 @der_raddler@dresden.network
@der_raddler@dresden.network2026-06-02 06:04:36
Vielleicht hat der Kollege in Chemnitz mehr Glück, als wir in Dresden.
Ich drück die Daumen!
https://www.tag24.de/chemnitz/lokales/fahrrad-demo-will-autobahn-in-sachsen-lahmlegen-3503279

 @Techmeme@techhub.social
@Techmeme@techhub.social2026-06-01 09:40:52
Coinbase launches direct Indian rupee deposit and withdrawal rails via the Immediate Payment Service, aiming to remove its reliance on P2P and intermediaries (Omkar Godbole/CoinDesk)
https://www.coindesk.com/markets/2026/05/3…

 @Mediagazer@mstdn.social
@Mediagazer@mstdn.social2026-07-01 15:07:45
Canada will join the Eurovision song contest in 2027, becoming the first new participant since Australia in 2015; the contest will be held in Bulgaria (The Guardian)
https://www.theguardian.com/tv-and-radio/2026/jul/01/canada-joins-eurovision-song-co…

 @frankel@mastodon.top
@frankel@mastodon.top2026-05-02 09:22:30
 @einzigartiger@chaos.social
@einzigartiger@chaos.social2026-06-01 13:37:16
In #Chemnitz ist am Samstag #Fahrraddemo über die Autobahn A72
https://chemnitz.adfc.de/neuigkeit/fah

 @usul@piaille.fr
@usul@piaille.fr2026-06-02 03:53:01
Seul(e) dans Pékin : comment les dissidents chinois contestent le régime
https://www.lemonde.fr/international/article/2026/06/01/seul-e-dans-pekin-comment-les-dissidents-chinois-contestent-le-regim…

 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2026-05-02 04:00:05
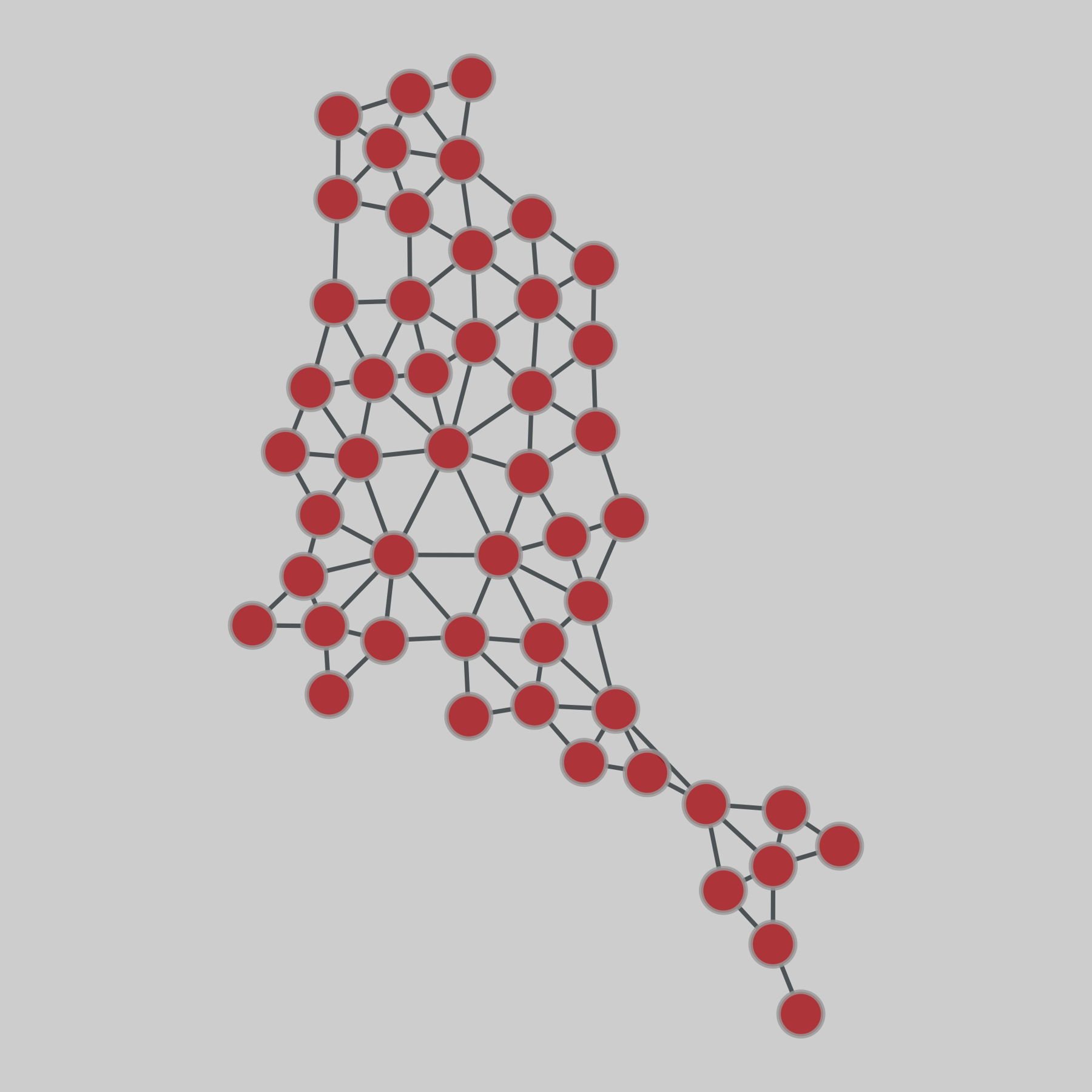
contiguous_usa: Contiguous states (USA)
A network of contiguous states in the USA, in which each state is a node and two nodes are connected if they share a land-based geographic border. The dataset includes the lower 48 states, and the District of Columbia.
This network has 49 nodes and 107 edges.
Tags: Transportation, Roads, Unweighted
 @Techmeme@techhub.social
@Techmeme@techhub.social2026-08-01 19:01:26
Bitcoin hardware wallet Coldcard shipped a faulty firmware build, and hackers are now draining wallets; Galaxy Research estimates ~$70M stolen (Shaurya Malwa/CoinDesk)
https://www.coindesk.com/tech/2026/08/01/ho…
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2026-07-01 13:00:04
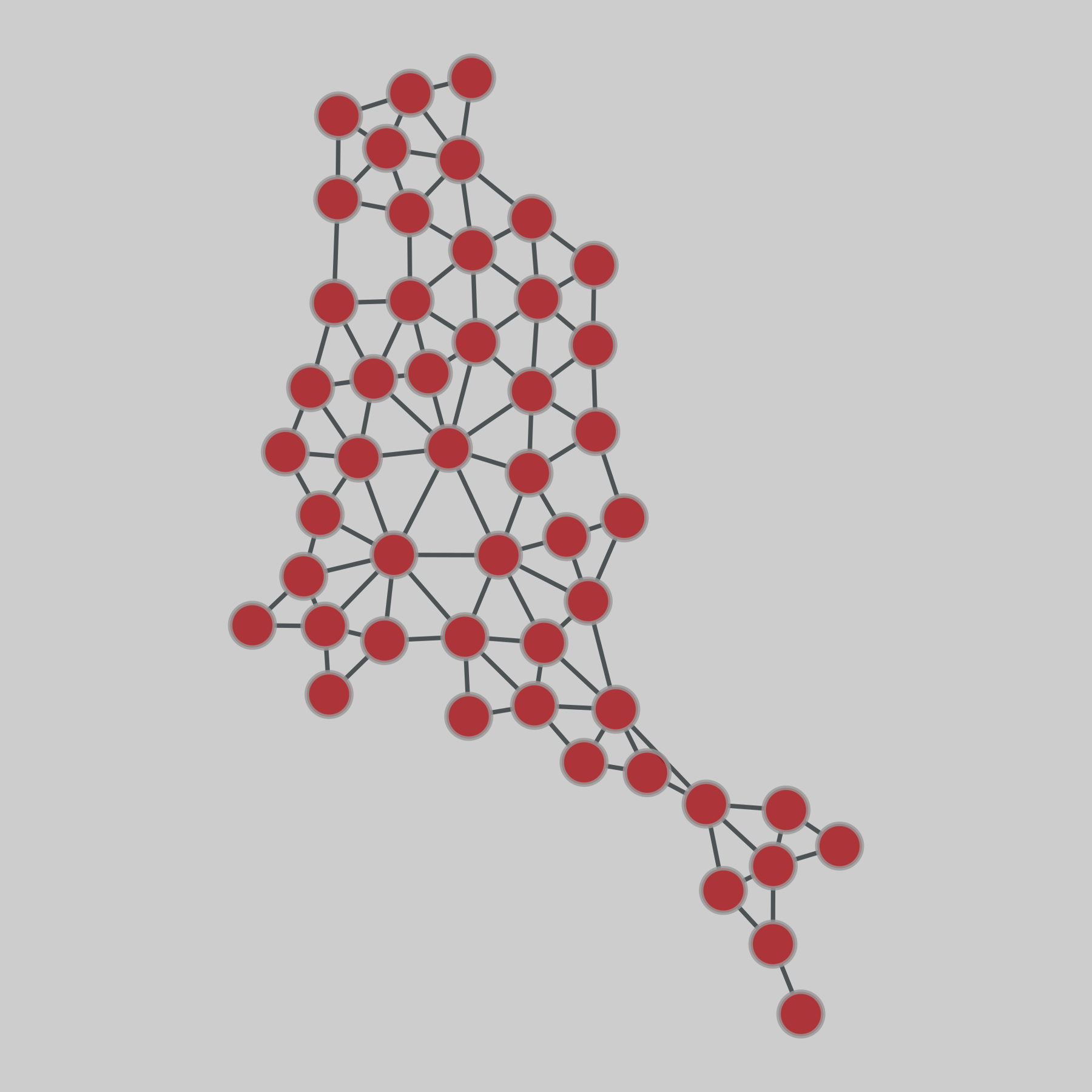
contiguous_usa: Contiguous states (USA)
A network of contiguous states in the USA, in which each state is a node and two nodes are connected if they share a land-based geographic border. The dataset includes the lower 48 states, and the District of Columbia.
This network has 49 nodes and 107 edges.
Tags: Transportation, Roads, Unweighted
 @Techmeme@techhub.social
@Techmeme@techhub.social2026-06-01 12:15:45
SEC filing: Strategy sold 32 bitcoin between May 26 and May 31 for ~$2.5M at an average net price of $77,135 per coin, its first disclosed bitcoin disposal (Shaurya Malwa/CoinDesk)
https://www.coindesk.com/markets/2026/06/01/strate…
