 @matthiasott@mastodon.social
@matthiasott@mastodon.social2026-04-26 06:45:57
Aaand off to #btconf! 🎉🥳
(And of course it’s proper @… weather™ ☀️)
See you later in Düsseldorf!

 @servelan@newsie.social
@servelan@newsie.social2026-03-26 01:37:09
At Pentagon Christian service, Hegseth prays for violence ‘against those who deserve no mercy’ | AP News
https://apnews.com/article/pete-hegseth-pentagon-christian-worship-service-30db48b6ceb8af5e6172fb3ba2eafaa0
 @Kingu@sakurajima.moe
@Kingu@sakurajima.moe2026-04-25 09:24:19
Why read the Gospels when you can just play the first-person shooter of it!

 @cyrevolt@mastodon.social
@cyrevolt@mastodon.social2026-03-25 23:24:28
have some @… on a T580

 @doebeli@mastodon.social
@doebeli@mastodon.social2026-03-26 16:53:35
Digitale Lernplattformen sind nicht neutral.
Seit heute öffentlich verfügbar: Unser Bericht "Digitale Lernplattformen in der Volksschule: Chancen, Herausforderungen und Auswirkungen auf Lehren und Lernen" im Auftrag der Deutschschweizer Volksschulämterkonferenz (DVK)
https://doi.org/10.5281/zenodo.17558569

 @socallinuxexpo@social.linux.pizza
@socallinuxexpo@social.linux.pizza2026-02-26 18:05:02
Ray Paik will speak on 'Companies vs. Foundations: Who Should Steer Your Open Source Project?' as part of our General track at SCaLE 23x. Full details: https://www.socallinuxexpo.org/scale/23x

 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.page2026-02-25 10:42:41
Scaling Vision Transformers: Evaluating DeepSpeed for Image-Centric Workloads
Huy Trinh, Rebecca Ma, Zeqi Yu, Tahsin Reza
https://arxiv.org/abs/2602.21081 https://arxiv.org/pdf/2602.21081 https://arxiv.org/html/2602.21081
arXiv:2602.21081v1 Announce Type: new
Abstract: Vision Transformers (ViTs) have demonstrated remarkable potential in image processing tasks by utilizing self-attention mechanisms to capture global relationships within data. However, their scalability is hindered by significant computational and memory demands, especially for large-scale models with many parameters. This study aims to leverage DeepSpeed, a highly efficient distributed training framework that is commonly used for language models, to enhance the scalability and performance of ViTs. We evaluate intra- and inter-node training efficiency across multiple GPU configurations on various datasets like CIFAR-10 and CIFAR-100, exploring the impact of distributed data parallelism on training speed, communication overhead, and overall scalability (strong and weak scaling). By systematically varying software parameters, such as batch size and gradient accumulation, we identify key factors influencing performance of distributed training. The experiments in this study provide a foundational basis for applying DeepSpeed to image-related tasks. Future work will extend these investigations to deepen our understanding of DeepSpeed's limitations and explore strategies for optimizing distributed training pipelines for Vision Transformers.
toXiv_bot_toot
 @aral@mastodon.ar.al
@aral@mastodon.ar.al2026-02-24 06:47:40
I’m just happy they’re not making self-driving cars.
 @tydalforce@mastodon.world
@tydalforce@mastodon.world2026-04-25 12:54:36
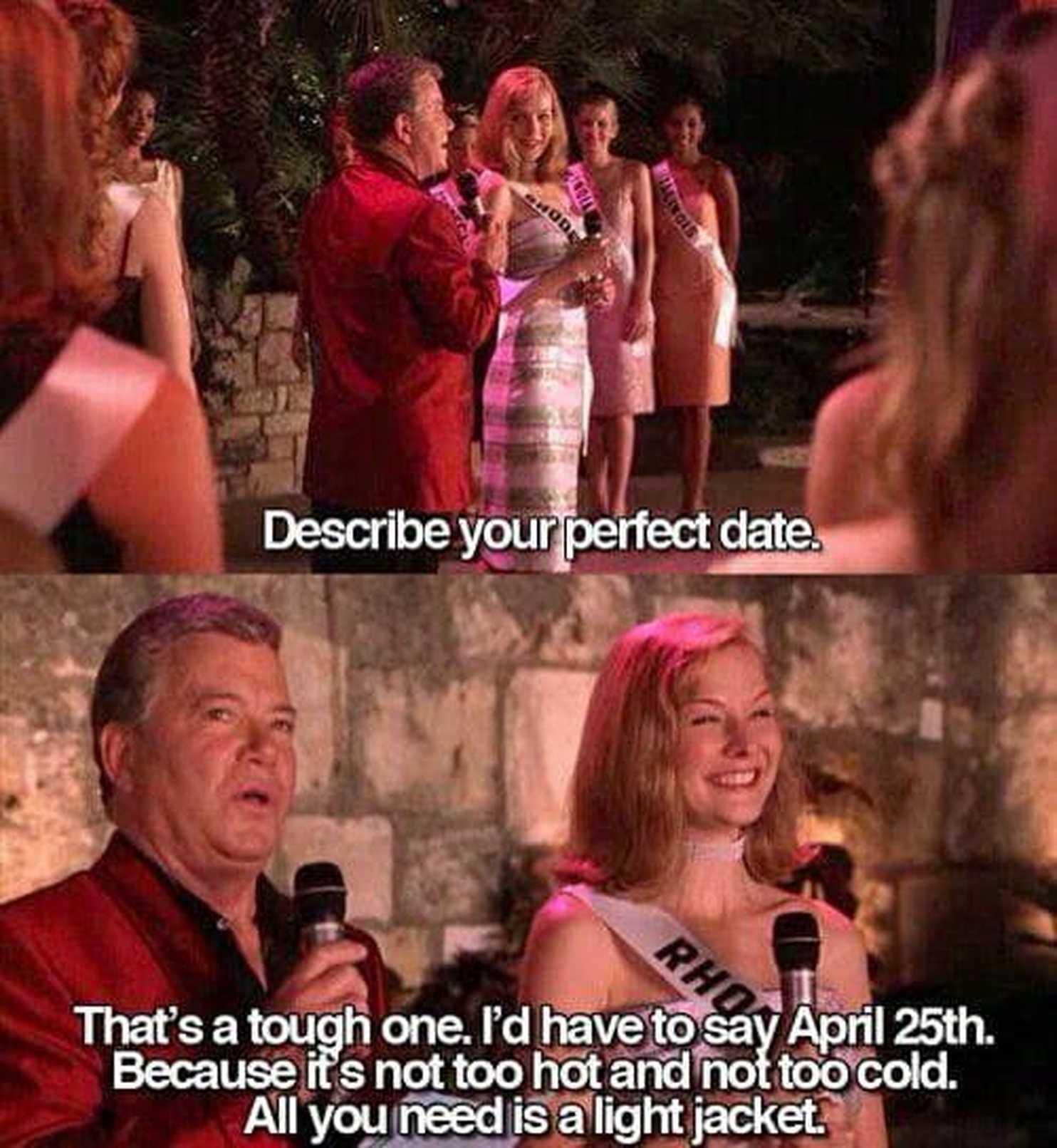
Happy Perfect Date Day!
#april25 #perfectDate
 @Techmeme@techhub.social
@Techmeme@techhub.social2026-02-25 23:31:05
Alphabet's Intrinsic, which builds AI models and software for industrial robots, joins Google; it will remain a distinct entity and work with Google DeepMind (Rebecca Szkutak/TechCrunch)
https://techcrunch.com/2026/02/25/alphabet-owned-r…
