 @Mediagazer@mstdn.social
@Mediagazer@mstdn.social2026-02-14 00:11:01
While announcing its sports buildup, Banner EIC Audrey Cooper noted the civic value: "At a time when so much pulls communities apart, sports bring us together" (Dan Kennedy/Media Nation)
https://dankennedy.net/2026/02/13/why-

 @smashtie@mas.to
@smashtie@mas.to2026-02-08 13:45:18
It was a revelation to see Nigerian Modernism at the Tate, especially seeing the rooms full of people who clearly felt a strong, personal connection to the work. Here are some of my favourites.
#Art



 @catsalad@infosec.exchange
@catsalad@infosec.exchange2026-02-15 07:10:00
:crt_w_test_pattern: ᵃᵃᵃᵃᵃᵃᵃᵃᵃ

 @gray17@mastodon.social
@gray17@mastodon.social2026-04-01 15:39:22
april fool's product "AI pet for your AI companion" has a video that shows various options for the pet: corgi, kitten, snake, toaster, Punch-Kun (the macaque with a plush orangutan), and "Lynx the Blue Fox" shown here

 @samvarma@fosstodon.org
@samvarma@fosstodon.org2026-02-13 22:54:36
The office couple nights ago. The historic Indiana Roof Ballroom, Indianapolis. Over 100 years old, it was once one of America's most prestigious ballrooms and hosted the greatest big bands including Benny Goodman and Cab Calloway 😳 Stunning place!

 @burger_jaap@mastodon.social
@burger_jaap@mastodon.social2026-03-10 15:14:42
What I think Germany is doing right for public HDV charging:
- Early grid applications w/ forward-looking capacity
- Not one electricity price, but many. How do you give users access to these?
- Tenders for the best offer for the user, not recouping costs later with high prices
https://www.



 @kexpmusicbot@mastodonapp.uk
@kexpmusicbot@mastodonapp.uk2026-04-09 13:23:09
🇺🇦 #NowPlaying on KEXP's #Early
DJ HARRISON:
🎵 The Floyd
#DJHARRISON
https://djharrison.bandcamp.com/track/the-floyd
https://open.spotify.com/track/0lNW2Znd7msM8Z1eg9sddf
Please 🔁 BOOST to share what you like
- your followers don't see if you ⭐ favourite a post
 @azonenberg@ioc.exchange
@azonenberg@ioc.exchange2026-01-31 07:44:34
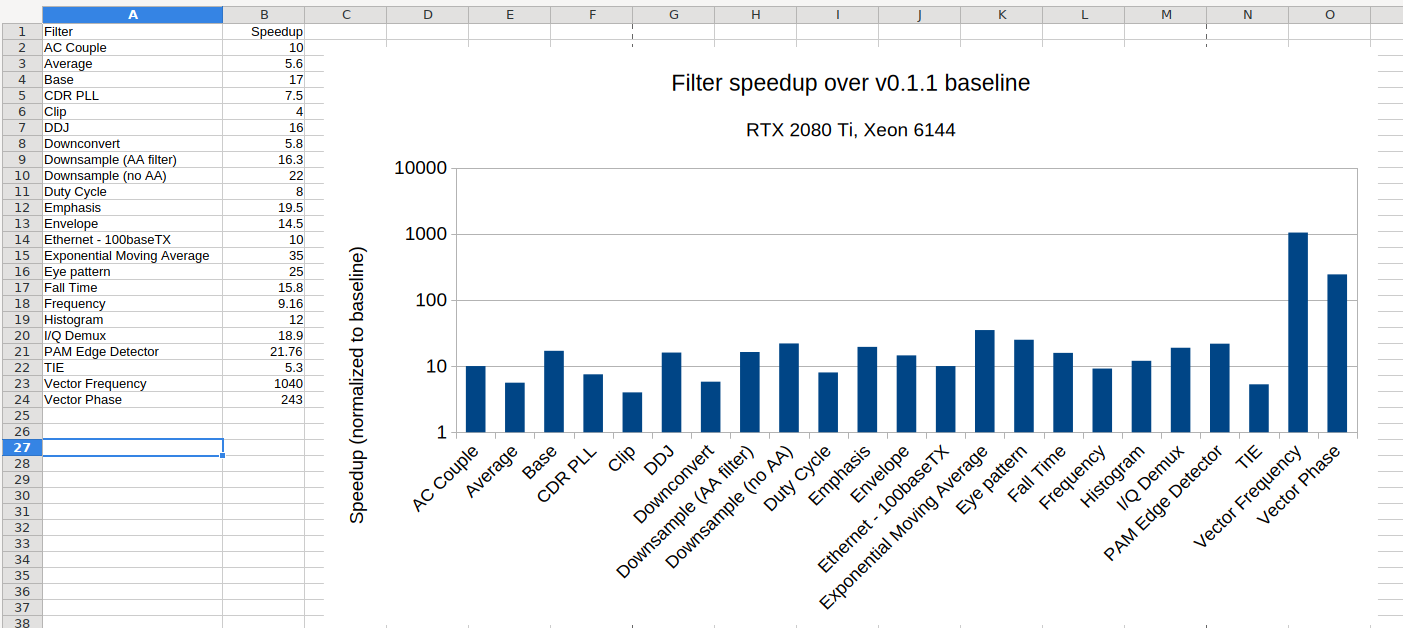
Another evening of filter refactoring and optimization, a few more nice performance jumps.
I've now done a first pass (remove deprecated method signatures, add explicit input location, add NVTX trace data, do easy GPU optimization if I see an obvious low effort win) on all filters A-F alphabetically plus a few later on that were priorities for one reason or other.
90 down (of which 23 were optimized and the rest just refactored), 115 to go.
Some of the remaining ones sh…
 @blakes7bot@mas.torpidity.net
@blakes7bot@mas.torpidity.net2026-01-26 18:22:51
Series C, Episode 08 - Rumours of Death
TARRANT: You're offering to let her go. That's not the same thing.
AVON: What are you talking about?
https://blake.torpidity.net/m/308/510 B7B4

 @Erikmitk@mastodon.gamedev.place
@Erikmitk@mastodon.gamedev.place2026-02-07 17:47:32
„That’s three or four clicks just to see the error, and every one of them loads a new page with its own loading spinner, and none of them are fast. You are navigating a bureaucracy. You are filling out forms at the DMV of CI.“
What an apt comparison. The whole piece is *chef’s kiss*!
https://www.