 @kubikpixel@chaos.social
@kubikpixel@chaos.social2026-07-29 06:05:22
AraOwl — Test your web knowledge
Test and sharpen your web platform knowledge with quizzes built straight from MDN Web Docs. Study anywhere — quizzes work fully offline once installed.
🧑💻 https://araowl.schalkneethling.com

 @v_i_o_l_a@openbiblio.social
@v_i_o_l_a@openbiblio.social2026-06-29 05:49:08
"How Can Nonprofit Presses Advance the Diamond Ecosystem?"
https://katinamagazine.org/content/article/open-knowledge/2026/how-nonprofit-presses-can-advance-diamond-oa
"Earlier this year, three nonprofit…
 @burger_jaap@mastodon.social
@burger_jaap@mastodon.social2026-06-29 14:42:33
Flexible Connection Agreements can help to connect new loads to the grid before firm capacity is available.
But that does require proper oversight: although beggars can’t be choosers when it comes to grid access, the regulator certainly can.
New RAP briefing on Europe's hope for unlocking grids.
https://www.

 @toxi@mastodon.thi.ng
@toxi@mastodon.thi.ng2026-05-30 10:10:35
Seven Social Sins
Wealth without work.
Pleasure without conscience.
Knowledge without character.
Commerce without morality.
Science without humanity.
Worship without sacrifice.
Politics without principle.
— Frederick Lewis Donaldson
https://en.wikipedia.org/wiki/Seven_So
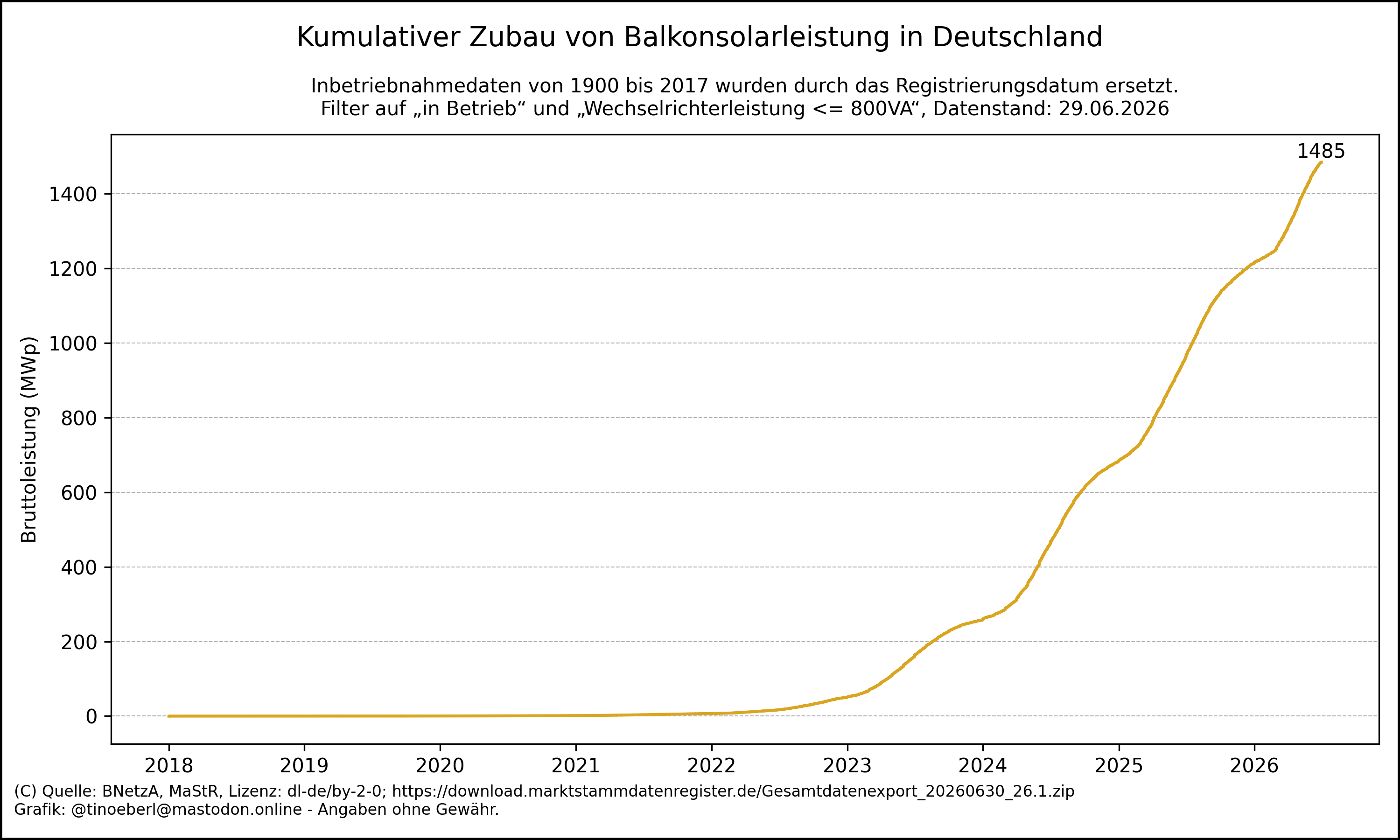
 @tinoeberl@mastodon.online
@tinoeberl@mastodon.online2026-06-30 20:22:02
Kumulativer Zubau von #Balkonsolarleistung in #Deutschland mit Stand vom 29.06.2026.
Die summierte Leistung aller offiziell registrierten #Steckersolaranlagen beträgt b…
 @Techmeme@techhub.social
@Techmeme@techhub.social2026-07-30 13:15:58
Sources: TSMC is developing advanced AI chip packaging tech, internally called "EMIB-like", similar to Intel's Embedded Multi-die Interconnect Bridge technique (Qianer Liu/The Information)
https://www.theinformation.com/articles/tsmc-d…

 @jake4480@c.im
@jake4480@c.im2026-07-30 01:15:25
We were watching this show the other day and several people seemed unsure as to how to spell 'phlegm'. I realized that after listening to all the metal that I do with 'phlegm' in both all kinds of band names and song titles, I knew exactly how. Different funds of knowledge. You just never know when the dumb crap you know will be useful.
@Techmeme@techhub.social2026-06-30 01:20:45
Sources: AI video startup Higgsfield is in talks to raise $300M to $500M at a $5B pre-money valuation, more than 4x its valuation in a January 2026 round (The Information)
https://www.theinformation.com/articles/ai-video-startup-talks-quadruple-va…
 @Techmeme@techhub.social
@Techmeme@techhub.social2026-07-29 13:15:54
Source: OpenRouter was recently generating ~$140M in annualized revenue, or ~$12M per month, up nearly 3x since April, making Stripe's $10B offer a big premium (The Information)
https://www.theinformation.com/articles/openrouter-…
