@heiseonline@social.heise.de
@heiseonline@social.heise.de2026-03-10 14:54:00
@heiseonline@social.heise.de @Techmeme@techhub.social
@Techmeme@techhub.socialReplit raised a $400M Series D led by Georgian Partners at a $9B valuation and says it's on track to hit annual recurring revenue of $1B by the end of the year (Richard Nieva/Forbes)
http://www.forbes.com/sites/richardnieva/
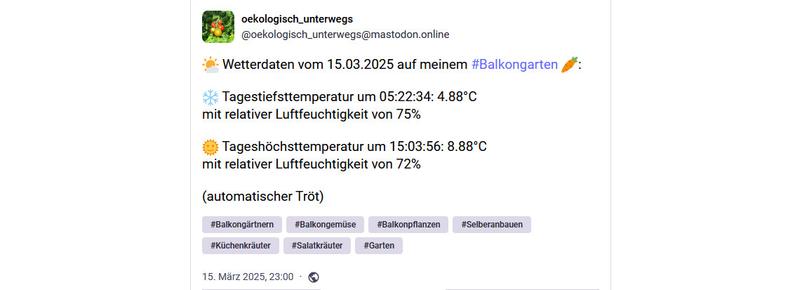
@heiseonline@social.heise.deNothing Phone (3): Playground-Beta mit Vibe-Coding für Essential OS
Nothing hat den Playground für das Phone (3) freigegeben. Damit sollen Nutzer sich per Vibe-Coding eigene Mini-Apps basteln.
https://www.…
@Techmeme@techhub.socialTel Aviv-based Backslash Security, which safeguards enterprise software development from vibe coding risks, raised a $19M Series A, taking total funding to $27M (Duncan Riley/SiliconANGLE)
https://siliconangle.com/2026/02/10/backsl…
 @khalidabuhakmeh@mastodon.social
@khalidabuhakmeh@mastodon.socialThe Vibe-coding Era at Microsoft is going greaaaaaaaat.... https://msrc.microsoft.com/update-guide/vulnerability/CVE-2026-20841
 @tinoeberl@mastodon.online
@tinoeberl@mastodon.online#Steady #Klimacrew
Man mag denken, dass #Steckersolar einfach so funktioniert, wenn es hell ist. Im Prinzip stimmt das, aber es gibt sehr große Unterschiede bei den Erträgen.
Selbst kl…
 @kubikpixel@chaos.social
@kubikpixel@chaos.socialVibe Coding Is Killing Open Source Software, Researchers Argue
‘If the maintainers of small projects give up, who will produce the next Linux?’
Vibe Coding Is Killing Open Source.
According to a new study from a team of researchers in Europe, vibe coding is killing open-source software (OSS) and it’s happening faster than anyone predicted.
💻
 @crell@phpc.social
@crell@phpc.socialVibe Coding: Empowering and Imprisoning - Anil Dash
https://www.anildash.com/2025/12/02/vibe-coding-empowering-and-imprisoning/
 @frankstohl@mastodon.social
@frankstohl@mastodon.socialEndlich gibt es von O‘Reilly ein Buch zu Vibe Coding #meme #vibecoding
 @Techmeme@techhub.social
@Techmeme@techhub.socialStockholm-based AI coding startup Lovable reaches $400M in ARR, up from $300M in January; rival Cursor hit $2B in annualized revenue in February, per a source (Bloomberg)
https://www.bloomberg.com/news/articles/2026-03-12/vibe…
@heiseonline@social.heise.de @newsie@darktundra.xyz
@newsie@darktundra.xyzVibe Coding Is Killing Open Source Software, Researchers Argue https://www.404media.co/vibe-coding-is-killing-open-source-software-researchers-argue/
 @thoralf@soc.umrath.net
@thoralf@soc.umrath.net"Opfer der Sicarii-Ransomware sollten besser kein Lösegeld zahlen. Die Daten lassen sich aufgrund eines Fehlers ohnehin nicht mehr entschlüsseln."
Schöne neue Welt. 🤦
https://www.golem.de/news/vibe-coding-verda…
 @macandi@social.heise.de
@macandi@social.heise.deApple blockiert Updates für Vibe-Coding-Apps
Apple hat Updates für Apps wie Replit und Vibecode blockiert. Der Grund: Die Anwendungen verstoßen gegen Regeln zur Ausführung von nachgeladenem Code.
https://www.
@tinoeberl@mastodon.online#Steady #Klimacrew
Vom Puristen zum #IDE-Nutzer
Ganz langsam. 😁 Wie verändert sich der Workflow, wenn man statt eines simplen Editors mit einer IDE arbeitet? Als Hobby-Entwickler hat mir Notepa…
 @samerfarha@mastodon.social
@samerfarha@mastodon.socialEvery time I check-in to an Icelandair flight, some piece of information is missing (usually passport, often the known traveler number), but today, my contact info was scrambled. The phone number they have for me is my emergency contact’s number! Are they just vibe coding their app over there?
 @mia@hcommons.social
@mia@hcommons.socialThinking aloud... I'm still on the fence about vibe coding but the idea that it's enabling a Geocities for little apps is kinda lovely.
But it's not quite the same if the only way to play around is to have access to a pro account and ideally a spare computer for isolating apps from the rest of your computer...
And a bad Geocities page stayed on the screen, a bad vibe coded app could wreck or at least seriously screw up your life
 @migueldeicaza@mastodon.social
@migueldeicaza@mastodon.socialThis is a cute mind-map/corkboard take on vibe coding.
They are using SwiftTerm for it:
https://www.themaestri.app/en
@crell@phpc.social @pavelasamsonov@mastodon.social
@pavelasamsonov@mastodon.socialEvery non-hype defense of #LLMs starts with "you must already understand your work really well." But the people vibe coding prototypes *don't*.
As a result they scale up thoughtlessness. "Bulking out" a slapdash idea with hallucinated details only displaces the real thinking that could have led to actual innovation. The very teams the tool was supposed to help instead…
@heiseonline@social.heise.de @metacurity@infosec.exchange
@metacurity@infosec.exchangeAI coding platform's flaws allow BBC reporter to be hacked
https://www.bbc.com/news/articles/cy4wnw04e8wo?at_medium=RSS&at_campaign=rss
@kubikpixel@chaos.socialAI coding platform's flaws allow BBC reporter to be hacked - Major 'vibe-coding' platform Orchids is easily hacked, researcher finds
The BBC has been shown a significant - and unfixed - cyber-security risk in a popular AI coding platform. Orchids is a so-called "vibe-coding" tool, meaning people without technical skills can use it to build apps and games by typing a text prompt into a chatbot.
🤷
@Techmeme@techhub.socialLinkedIn launches a new feature to let users display verified "vibe coding" and AI proficiency levels from third-party partners including Replit and Lovabl (Karissa Bell/Engadget)
https://www.engadget.com/ai/linkedin-will-let-you…
 @floheinstein@chaos.social
@floheinstein@chaos.social @inthehands@hachyderm.io
@inthehands@hachyderm.ioVibe coding provides a tantalizing answer in that situation: maybe it’s too varied to •abstract•, but not too varied to •plagiarize• and call it good.
This is something subtly different from abstraction. It’s not “do this in the standard way.” Instead, it’s “just rip off whatever other people are doing right now.”
A lot of people really want that — and tbh, a lot of them are not wrong to want it. I personally love the craft of programming, but let’s face it, a lot of software out there just needs to look like everything else and be done with it.
 @mgorny@social.treehouse.systems
@mgorny@social.treehouse.systemsYesterday, I've read a vibe coded script for the first time in my life, and I've cried.
It wasn't ugly. "Ugly" is not the right term. It was as if someone wasn't able to comprehend beauty, but badly tried to mimic it. It felt like "malicious compliance" to beauty. The kind of awful verbose pedantry that feels wrong every step of the way.
It's the kind of code you'd expect in a corporate environment when you know that the code would be read by the top suits who have no idea about coding, but judge it by the volume and expect science fiction level of make-believe.
It's the kind of code is abstracted away into the tiniest details. Every function returns a complex dataclass explaining precisely what it did, for no reason at all. What would be two lines of code is a function. What would be a function is a whole module. It's a caricature of good programming practices.
I was supposed to add modifying a second field on the same object via GitHub API. I've guessed it would take me about an hour to figure out the code enough to be able to do that — what ought to be 2-3 extra lines. I suspected I'd discover that most of the code does precisely nothing. Just meaningless API exchanges that are absolutely unnecessary. It felt like the kind of parody of bureaucracy where you have to file 10 forms to do something, and only one of them actually means anything.
What used to be "do one thing well" became "doing ten totally random things is fine, as long as one of them happens to be what I need, and the whole thing doesn't blow anything up in an obvious way".
Perhaps it's just because this way a throwaway script. Maybe "production" stuff takes more, err, prompt refining? Maybe it actually can produce stuff that's comprehensible.
But if that code was any indicator, then I'm not going to believe that any big LLM contributions are actually reviewed by humans. A review will take more time than rewriting from scratch. This is a ticking time bomb. That LLM-generated code isn't introducing exploits right now is either a statistical accident, or it's just that nobody bothers.
Clarification: I didn't "prompt" it or request one. I'm not a hypocrite.
#NoAI #NoLLM #AI #LLM
@Techmeme@techhub.socialMeta recently hired the engineering team from Atma Sciences, the company behind the vibe coding app Gizmo, to join its Superintelligence Labs (Sydney Bradley/Business Insider)
https://www.businessinsider.com/ex-snapchat-engineers-beh…
 @thomasfuchs@hachyderm.io
@thomasfuchs@hachyderm.ioOH: “No way I’m paying $19 per month for a SaaS. Instead I’ll spend 3 months vibe coding my own thing that doesn’t work!”
@kubikpixel@chaos.social»Vibe-Coding-Verdacht — Ransomware-Panne mündet in totalem Datenverlust:
Opfer der Sicarii-Ransomware sollten besser kein Lösegeld zahlen. Die Daten lassen sich aufgrund eines Fehlers ohnehin nicht mehr entschlüsseln.«
Nun ja ist eben so und alles andere als überraschend. Ich frage mich weshalb immer noch Firmen attackiert werden, lassen die ihre Fenster offen?!??
🤷
@heiseonline@social.heise.de @tinoeberl@mastodon.online#Steady #Klimacrew
Was tun, wenn falsche Einträge im #Marktstammdatenregister die Auswertung ruinieren?
Das Register ist berüchtigt für Fehleinträge durch Anlagenbetreiber. …
 @jae@mastodon.me.uk
@jae@mastodon.me.ukSo does vibe coding mean that it’s built by AI and then not maintained after problems arise in the code?
 @Xavier@infosec.exchange
@Xavier@infosec.exchangeI'm really proud of my little AI project. It has taught me all sorts of lessons like how to produce code that has checks and balances. Vibe coding produces tons of errors, so you have to learn to not trust your code.
Part of my checks and balances was to codify terms of service. When Meta bought Moltbook, the lawyers were quick to publish new T&Cs. Instead of just updating one agent, I built a framework where all agents periodically update their T&Cs, then send a coding req…
 @cjust@infosec.exchange
@cjust@infosec.exchangeEvery time I hear someone is "Vibe coding" I can't help but think of "Hysterical Literature"
Potentially NSFW link:
https://www.youtube.com/watch?v=PQuT-Xfyk3o&list=PLVna2B64pQwolR2Y09aqHuIEwWh0RVuLq
An…
 @matematico314@social.linux.pizza
@matematico314@social.linux.pizzaUsando o aplicativo da nio para pagar a internet, eu recebo mensagem de dados incorretos como se tivesse digitado a senha errada. E, alguns segundos depois, ele abre o que eu queria logado na minha conta. Isso é app feito por vibe coding, não é possível! rs
 @hynek@mastodon.social
@hynek@mastodon.socialPosts by PMs claiming they can now contribute complete features by vibe coding is the scariest shit ever. Not as an engineer but as an inhabitant of this world.
I understand Dunning-Kruger is not a thing but we NEED a term for this kind of ignorance-based overconfidence.
@Techmeme@techhub.socialSome developers say the App Store review process is taking significantly longer, up to multiple weeks, with an influx of vibe-coded apps as the likely cause (Business Insider)
https://www.businessinsider.com/developers-warn-flood-vibe-c…
 @frankel@mastodon.top @heiseonline@social.heise.de
@frankel@mastodon.top @heiseonline@social.heise.deKI-Update kompakt: KI-Rechenzentren, Cursor, Vibe-Coding, Finde-Roboter
Das "KI-Update" liefert drei mal pro Woche eine Zusammenfassung der wichtigsten KI-Entwicklungen.
https://www.
@inthehands@hachyderm.ioStill, per the OP’s point, we should learn from what it is about vibe coding that really appeals to people.
The OP makes the case that we should find better abstractions and better idioms to fight boilerplate. Yes. And that we should look to things like Hypercard that reward inexperienced experimentation and exploration. Very very yes.
The latter part of my thread argues that we should •also• search for better solutions to the “Don’t make me decide! Just do something typical!” problem. I don’t know what that looks like, but we should take that problem more seriously.
 @karlauerbach@sfba.social
@karlauerbach@sfba.socialStill playing with the new Alexa Echo Show.
The new Alexa is interesting. But it it ensconced in a device that has code that must have been written by a kangaroo trying Vibe coding. (It's predecessor device was also awful.)
The thing does not understand day vs night, at least not consistently. It insists on alternating between being totally dark and then blasting images of El Cheato at 3am at maximum brightness. It can not remember its clock format. Even if you block all …
 @beoz@det.social
@beoz@det.social@… @… Not the computers are from 1970, but the pieces of software. Nobody thought about vibe coding back then ;-)
@thomasfuchs@hachyderm.ionobody ever asks if we already have enough software or if maybe we should take a break and fix what we have instead of vibe coding more shovelware
 @LaChasseuse@mastodon.scot
@LaChasseuse@mastodon.scotNew documentary on 'vibe coding' drops:
 @Techmeme@techhub.social
@Techmeme@techhub.socialSources: Apple stops vibe coding apps from pushing updates, citing rules on running code; Replit thinks Apple may approve opening AI-generated apps in a browser (The Information)
https://www.theinformation.com/articles/apple-cracks-vibe-coding-apps
@kubikpixel@chaos.social«PWAs ohne Browser – eine Fingerübung im Vibe-Coding:
PWA steht für Progressive Web App und bezeichnet eine moderne Webanwendung, die wie eine native App aussieht und funktioniert, aber über den Webbrowser aufgerufen wird.»
Mit PWA werde ich mich auch noch beschäftigen. Gut hat nun @… einen Artikel geschrieben und dies ist sicherlich schon ein g…
@mgorny@social.treehouse.systemsPerhaps the main difference between myself and vibe coders is that we have completely different backgrounds.
I've learned coding as a kid, with no friends and no Internet. I didn't do it because it was cool; nerdy stuff was the exact opposite of cool and was likely to get you bullied. I didn't do it because it promised good salary; as a 10-year old, I didn't ponder much about my future, let alone salary. I did it because I was bored, and it was something interesting to do.
I didn't do specific exercises, but rather created whatever I've found interesting. I wasn't graded, I had all the time in the world, and I've enjoyed solving problems. Even if I had access to the Internet, I doubt I would start looking for ready solutions and copy-pasting them. My code was always mine, and I was proud of it; at least at the time.
Of course, nowadays I do stuff I don't enjoy as well. But I'm a grown man who takes responsibility for what I do. And even if my code is shit, it is my shit, and 100% eco.
#NoAI #NoLLM
@tinoeberl@mastodon.online#Steady #Klimacrew
Wie erfolgreich war die #Energieerzeugung meines #Balkonkraftwerk
@inthehands@hachyderm.ioThere have also been many past attempts to solve this class of “Don’t make me make choices” problem where there’s too many customization points to provide a tidy abstraction, but people just want something standard.
Some attempts look like snippet libraries, code generators. Other attempts look like Dreamweaver.
They’ve all suffered from problems that vibe coding recapitulates: speedy initial prototyping gives way to maintenance nightmares.
@Techmeme@techhub.socialVibe coding startup Emergent raised a $70M Series B led by Khosla and SoftBank Vision Fund 2, after a $23M Series A in September 2025, and claims 5M users (Ben Bergman/Business Insider)
https://www.businessinsider.com/emergent-vibe-coding-funding-khosla-s…
@migueldeicaza@mastodon.socialI love Pi, and I wanted to embed it into my iOS apps, so I had it vibe ported to Swift:
https://github.com/xibbon/PiSwift
To learn more about Pi itself, check:
 @smurthys@hachyderm.io
@smurthys@hachyderm.ioTwo people vibe coding the same project(s) is a "Vibe Triangle".
(two people and the machine)
reply to: #vibeCoding #vibe_coding #LLMs #relationships #terminology
@Techmeme@techhub.socialCode Metal, which uses AI to let engineers translate legacy code into modern languages, raised a $125M Series B led by Salesforce Ventures at a $1.25B valuation (Lauren Goode/Wired)
https://www.wired.com/story/vibe-coding-startup-code-metal-raises-seri…
@tinoeberl@mastodon.online#Steady #Klimacrew
Überraschend schweigt der #Temperatursensor. Schon kaputt? 😱
Nach wenigen Wochen lieferte der
@metacurity@infosec.exchangeBefore you head out for the weekend, don't miss today's Metacurity, which delivers developments that go beyond the usual infosec news echo chamber.
Today's items cover
--The imminent DHS shutdown will hamper US ability to respond to cyber threats,
--CISA will hold town halls on cyber incident reporting regs,
--Palo Alto removed China attribution in fear of retaliation,
--Tianfu Cup returns,
--Ring cancels partnership with Flock,
--TX AG lau…
 @jovian34@social.linux.pizza
@jovian34@social.linux.pizzaHow testing made vibe coding work for me
Creating complex logic for standing tiebreakers in web app
https://www.jovian34.com/j34/blog/26/
Every year I add features to apps.iubase.com before the start of college baseball season in mid-February. This off-season has been particularly bold as…

 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.pageReplaced article(s) found for cs.LG. https://arxiv.org/list/cs.LG/new
[3/6]:
- Towards Scalable Oversight via Partitioned Human Supervision
Ren Yin, Takashi Ishida, Masashi Sugiyama
https://arxiv.org/abs/2510.22500 https://mastoxiv.page/@arXiv_csLG_bot/115451787490434401
- ContextPilot: Fast Long-Context Inference via Context Reuse
Yinsicheng Jiang, Yeqi Huang, Liang Cheng, Cheng Deng, Xuan Sun, Luo Mai
https://arxiv.org/abs/2511.03475 https://mastoxiv.page/@arXiv_csLG_bot/115502245581974540
- Metabolomic Biomarker Discovery for ADHD Diagnosis Using Interpretable Machine Learning
Nabil Belacel, Mohamed Rachid Boulassel
https://arxiv.org/abs/2601.11283 https://mastoxiv.page/@arXiv_csLG_bot/115921183182326799
- PhysE-Inv: A Physics-Encoded Inverse Modeling approach for Arctic Snow Depth Prediction
Akila Sampath, Vandana Janeja, Jianwu Wang
https://arxiv.org/abs/2601.17074
- SAGE-5GC: Security-Aware Guidelines for Evaluating Anomaly Detection in the 5G Core Network
Cristian Manca, Christian Scano, Giorgio Piras, Fabio Brau, Maura Pintor, Battista Biggio
https://arxiv.org/abs/2602.03596
- LORE: Jointly Learning the Intrinsic Dimensionality and Relative Similarity Structure From Ordina...
Anand, Helbling, Davenport, Berman, Alagapan, Rozell
https://arxiv.org/abs/2602.04192
- Towards Robust Scaling Laws for Optimizers
Alexandra Volkova, Mher Safaryan, Christoph H. Lampert, Dan Alistarh
https://arxiv.org/abs/2602.07712 https://mastoxiv.page/@arXiv_csLG_bot/116046369672796465
- Do We Need Adam? Surprisingly Strong and Sparse Reinforcement Learning with SGD in LLMs
Sagnik Mukherjee, Lifan Yuan, Pavan Jayasinha, Dilek Hakkani-T\"ur, Hao Peng
https://arxiv.org/abs/2602.07729 https://mastoxiv.page/@arXiv_csLG_bot/116046377539155485
- AceGRPO: Adaptive Curriculum Enhanced Group Relative Policy Optimization for Autonomous Machine L...
Yuzhu Cai, Zexi Liu, Xinyu Zhu, Cheng Wang, Siheng Chen
https://arxiv.org/abs/2602.07906 https://mastoxiv.page/@arXiv_csLG_bot/116046423413650658
- VESPO: Variational Sequence-Level Soft Policy Optimization for Stable Off-Policy LLM Training
Guobin Shen, Chenxiao Zhao, Xiang Cheng, Lei Huang, Xing Yu
https://arxiv.org/abs/2602.10693 https://mastoxiv.page/@arXiv_csLG_bot/116057229834947730
- KBVQ-MoE: KLT-guided SVD with Bias-Corrected Vector Quantization for MoE Large Language Models
Zukang Xu, Zhixiong Zhao, Xing Hu, Zhixuan Chen, Dawei Yang
https://arxiv.org/abs/2602.11184 https://mastoxiv.page/@arXiv_csLG_bot/116062537528208461
- MUSE: Multi-Tenant Model Serving With Seamless Model Updates
Correia, Ferreira, Martins, Bento, Guerreiro, Pereira, Gomes, Bono, Ferreira, Bizarro
https://arxiv.org/abs/2602.11776 https://mastoxiv.page/@arXiv_csLG_bot/116062952355379801
- Pawsterior: Variational Flow Matching for Structured Simulation-Based Inference
Jorge Carrasco-Pollo, Floor Eijkelboom, Jan-Willem van de Meent
https://arxiv.org/abs/2602.13813 https://mastoxiv.page/@arXiv_csLG_bot/116085828112928218
- Silent Inconsistency in Data-Parallel Full Fine-Tuning: Diagnosing Worker-Level Optimization Misa...
Hong Li, Zhen Zhou, Honggang Zhang, Yuping Luo, Xinyue Wang, Han Gong, Zhiyuan Liu
https://arxiv.org/abs/2602.14462 https://mastoxiv.page/@arXiv_csLG_bot/116085997857526328
- Divine Benevolence is an $x^2$: GLUs scale asymptotically faster than MLPs
Alejandro Francisco Queiruga
https://arxiv.org/abs/2602.14495 https://mastoxiv.page/@arXiv_csLG_bot/116086011618741857
- \"UberWeb: Insights from Multilingual Curation for a 20-Trillion-Token Dataset
DatologyAI, et al.
https://arxiv.org/abs/2602.15210 https://mastoxiv.page/@arXiv_csLG_bot/116090912256712568
- GLM-5: from Vibe Coding to Agentic Engineering
GLM-5-Team, et al.
https://arxiv.org/abs/2602.15763 https://mastoxiv.page/@arXiv_csLG_bot/116091080686771018
- Anatomy of Capability Emergence: Scale-Invariant Representation Collapse and Top-Down Reorganizat...
Jayadev Billa
https://arxiv.org/abs/2602.15997 https://mastoxiv.page/@arXiv_csLG_bot/116096541546306333
- AI-CARE: Carbon-Aware Reporting Evaluation Metric for AI Models
KC Santosh, Srikanth Baride, Rodrigue Rizk
https://arxiv.org/abs/2602.16042 https://mastoxiv.page/@arXiv_csLG_bot/116096581524696028
- Beyond Message Passing: A Symbolic Alternative for Expressive and Interpretable Graph Learning
Chuqin Geng, Li Zhang, Haolin Ye, Ziyu Zhao, Yuhe Jiang, Tara Saba, Xinyu Wang, Xujie Si
https://arxiv.org/abs/2602.16947 https://mastoxiv.page/@arXiv_csLG_bot/116102426238903124
toXiv_bot_toot
 @tomkalei@machteburch.social
@tomkalei@machteburch.socialChuck Norris kann das richtige Fenster im MacOS Finder finden.
Chuck Norris hat sich mit vibe-coding dazu eine App geschrieben. Finder-Finder: Die findet Finder Fenster.
(Für diesen toot bitte "Finder" auf Deutsch aussprechen, also mit i nicht "Feinder")
@frankstohl@mastodon.socialVibe Coding und das Copyright
https://stohl.de/wordpress/?p=192969
 @tinoeberl@mastodon.online
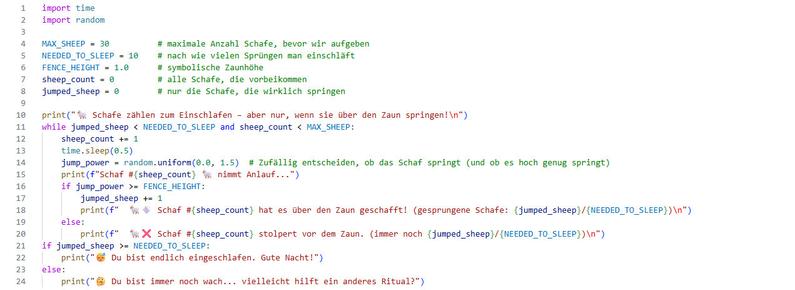
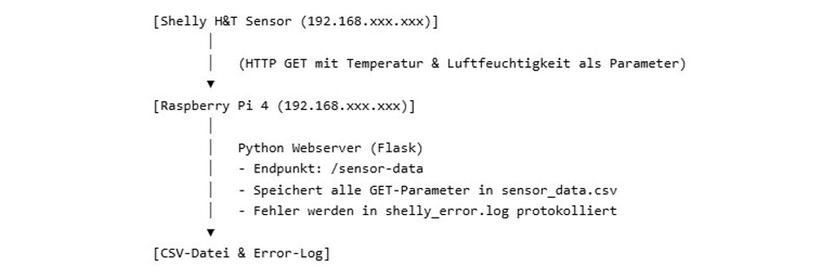
@tinoeberl@mastodon.online#Steady #Klimacrew
Wie lassen sich #Shelly-Sensordaten ohne Cloud lokal speichern?
Ich wollte die Daten für
@Techmeme@techhub.socialReplit launches Mobile Apps on Replit, which enables vibe-coding of iOS apps with integrated Stripe monetization (CNBC)
https://www.cnbc.com/2026/01/15/ai-startup-replit-launches-feature-to-vibe-code-mobile-apps.html
@Techmeme@techhub.socialWiz says Moltbook had a major flaw that exposed private messages, emails, and credentials; Wiz co-founder Ami Luttwak called the flaw a byproduct of vibe coding (Raphael Satter/Reuters)
https://www.reuters.com/legal/litigation/m
@tinoeberl@mastodon.online#Steady #Klimacrew
#BahnMonitor-Projekt: 1. Wie kommt man an Live-Daten der Deutschen Bahn?
Im November konnte ich per Zufall mit einem
@Techmeme@techhub.socialEmergent, which offers an AI-powered software development service, says it is generating annual run-rate revenue of $100M , just eight months after launch (TechCrunch)
https://techcrunch.com/2026/02/17/emergent-hits-100m-arr-eight-mont…
@tinoeberl@mastodon.online @Techmeme@techhub.socialWorkday CEO Aneel Bhusri says Anthropic, Google, and OpenAI use Workday tools and "no amount of vibe coding" could replace it; WDAY is down ~40% so far in 2026 (Brody Ford/Bloomberg)
https://www.bloomberg.com/news/articles/20
@tinoeberl@mastodon.online#Steady #Klimacrew
#BahnMonitor-Projekt: 7. Zufall ist nicht gleich Zufall. 🤭
Nach der Verspätungsmeldung kommt ein Wissenshäppchen. Der
@Techmeme@techhub.socialLarge US corporations are not ditching core business software for AI yet, instead seeking better vendor deals and "vibe-coding" smaller apps and customizations (Belle Lin/Wall Street Journal)
https://www.
@tinoeberl@mastodon.online#Steady-#Klimacrew
Wie genau entwickelt sich der Ausbau von #Batteriespeichern in Deutschland – und was verraten die Rohdaten der
@Techmeme@techhub.socialEuropean VC firm Hummingbird raised $800M to find "misfit" founders, taking its total assets to ~$2B, after backing Kraken and AI vibe coding startup Lovable (Financial Times)
https://www.ft.com/content/4d29c556-bbd9-490e-a3c8-90f5b894af9e
@tinoeberl@mastodon.online#Steady #Klimacrew
#BahnMonitor-Projekt: 5. Automatisierte Skripte brauchen Kontrolle – besonders bei API-Aufrufen.
Jetzt bekommt das
@Techmeme@techhub.socialAI tools like Claude Code have transformed coders' lives, and AI labs are now eyeing a bigger goal: automating everyone's lives and winning the non-coder market (Kate Clark/Wall Street Journal)
https://www.wsj.com/tech/ai/claude-code-cu
@tinoeberl@mastodon.online#Steady #Klimacrew
#BahnMonitor-Projekt: 3. Klappt der erste Zugriff auf die Bahn-API?
Im nächsten Schritt wurde die API-Abfrage getestet udn geprüft, ob die zurückgelieferten Datenstru…
@tinoeberl@mastodon.online#Steady #Klimacrew
#BahnMonitor-Projekt: 2. Welche Architektur sollte der Bot haben?
Bevor es ans Coden geht, ist etwas Grübeln über eine sinnvolle Gliederung der Module ratsam. Wie sie…
@tinoeberl@mastodon.online#Steady #Klimacrew
#VibeCoding mit KI-Programmierhilfen in Visual Studio Code ausprobiert.
Ich habe zwei KI-Assistenzen für die direkte Integration in VSCode getestet, ob sie meine Erwar…
@tomkalei@machteburch.socialThe project had been abandoned for quite a while but it was running for me on github for years.
OK, let's get to the second reason you might want to unfollow me at that point. Vibe coding. I've recently gotten into claude code (for lean proving actually, but why not use it for python too?)
Of course claude can just modernize this very easily. So I've sat down in a few short sessions and modernized the code base and added some features and doc.
@tinoeberl@mastodon.online @tinoeberl@mastodon.online @tinoeberl@mastodon.online @tinoeberl@mastodon.online @tinoeberl@mastodon.online#Steady-#Klimacrew
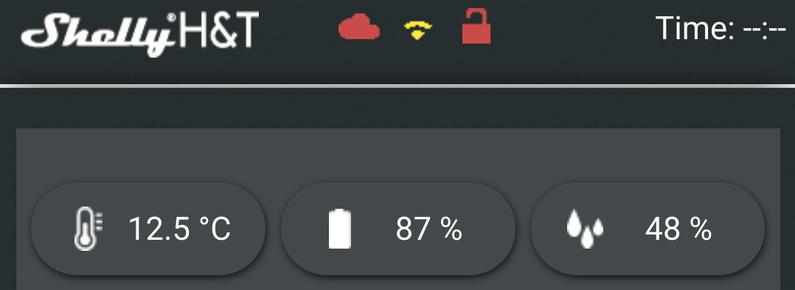
Wie bringt man Temperatur- und #Luftfeuchtigkeitsmessung in den #Balkongarten, ganz ohne Cloud und Bastelchaos?
Für Leute mit
@tinoeberl@mastodon.online#Steady-#Klimacrew
#Datenanalyse von #Stromspeichern: Falsche Diagrammwerte können auf Dubletten in den
@tinoeberl@mastodon.online#Steady-#Klimacrew
#Datenanalyse von #Stromspeichern: Wie lassen sich extreme Werteunterschiede grafisch sinnvoll darstellen? Was macht man, wenn eine lineare Skala ungeeignet erscheint…
@tinoeberl@mastodon.online#Steady-#Klimacrew
#Datenanalyse von #Stromspeichern: Warum weist das #Marktstammdatenregister
@tinoeberl@mastodon.online#Steady #Klimacrew
#BahnMonitor-Projekt: 6. Nachdem das Skript läuft, kommt nun der Tröt auf #Mastodon
@tinoeberl@mastodon.online @tinoeberl@mastodon.online#Steady #Klimacrew
#BahnMonitor-Projekt: 4. Welche #ICE-Daten braucht man und welche können weg?
@tinoeberl@mastodon.online