@tiotasram@kolektiva.social
@tiotasram@kolektiva.social2026-05-26 11:36:22
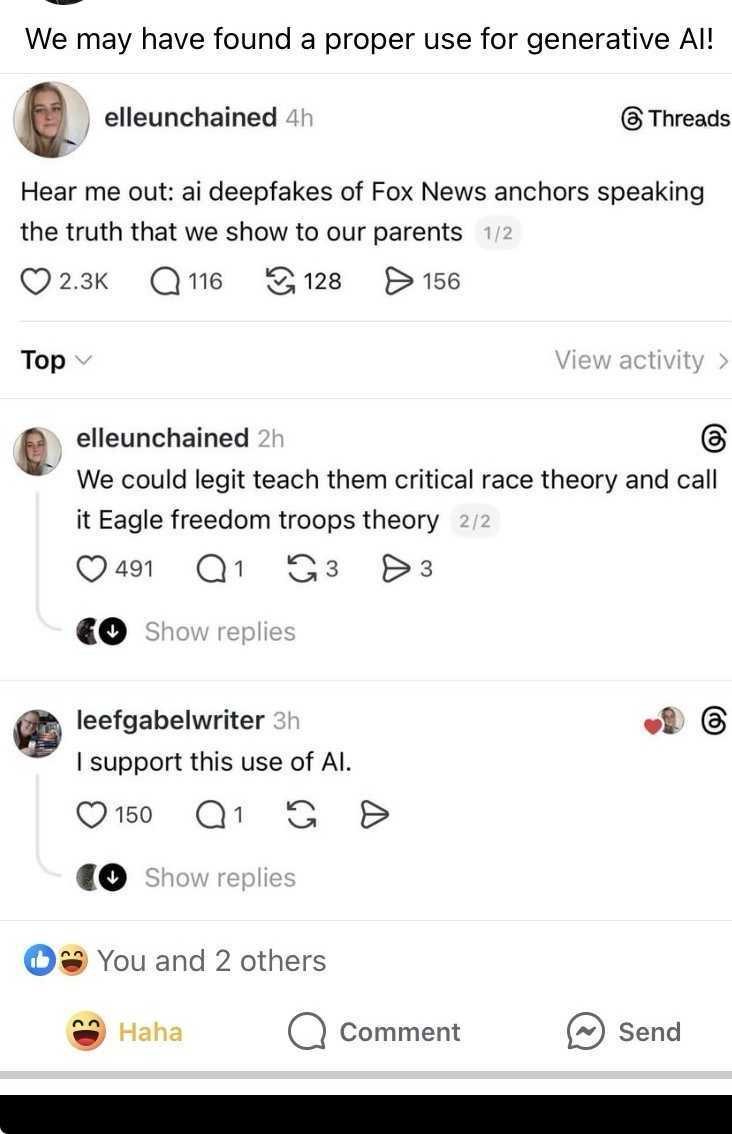
Are you in tech and outraged about generative AI? Is it being forced down your throat at work?
Here's a nice vindictive way to get a little revenge if you want:
1. Find a project that contains slop code.
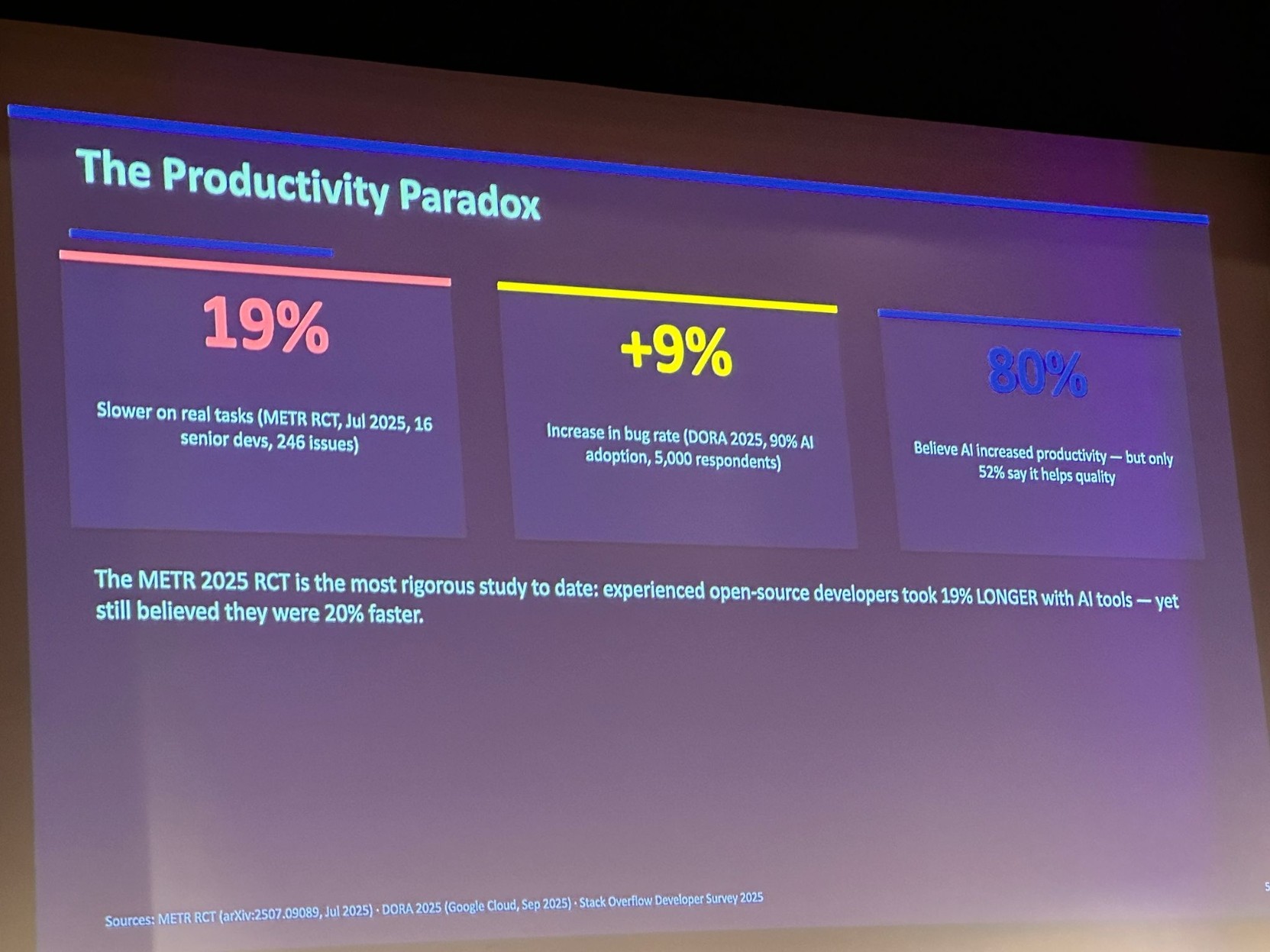
2. Optionally, identify specific files or functions that are LLM-generated. I guarantee you that on average, this code has not been adequately tested/inspected, even/especially if it contains LLM-generated test cases.
3. Make up a reason the code could be flawed, bonus points if it's subtle or hard to test. Don't put effort into this or try to actually find a flaw. Just make something up at random.
4. Report your made-up defect as a bug.
That's it. If anyone ever questions you on the incorrect report, just say "oh I used an LLM and it said there was a bug so I reported it." (Don't actually use an LLM, that would be feeding the bubble.)
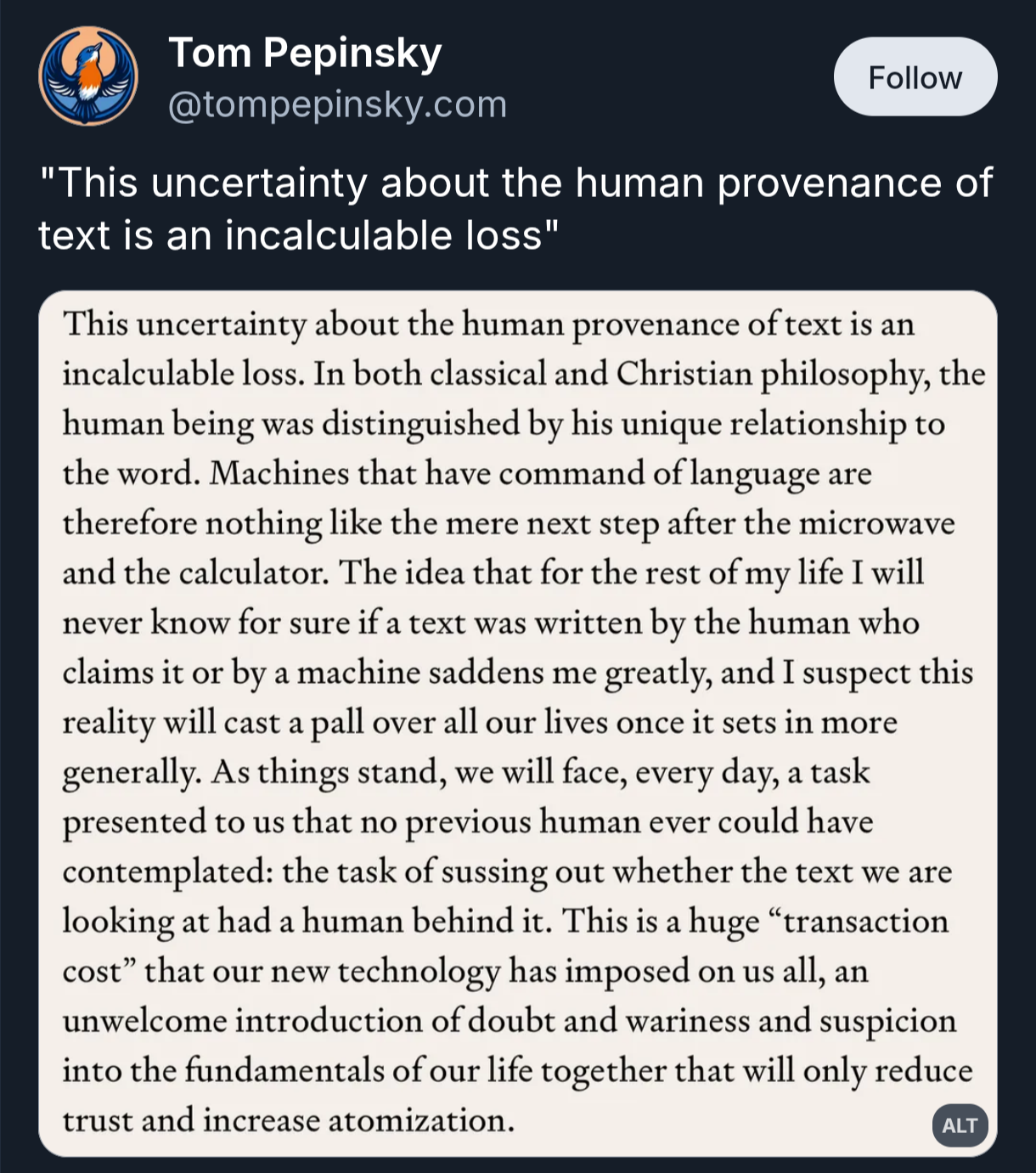
Note that you are showing the creator of the code the exact same amount of disrespect that they've shown you by publishing slopcode in the first place. I'd bet odds are 50:50 or better that if a human actually follows up on the report, even though they'll find out that the bug report is wrong, they'll find and fix some other subtle flaw in the LLM-generated code, so this is actually helpful in a way.
For step 3, try to get creative. Like "logic in decideUVParameters can cause state to be inconsistent in some cases." If asked for a steps to reproduce, either make one up if it's easy to do so, or say "I forgot how I triggered this." Surely they can ask an LLM to figure out conditions that would trigger the bug ;).
#AI #LLMs #GenAI