@qbi@freie-re.de
@qbi@freie-re.de2026-05-13 14:27:01
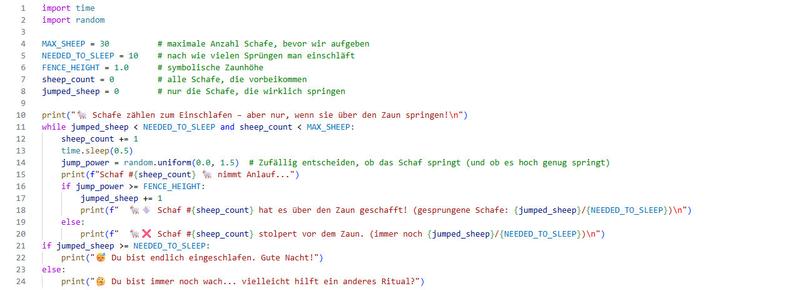
Klingt nice. Aber fast die Hälfte der Commits stammt von #Claude.
#vibecoding
https://bsd.network/@lcheylus/11656610
@qbi@freie-re.deKlingt nice. Aber fast die Hälfte der Commits stammt von #Claude.
#vibecoding
https://bsd.network/@lcheylus/11656610
 @tinoeberl@mastodon.online
@tinoeberl@mastodon.online#Steady #Klimacrew
#VibeCoding mit KI-Programmierhilfen in Visual Studio Code ausprobiert.
Ich habe zwei KI-Assistenten für die direkte Integration in VSCode getestet, ob sie meine Erwar…
 @sakhavi@aoir.social
@sakhavi@aoir.socialI've seen a bunch of commentary that #vibecoding thwarts / neglects the truth of programming-as-theory-building (Naur 1985), and I believe that's true.
One thing I haven't seen stated as explicitly is that if you don't have a theory of how your program works, you can't have any understanding of how it works *ethically*.
It's hard enough to bring technologists&…
 @ellie@ellieayla.net
@ellie@ellieayla.netDid "vibe coding" used to mean something else, before the prevalence of stochastic bullshit machine emitting code-shaped text vomit? I have a vague memory of it involving /fun/ before 2024.
#fuckai #vibecoding #askfedi
 @digitalnaiv@mastodon.social
@digitalnaiv@mastodon.socialIch bin kein Programmierer — und habe trotzdem in 24 Stunden eine eigene Weinkeller-App gebaut. Mit Claude Code, natürlicher Sprache und null Zeilen selbst geschriebenem Code. Was dabei entstand und was das bedeutet — neuer Beitrag auf stefanpfeiffer.blog. #ClaudeCode #VibeCoding
 @phpmacher@sueden.social
@phpmacher@sueden.socialDas Tolle an #vibeCoding ist doch, dass keine Konzepte veralten
 @kubikpixel@chaos.social
@kubikpixel@chaos.social«Mehrdeutigkeit als Risiko—Vibe Coding ist keine gute Idee bei Java:
#VibeCoding versprach die #Demokratie'sierung der #Software-Entwicklung. Für
 @jhelberg@mastodon.social
@jhelberg@mastodon.socialReviewed some vibe coded UI today, because things were a bit off. Well, the things that were not off were 50% of the time off and the other half looked ok by accident. Hell yeah, this vibe codes stuff is utter nonsensical and a lot of work to fix. Why is this popular? How do I tell my colleague? #vibecoding
 @peter_mcmahan@mas.to
@peter_mcmahan@mas.toIt's hard to overstate just how much my confidence in a piece of software drops when I see this. (Especially for this project which was very vocal about its shift to genai-first)
#vibecoding #genai

 @crell@phpc.social
@crell@phpc.social @Treppenwitz@sfba.social
@Treppenwitz@sfba.socialI know #Replit bills itself as a #vibecoding platform these days, but I opened it for a quick Python REPL and couldn't figure out for the life of me how to bypass the #AI prompt.