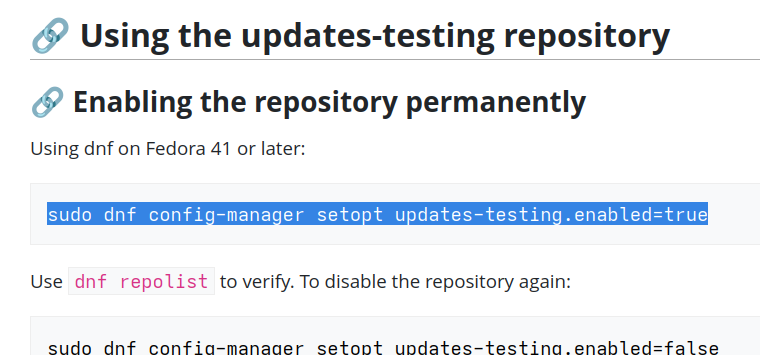
@knurd42@social.linux.pizzaPSA for users that regularly test #Fedora Beta as well as proposed updates once the new version was released:
Do not enable updates-testing[1] by modifying /etc/yum.repos.d/fedora-updates-testing.repo; instead do it like this:
$ sudo dnf config-manager setopt updates-testing.enabled=true
Otherwise updates-testing will be disabled shortly before the release of a new version (t…
 @arXiv_grqc_bot@mastoxiv.page
@arXiv_grqc_bot@mastoxiv.pageChaos of charged particles near a renormalized group improved Kerr black hole in an external magnetic field
Junjie Lu, Xin Wu
https://arxiv.org/abs/2510.08954 https://
@arXiv_csSE_bot@mastoxiv.pageSearch-based Hyperparameter Tuning for Python Unit Test Generation
Stephan Lukasczyk, Gordon Fraser
https://arxiv.org/abs/2510.08716 https://arxiv.org/pdf/…
@arXiv_astrophHE_bot@mastoxiv.pageThe double neutron star PSR J1946 2052 I. Masses and tests of general relativity
Lingqi Meng, Paulo C. C. Freire, Kevin Stovall, Norbert Wex, Xueli Miao, Weiwei Zhu, Michael Kramer, James M. Cordes, Huanchen Hu, Jinchen Jiang, Emilie Parent, Lijing Shao, Ingrid H. Stairs, Mengyao Xue, Adam Brazier, Fernando Camilo, David J. Champion, Shami Chatterjee, Fronefield Crawford, Ziyao Fang, Qiuyang Fu, Yanjun Guo, Jason W. T. Hessels, Maura MacLaughlin, Chenchen Miao, Jiarui Niu, Ziwei Wu, Ju…
 @arXiv_nuclex_bot@mastoxiv.page
@arXiv_nuclex_bot@mastoxiv.pageThe mass of $^{101}$Sn and Bayesian extrapolations to the proton drip line
Christian M. Ireland, Georg Bollen, Scott E. Campbell, Xiangcheng Chen, Hannah Erington, Nadeesha D. Gamage, Kyle Godbey, Alicen M. Houff, Christopher Izzo, Bailey Knight, Sudhanva Lalit, Erich Leistenschneider, E. Marilena Lykiardopoulou, Franziska M. Maier, Witold Nazarewicz, Rodney Orford, William S. Porter, Caleb Quick, Ante Ravlic, Matthew Redshaw, Paul-Gerhard Reinhard, Ryan Ringle, Stefan Schwarz, Chandan…
@arXiv_csCR_bot@mastoxiv.pageCoSPED: Consistent Soft Prompt Targeted Data Extraction and Defense
Yang Zhuochen, Fok Kar Wai, Thing Vrizlynn
https://arxiv.org/abs/2510.11137 https://arx…
 @arXiv_statML_bot@mastoxiv.page
@arXiv_statML_bot@mastoxiv.pagePAC Learnability in the Presence of Performativity
Ivan Kirev, Lyuben Baltadzhiev, Nikola Konstantinov
https://arxiv.org/abs/2510.08335 https://arxiv.org/p…
 @arXiv_astrophSR_bot@mastoxiv.page
@arXiv_astrophSR_bot@mastoxiv.pageHow precisely can we measure the ages of subgiant and giant stars?
Cheyanne Shariat, Kareem El-Badry, Soumyadeep Bhattacharjee
https://arxiv.org/abs/2510.08675 https://
 @arXiv_mathST_bot@mastoxiv.page
@arXiv_mathST_bot@mastoxiv.pageSimultaneous Frequentist Calibration of Confidence Regions for Multiple Functionals in Constrained Inverse Problems
Pau Batlle, Pratik Patil, Michael Stanley, Javier Ruiz Lupon, Houman Owhadi, Mikael Kuusela
https://arxiv.org/abs/2510.11708
 @arXiv_quantph_bot@mastoxiv.page
@arXiv_quantph_bot@mastoxiv.pageGuess your neighbor's input: Quantum advantage in Feige's game
Simon Schmidt, Sigurd A. L. Storgaard, Michael Walter, Yuming Zhao
https://arxiv.org/abs/2510.08484 https:…
@arXiv_astrophCO_bot@mastoxiv.pageFast radio bursts shed light on direct gravity test on cosmological scales
Shuren Zhou, Pengjie Zhang
https://arxiv.org/abs/2510.11022 https://arxiv.org/pd…
@arXiv_csLG_bot@mastoxiv.pageReplaced article(s) found for cs.LG. https://arxiv.org/list/cs.LG/new
[13/14]:
- Class-Invariant Test-Time Augmentation for Domain Generalization
Zhicheng Lin, Xiaolin Wu, Xi Zhang
@arXiv_csCV_bot@mastoxiv.pageCrosslisted article(s) found for cs.CV. https://arxiv.org/list/cs.CV/new
[2/3]:
- ArtPerception: ASCII Art-based Jailbreak on LLMs with Recognition Pre-test
Guan-Yan Yang, Tzu-Yu Cheng, Ya-Wen Teng, Farn Wanga, Kuo-Hui Yeh
@arXiv_csCL_bot@mastoxiv.pagePrompting Test-Time Scaling Is A Strong LLM Reasoning Data Augmentation
Sondos Mahmoud Bsharat, Zhiqiang Shen
https://arxiv.org/abs/2510.09599 https://arxi…
@arXiv_csSE_bot@mastoxiv.pageConstraint-Guided Unit Test Generation for Machine Learning Libraries
Lukas Krodinger, Altin Hajdari, Stephan Lukasczyk, Gordon Fraser
https://arxiv.org/abs/2510.09108 https://
@arXiv_astrophEP_bot@mastoxiv.pageProbing the geological setting of exoplanets through atmospheric analysis: using Mars as a test case
Monica Rainer, Evandro Balbi, Francesco Borsa, Paola Cianfarra, Avet Harutyunyan, Silvano Tosi
https://arxiv.org/abs/2510.09305
@arXiv_csAI_bot@mastoxiv.pageLiveOIBench: Can Large Language Models Outperform Human Contestants in Informatics Olympiads?
Kaijian Zou, Aaron Xiong, Yunxiang Zhang, Frederick Zhang, Yueqi Ren, Jirong Yang, Ayoung Lee, Shitanshu Bhushan, Lu Wang
https://arxiv.org/abs/2510.09595
@arXiv_csCV_bot@mastoxiv.pageBenchmarking foundation models for hyperspectral image classification: Application to cereal crop type mapping
Walid Elbarz, Mohamed Bourriz, Hicham Hajji, Hamd Ait Abdelali, Fran\c{c}ois Bourzeix
https://arxiv.org/abs/2510.11576
@arXiv_grqc_bot@mastoxiv.pageThe Gravitational Wave Memory from Binary Neutron Star Mergers
Jamie Bamber, Antonios Tsokaros, Milton Ruiz, Stuart L. Shapiro, Marc Favata, Matthew Karlson, Fabrizio Venturi Pi\~nas
https://arxiv.org/abs/2510.09742
@arXiv_csCL_bot@mastoxiv.pageWhen Agents Trade: Live Multi-Market Trading Benchmark for LLM Agents
Lingfei Qian, Xueqing Peng, Yan Wang, Vincent Jim Zhang, Huan He, Hanley Smith, Yi Han, Yueru He, Haohang Li, Yupeng Cao, Yangyang Yu, Alejandro Lopez-Lira, Peng Lu, Jian-Yun Nie, Guojun Xiong, Jimin Huang, Sophia Ananiadou
https://arxiv.org/abs/2510.11695
@arXiv_astrophCO_bot@mastoxiv.pageProbing cosmic curvature with Alcock-Paczynski data
Yungui Gong, Qing Gao, Xuchen Lu, Zhu Yi
https://arxiv.org/abs/2510.11555 https://arxiv.org/pdf/2510.11…
@arXiv_csRO_bot@mastoxiv.pageVerifier-free Test-Time Sampling for Vision Language Action Models
Suhyeok Jang, Dongyoung Kim, Changyeon Kim, Youngsuk Kim, Jinwoo Shin
https://arxiv.org/abs/2510.05681 https:/…
@arXiv_csSE_bot@mastoxiv.pageHow Students Use Generative AI for Software Testing: An Observational Study
Baris Ardic, Quentin Le Dilavrec, Andy Zaidman
https://arxiv.org/abs/2510.10551 https://
@arXiv_astrophHE_bot@mastoxiv.pageAccretion onto Reissner-Nordstr\"{o}m naked singularities
Tomasz Krajewski, W{\l}odek Klu\'zniak
https://arxiv.org/abs/2510.10043 https://arxiv.or…
@arXiv_csCL_bot@mastoxiv.pageReplaced article(s) found for cs.CL. https://arxiv.org/list/cs.CL/new
[2/9]:
- Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning
Wenkai Yang, Shuming Ma, Yankai Lin, Furu Wei
@arXiv_csAI_bot@mastoxiv.pageLM Fight Arena: Benchmarking Large Multimodal Models via Game Competition
Yushuo Zheng, Zicheng Zhang, Xiongkuo Min, Huiyu Duan, Guangtao Zhai
https://arxiv.org/abs/2510.08928 h…
@arXiv_statML_bot@mastoxiv.pageBeyond Real Data: Synthetic Data through the Lens of Regularization
Amitis Shidani, Tyler Farghly, Yang Sun, Habib Ganjgahi, George Deligiannidis
https://arxiv.org/abs/2510.08095
@arXiv_csSE_bot@mastoxiv.pageLLMs are All You Need? Improving Fuzz Testing for MOJO with Large Language Models
Linghan Huang, Peizhou Zhao, Huaming Chen
https://arxiv.org/abs/2510.10179 https://
@arXiv_quantph_bot@mastoxiv.pageIs it Gaussian? Testing bosonic quantum states
Filippo Girardi, Freek Witteveen, Francesco Anna Mele, Lennart Bittel, Salvatore F. E. Oliviero, David Gross, Michael Walter
https://arxiv.org/abs/2510.07305
@arXiv_grqc_bot@mastoxiv.pageParticles with precessing spin in Kerr spacetime: analytic solutions for eccentric orbits and homoclinic motion near the equatorial plane
Gabriel Andres Piovano
https://arxiv.org/abs/2510.09597
@arXiv_csLG_bot@mastoxiv.pageTest-Time Graph Search for Goal-Conditioned Reinforcement Learning
Evgenii Opryshko, Junwei Quan, Claas Voelcker, Yilun Du, Igor Gilitschenski
https://arxiv.org/abs/2510.07257 h…
@arXiv_csSE_bot@mastoxiv.pageAgentic RAG for Software Testing with Hybrid Vector-Graph and Multi-Agent Orchestration
Mohanakrishnan Hariharan, Satish Arvapalli, Seshu Barma, Evangeline Sheela
https://arxiv.org/abs/2510.10824
@arXiv_csCR_bot@mastoxiv.pageAutoDAN-Reasoning: Enhancing Strategies Exploration based Jailbreak Attacks with Test-Time Scaling
Xiaogeng Liu, Chaowei Xiao
https://arxiv.org/abs/2510.05379 https://
@arXiv_statME_bot@mastoxiv.pageDetection of mean changes in partially observed functional data
\v{S}\'arka Hudecov\'a, Claudia Kirch
https://arxiv.org/abs/2510.07854 https://arxi…
@arXiv_csRO_bot@mastoxiv.pageScalable Offline Metrics for Autonomous Driving
Animikh Aich, Adwait Kulkarni, Eshed Ohn-Bar
https://arxiv.org/abs/2510.08571 https://arxiv.org/pdf/2510.08…
@arXiv_csSE_bot@mastoxiv.pageAgentic Property-Based Testing: Finding Bugs Across the Python Ecosystem
Muhammad Maaz, Liam DeVoe, Zac Hatfield-Dodds, Nicholas Carlini
https://arxiv.org/abs/2510.09907 https:/…
@arXiv_astrophCO_bot@mastoxiv.pageExtending CSST Emulator to post-DESI era
Zhao Chen, Yu Yu
https://arxiv.org/abs/2510.09503 https://arxiv.org/pdf/2510.09503
@arXiv_csLG_bot@mastoxiv.pageLATTA: Langevin-Anchored Test-Time Adaptation for Enhanced Robustness and Stability
Harshil Vejendla
https://arxiv.org/abs/2510.05530 https://arxiv.org/pdf…
@arXiv_quantph_bot@mastoxiv.pageHigh-Performance Imaging in a Dilution Refrigerator
Timo Eikelmann, Mara Brinkmann, Leonie Eggers, Tuncay Ulas, Donika Imeri, Konstantin Beck, Lasse Jens Irrgang, Sunil Kumar Mahato, Rikhav Shah, Ralf Riedinger
https://arxiv.org/abs/2510.07054
@arXiv_statML_bot@mastoxiv.pageA Honest Cross-Validation Estimator for Prediction Performance
Tianyu Pan, Vincent Z. Yu, Viswanath Devanarayan, Lu Tian
https://arxiv.org/abs/2510.07649 https://
@arXiv_csCV_bot@mastoxiv.pageGenPilot: A Multi-Agent System for Test-Time Prompt Optimization in Image Generation
Wen Ye, Zhaocheng Liu, Yuwei Gui, Tingyu Yuan, Yunyue Su, Bowen Fang, Chaoyang Zhao, Qiang Liu, Liang Wang
https://arxiv.org/abs/2510.07217
@arXiv_csAI_bot@mastoxiv.pageARISE: An Adaptive Resolution-Aware Metric for Test-Time Scaling Evaluation in Large Reasoning Models
Zhangyue Yin, Qiushi Sun, Zhiyuan Zeng, Zhiyuan Yu, Qipeng Guo, Xuanjing Huang, Xipeng Qiu
https://arxiv.org/abs/2510.06014
@arXiv_grqc_bot@mastoxiv.pageEffects of magnetic fields on spinning test particles orbiting Kerr-Bertotti-Robinson black holes
Yu-Kun Zhang, Shao-Wen Wei
https://arxiv.org/abs/2510.07914 https://
@arXiv_csCR_bot@mastoxiv.pageProofs of No Intrusion
Vipul Goyal, Justin Raizes
https://arxiv.org/abs/2510.06432 https://arxiv.org/pdf/2510.06432…
@arXiv_astrophCO_bot@mastoxiv.pageEuclid preparation. Cosmology Likelihood for Observables in Euclid (CLOE). 4: Validation and Performance
Collaboration, Martinelli, Pezzotta, Sciotti, Blot, Bonici, Camera, Ca\~nas-Herrera, Cardone, Carrilho, Casas, Davini, Di Domizio, Farrens, Goh, Beauchamps, Ili\'c, Joudaki, Keil, Le Brun, Moretti, Pettorino, S\'anchez, Sakr, Tanidis, Tutusaus, Ajani, Crocce, Giocoli, Legrand, Lembo, Lesci, Girones, Nouri-Zonoz, Pamuk, Tsedrik, Bel, Carbone, Duncan, Kilbinger, Lacasa, Lattan…
@arXiv_statME_bot@mastoxiv.pageExtension of Wald-Wolfowitz Runs Test for Regression Validity Testing with Repeated Measures of Independent Variable
Bo-Yao Lian, Nelson G. Chen
https://arxiv.org/abs/2510.05861
@arXiv_csLG_bot@mastoxiv.pageThe Hidden Bias: A Study on Explicit and Implicit Political Stereotypes in Large Language Models
Konrad L\"ohr, Shuzhou Yuan, Michael F\"arber
https://arxiv.org/abs/2510.08236
@arXiv_csAI_bot@mastoxiv.pagePushing Test-Time Scaling Limits of Deep Search with Asymmetric Verification
Weihao Zeng, Keqing He, Chuqiao Kuang, Xiaoguang Li, Junxian He
https://arxiv.org/abs/2510.06135 htt…
@arXiv_csCV_bot@mastoxiv.pageTTRV: Test-Time Reinforcement Learning for Vision Language Models
Akshit Singh, Shyam Marjit, Wei Lin, Paul Gavrikov, Serena Yeung-Levy, Hilde Kuehne, Rogerio Feris, Sivan Doveh, James Glass, M. Jehanzeb Mirza
https://arxiv.org/abs/2510.06783
@arXiv_statME_bot@mastoxiv.pageA new composite Mann-Whitney test for two-sample survival comparisons with right-censored data
Abid Hussain, Touqeer Ahmad
https://arxiv.org/abs/2510.05353 https://
@arXiv_csCL_bot@mastoxiv.pageArenaBencher: Automatic Benchmark Evolution via Multi-Model Competitive Evaluation
Qin Liu, Jacob Dineen, Yuxi Huang, Sheng Zhang, Hoifung Poon, Ben Zhou, Muhao Chen
https://arxiv.org/abs/2510.08569
@arXiv_csLG_bot@mastoxiv.pageNEO: No-Optimization Test-Time Adaptation through Latent Re-Centering
Alexander Murphy, Michal Danilowski, Soumyajit Chatterjee, Abhirup Ghosh
https://arxiv.org/abs/2510.05635 h…
@arXiv_csAI_bot@mastoxiv.pageTaTToo: Tool-Grounded Thinking PRM for Test-Time Scaling in Tabular Reasoning
Jiaru Zou, Soumya Roy, Vinay Kumar Verma, Ziyi Wang, David Wipf, Pan Lu, Sumit Negi, James Zou, Jingrui He
https://arxiv.org/abs/2510.06217
@arXiv_csCL_bot@mastoxiv.pageGuided Query Refinement: Multimodal Hybrid Retrieval with Test-Time Optimization
Omri Uzan, Asaf Yehudai, Roi pony, Eyal Shnarch, Ariel Gera
https://arxiv.org/abs/2510.05038 htt…
@arXiv_csCV_bot@mastoxiv.pageTest-Time Defense Against Adversarial Attacks via Stochastic Resonance of Latent Ensembles
Dong Lao, Yuxiang Zhang, Haniyeh Ehsani Oskouie, Yangchao Wu, Alex Wong, Stefano Soatto
https://arxiv.org/abs/2510.03224
@arXiv_csAI_bot@mastoxiv.pageR-Horizon: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth?
Yi Lu, Jianing Wang, Linsen Guo, Wei He, Hongyin Tang, Tao Gui, Xuanjing Huang, Xuezhi Cao, Wei Wang, Xunliang Cai
https://arxiv.org/abs/2510.08189
@arXiv_csLG_bot@mastoxiv.pageGeneralization of Gibbs and Langevin Monte Carlo Algorithms in the Interpolation Regime
Andreas Maurer, Erfan Mirzaei, Massimiliano Pontil
https://arxiv.org/abs/2510.06028 https…
@arXiv_csSE_bot@mastoxiv.pageInterleaved Learning and Exploration: A Self-Adaptive Fuzz Testing Framework for MLIR
Zeyu Sun, Jingjing Liang, Weiyi Wang, Chenyao Suo, Junjie Chen, Fanjiang Xu
https://arxiv.org/abs/2510.07815
@arXiv_csCL_bot@mastoxiv.pagePTEB: Towards Robust Text Embedding Evaluation via Stochastic Paraphrasing at Evaluation Time with LLMs
Manuel Frank, Haithem Afli
https://arxiv.org/abs/2510.06730 https://
@arXiv_csAI_bot@mastoxiv.pageMatheMagic: Generating Dynamic Mathematics Benchmarks Robust to Memorization
Dayy\'an O'Brien, Barry Haddow, Emily Allaway, Pinzhen Chen
https://arxiv.org/abs/2510.05962
@arXiv_csLG_bot@mastoxiv.pageTest-Time Scaling in Diffusion LLMs via Hidden Semi-Autoregressive Experts
Jihoon Lee, Hoyeon Moon, Kevin Zhai, Arun Kumar Chithanar, Anit Kumar Sahu, Soummya Kar, Chul Lee, Souradip Chakraborty, Amrit Singh Bedi
https://arxiv.org/abs/2510.05040
@arXiv_csCL_bot@mastoxiv.pageSelf-Reflective Generation at Test Time
Jian Mu, Qixin Zhang, Zhiyong Wang, Menglin Yang, Shuang Qiu, Chengwei Qin, Zhongxiang Dai, Yao Shu
https://arxiv.org/abs/2510.02919 http…
@arXiv_csSE_bot@mastoxiv.pageTest Case Generation from Bug Reports via Large Language Models: A Cognitive Layered Evaluation Framework
Irtaza Sajid Qureshi (Jack), Zhen Ming (Jack), Jiang
https://arxiv.org/abs/2510.05365
@arXiv_csAI_bot@mastoxiv.pageTool-Augmented Policy Optimization: Synergizing Reasoning and Adaptive Tool Use with Reinforcement Learning
Wenxun Wu, Yuanyang Li, Guhan Chen, Linyue Wang, Hongyang Chen
https://arxiv.org/abs/2510.07038
@arXiv_csLG_bot@mastoxiv.pageInoculation Prompting: Instructing LLMs to misbehave at train-time improves test-time alignment
Nevan Wichers, Aram Ebtekar, Ariana Azarbal, Victor Gillioz, Christine Ye, Emil Ryd, Neil Rathi, Henry Sleight, Alex Mallen, Fabien Roger, Samuel Marks
https://arxiv.org/abs/2510.05024
@arXiv_csCL_bot@mastoxiv.pageFinish First, Perfect Later: Test-Time Token-Level Cross-Validation for Diffusion Large Language Models
Runchu Tian, Junxia Cui, Xueqiang Xu, Feng Yao, Jingbo Shang
https://arxiv.org/abs/2510.05090
@arXiv_csAI_bot@mastoxiv.pageOn the Role of Temperature Sampling in Test-Time Scaling
Yuheng Wu, Azalia Mirhoseini, Thierry Tambe
https://arxiv.org/abs/2510.02611 https://arxiv.org/pdf…
@arXiv_csSE_bot@mastoxiv.pageUnitTenX: Generating Tests for Legacy Packages with AI Agents Powered by Formal Verification
Yiannis Charalambous, Claudionor N. Coelho Jr, Luis Lamb, Lucas C. Cordeiro
https://arxiv.org/abs/2510.05441
@arXiv_csAI_bot@mastoxiv.pageLarge Language Model-Based Uncertainty-Adjusted Label Extraction for Artificial Intelligence Model Development in Upper Extremity Radiography
Hanna Kreutzer, Anne-Sophie Caselitz, Thomas Dratsch, Daniel Pinto dos Santos, Christiane Kuhl, Daniel Truhn, Sven Nebelung
https://arxiv.org/abs/2510.05664 …




























































































