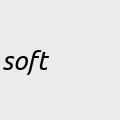@mia@hcommons.social
@mia@hcommons.social2025-08-19 13:42:42
On small, local language models: 'In a world increasingly dominated by massive models and opaque APIs, we believe there’s still room for small, transparent, controllable systems. Models you can fine-tune, understand and run on your own terms' https://www.turing.ac.uk…