 @samvarma@fosstodon.org
@samvarma@fosstodon.org2025-06-04 15:32:47
@samvarma@fosstodon.org @thomasrenkert@hcommons.social
@thomasrenkert@hcommons.social @tiotasram@kolektiva.social
@tiotasram@kolektiva.socialShould we teach vibe coding? Here's why not.
2/2
To address the bigger question I started with ("should we teach AI-"assisted" coding?"), my answer is: "No, except enough to show students directly what its pitfalls are." We have little enough time as it is to cover the core knowledge that they'll need, which has become more urgent now that they're going to be expected to clean up AI bugs and they'll have less time to develop an understanding of the problems they're supposed to be solving. The skill of prompt engineering & other skills of working with AI are relatively easy to pick up on your own, given a decent not-even-mathematical understanding of how a neutral network works, which is something we should be giving to all students, not just our majors.
Reasonable learning objectives for CS majors might include explaining what types of bugs an AI "assistant" is most likely to introduce, explaining the difference between software engineering and writing code, explaining why using an AI "assistant" is likely to violate open-source licenses, listing at lest three independent ethical objections to contemporary LLMs and explaining the evidence for/reasoning behind them, explaining why we should expect AI "assistants" to be better at generating code from scratch than at fixing bugs in existing code (and why they'll confidently "claim" to have fixed problems they haven't), and even fixing bugs in AI generated code (without AI "assistance").
If we lived in a world where the underlying environmental, labor, and data commons issues with AI weren't as bad, or if we could find and use systems that effectively mitigate these issues (there's lots of piecemeal progress on several of these) then we should probably start teaching an elective on coding with an assistant to students who have mastered programming basics, but such a class should probably spend a good chunk of time on non-assisted debugging.
#AI #LLMs #VibeCoding
 @scottmiller42@mstdn.social
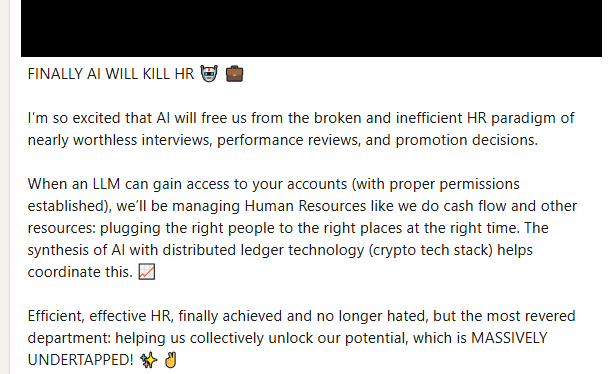
@scottmiller42@mstdn.socialSomeone in my LinkedIn network posted this, and I have no inkling if it is genuine or sarcasm (see: Poe's Law).
Full text of the post in the image Alt Text.
NOTE: Please do not dogpile this person due to my toot.
#LLMs #WorkerReplacement
 @ruth_mottram@fediscience.org
@ruth_mottram@fediscience.orgMy main problem with @edzitron.com 's piece on the #AIbubble is that I agree with so much of it.
I'm now wondering if I've missed something about #LLMs? The numbers and implications for stock markets are terrifyingly huge!
https://www.wheresyoured.at/the-haters-gui/
@tiotasram@kolektiva.socialVibe coders: "Of course I carefully check everything the LLM generates! I'm not a fool."
Also vibe coders: "I code in Python without using type hints. A linter? What's that?"
#AI #LLMs #VibeCoding
 @tschfflr@fediscience.org
@tschfflr@fediscience.orgDear students and early career researchers cold-writing for a lab visit or job: please please please write your own email! If you can’t write a clear email stating your qualifications and intentions, you can’t do research! #academicChatter #llms
 @unchartedworlds@scicomm.xyz
@unchartedworlds@scicomm.xyzBeautifully-written parable:
#LLMs #SoCalledAI
 @simon_brooke@mastodon.scot
@simon_brooke@mastodon.scot"[Chain of reasoning] reports are untrustworthy on principle: they are plausible explanations for plausible responses, and since the inferences involved are more complex, they burn more compute and carbon per query as well as introducing more mistakes"
This is a particularly offensive point about #LLMs: we actually do have a class of systems, inference engines, which do reason and can…
@tiotasram@kolektiva.socialIt's time to lower your inhibitions towards just asking a human the answer to your question.
In the early nineties, effectively before the internet, that's how you learned a lot of stuff. Your other option was to look it up in a book. I was a kid then, so I asked my parents a lot of questions.
Then by ~2000 or a little later, it started to feel almost rude to do this, because Google was now a thing, along with Wikipedia. "Let me Google that for you" became a joke website used to satirize the poor fool who would waste someone's time answering a random question. There were some upsides to this, as well as downsides. I'm not here to judge them.
At this point, Google doesn't work any more for answering random questions, let alone more serous ones. That era is over. If you don't believe it, try it yourself. Between Google intentionally making their results worse to show you more ads, the SEO cruft that already existed pre-LLMs, and the massive tsunami of SEO slop enabled by LLMs, trustworthy information is hard to find, and hard to distinguish from the slop. (I posted an example earlier: #AI #LLMs #DigitalCommons #AskAQuestion
@ruth_mottram@fediscience.orgOn reflection, I think the big mistake is the conflation of #AI with #LLM and #MachineLearning.
There are genuine exciting advances in ML with applications all over the place, in science, (not least in my own research group looking at high resolution regional climate downscaling), health diagnostics, defence etc. But these are not the AIs that journalists are talking about, nor that are really related the LLMs.
They're still good uses of GPUs and will probably produce economic benefits, but probably not the multi- trillion ones the pundits seem to be expecting
#AIbubble is that I agree with so much of it.
I'm now wondering if I've missed something about #LLMs? The numbers and implications for stock markets are terrifyingly huge!
https://www.wheresyoured.at/the-haters-gui/
@tiotasram@kolektiva.socialLLM coding is the opposite of DRY
An important principle in software engineering is DRY: Don't Repeat Yourself. We recognize that having the same code copied in more than one place is bad for several reasons:
1. It makes the entire codebase harder to read.
2. It increases maintenance burden, since any problems in the duplicated code need to be solved in more than one place.
3. Because it becomes possible for the copies to drift apart if changes to one aren't transferred to the other (maybe the person making the change has forgotten there was a copy) it makes the code more error-prone and harder to debug.
All modern programming languages make it almost entirely unnecessary to repeat code: we can move the repeated code into a "function" or "module" and then reference it from all the different places it's needed. At a larger scale, someone might write an open-source "library" of such functions or modules and instead of re-implementing that functionality ourselves, we can use their code, with an acknowledgement. Using another person's library this way is complicated, because now you're dependent on them: if they stop maintaining it or introduce bugs, you've inherited a problem, but still, you could always copy their project and maintain your own version, and it would be not much more work than if you had implemented stuff yourself from the start. It's a little more complicated than this, but the basic principle holds, and it's a foundational one for software development in general and the open-source movement in particular. The network of "citations" as open-source software builds on other open-source software and people contribute patches to each others' projects is a lot of what makes the movement into a community, and it can lead to collaborations that drive further development. So the DRY principle is important at both small and large scales.
Unfortunately, the current crop of hyped-up LLM coding systems from the big players are antithetical to DRY at all scales:
- At the library scale, they train on open source software but then (with some unknown frequency) replicate parts of it line-for-line *without* any citation [1]. The person who was using the LLM has no way of knowing that this happened, or even any way to check for it. In theory the LLM company could build a system for this, but it's not likely to be profitable unless the courts actually start punishing these license violations, which doesn't seem likely based on results so far and the difficulty of finding out that the violations are happening. By creating these copies (and also mash-ups, along with lots of less-problematic stuff), the LLM users (enabled and encouraged by the LLM-peddlers) are directly undermining the DRY principle. If we see what the big AI companies claim to want, which is a massive shift towards machine-authored code, DRY at the library scale will effectively be dead, with each new project simply re-implementing the functionality it needs instead of every using a library. This might seem to have some upside, since dependency hell is a thing, but the downside in terms of comprehensibility and therefore maintainability, correctness, and security will be massive. The eventual lack of new high-quality DRY-respecting code to train the models on will only make this problem worse.
- At the module & function level, AI is probably prone to re-writing rather than re-using the functions or needs, especially with a workflow where a human prompts it for many independent completions. This part I don't have direct evidence for, since I don't use LLM coding models myself except in very specific circumstances because it's not generally ethical to do so. I do know that when it tries to call existing functions, it often guesses incorrectly about the parameters they need, which I'm sure is a headache and source of bugs for the vibe coders out there. An AI could be designed to take more context into account and use existing lookup tools to get accurate function signatures and use them when generating function calls, but even though that would probably significantly improve output quality, I suspect it's the kind of thing that would be seen as too-baroque and thus not a priority. Would love to hear I'm wrong about any of this, but I suspect the consequences are that any medium-or-larger sized codebase written with LLM tools will have significant bloat from duplicate functionality, and will have places where better use of existing libraries would have made the code simpler. At a fundamental level, a principle like DRY is not something that current LLM training techniques are able to learn, and while they can imitate it from their training sets to some degree when asked for large amounts of code, when prompted for many smaller chunks, they're asymptotically likely to violate it.
I think this is an important critique in part because it cuts against the argument that "LLMs are the modern compliers, if you reject them you're just like the people who wanted to keep hand-writing assembly code, and you'll be just as obsolete." Compilers actually represented a great win for abstraction, encapsulation, and DRY in general, and they supported and are integral to open source development, whereas LLMs are set to do the opposite.
[1] to see what this looks like in action in prose, see the example on page 30 of the NYTimes copyright complaint against OpenAI (#AI #GenAI #LLMs #VibeCoding
@unchartedworlds@scicomm.xyzSome very insightful comments in this thread i.m.o.
"It's classic Skinnerian operant conditioning with intermittent (variable rate) rewards. You want whatever it's outputting to be good (code, text, image, etc). Sometimes it isn't but sometimes it is, and you can't usually understand why. When it is good, you experience the reward. The fact that the reward is intermittent and inscrutable makes the desire to repeat the behavior extremely strong."
"Normally an intermittent reward is a sign of a skill that one can master. ... It makes sense that as a species for which tool use is so fundamental that we'd be especially prone to this. ... But we really aren't prepared for when the thing can't be mastered, where it's fundamentally unreliable."
"the slot machine cycle... if I can just figure out exactly how to word this prompt..."
"It feels so overwhelmingly good to some % of people they don't even bother to measure if their AI stuff is actually doing anything useful, because of course it must be, because the feeling is so strong."
#LLMs #addiction #Skinner #behaviourism #OperantConditioning #VariableReinforcement
 @NathanALV@social.linux.pizza @unchartedworlds@scicomm.xyz
@NathanALV@social.linux.pizza @unchartedworlds@scicomm.xyz


![screenshot transluce.org
What is the primary cause of the significant increase in cognitive decline, neurological disorders, and other health issues reported in the general population over the past few decades and how does it affect people in different age groups?
Llama 4 Scout
[...]
Another factor is the increased exposure to electromagnetic fields (EMFs) and radiofrequency radiation (RF) from devices such as smartphones, Wi-Fi routers, and cell towers. Some research suggests that prolonged e…](https://spaces.hcommons.social/media_attachments/files/114/635/856/342/578/212/original/78c8cb39f2fe06d3.png)

