 @cowboys@darktundra.xyz
@cowboys@darktundra.xyz2026-01-10 11:32:46
Cowboys eye major defensive reinforcements in early 2026 NFL Draft projections https://www.si.com/nfl/cowboys/onsi/draft/dallas-cowboys-eye-major-defensive-reinforcements-early-2026-nfl-mock-draft
 @cdarwin@c.im
@cdarwin@c.im2026-01-06 15:14:44
Donald Trump has suggested US taxpayers could reimburse energy companies for repairing Venezuelan infrastructure for extracting and shipping oil.
Trump acknowledged that
“a lot of money” would need to be spent to increase oil production in Venezuela after US forces ousted its leader, Nicolšs Maduro,
but suggested his government could pay oil companies to do the work.
“A tremendous amount of money will have to be spent and the oil companies will spend it,
and the…
 @jonippolito@digipres.club
@jonippolito@digipres.club2025-12-06 14:55:30
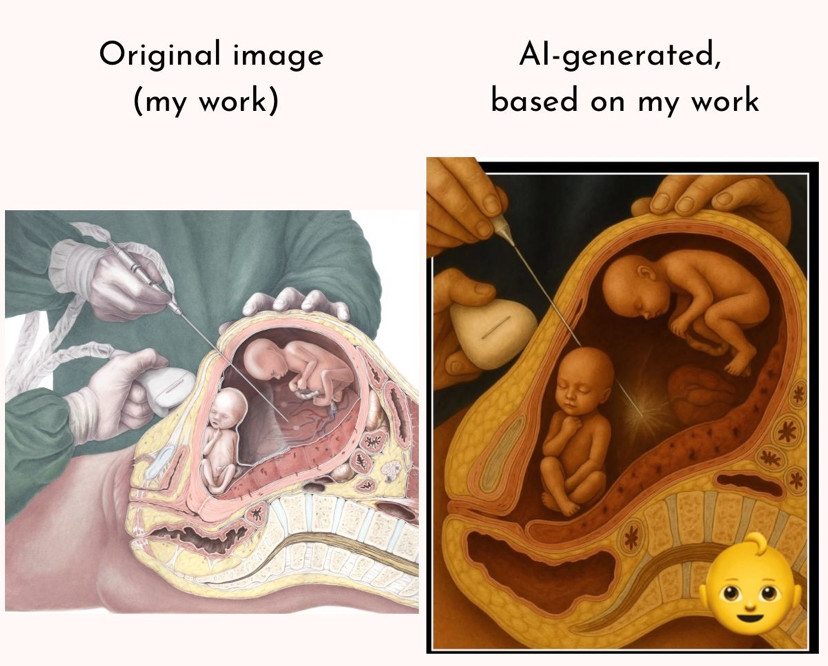
Growing up, I considered becoming a medical illustrator due to its combination of scientific and artistic rigor. Neither is on display in this derivative AI image shared by a surgeon too lazy to find the real thing.
https://www.
 @hex@kolektiva.social
@hex@kolektiva.social2025-11-17 08:52:05
The implications are interesting enough when we apply this to systems like capitalism or national governments, but there are other very interesting implications when applied to systems like race or gender.
Like, as a cis man the only way I can be free to express and explore my own masculinity is if the masculinity I participate in is one which allows anyone the freedom to leave. Then I have an obligation to recognize the validity of nom-masculine trans identity as a necessary component of my own. If I fail to do this, then I trap myself in masculinity and allow the system to control me rather than me to be a free participant in the system.
But if it's OK to escape but not enter, that's it's own restriction that constrains the freedom to leave. It creates a barrier that keeps people in by the fear that they cannot return. So in order for me to be free in my cis masculine identity, I must accept non-masculine trans identities as they are and accept detransitioning as also valid.
But I also need to accept trans-masc identities because restricting entry to my masculinity means non-consensually constraining other identities. If every group imposes an exclusion against others coming in, that, by default, makes it impossible to leave every other group. This is just a description of how national borders work to trap people within systems, even if a nation itself allows people to "freely" leave.
So then, a free masculinity is one which recognizes all configurations of trans identities as valid and welcomes, if not celebrates, people who transition as affirmations of the freedom of their own identity (even for those who never feel a reason to exercise that same freedom).
The most irritating type of white person may look at this and say, "oh, so then why can't I be <not white>?" Except that the critique of transratial identities has never been "that's not allowed" and has always been "this person didn't do the work." If that person did the work, they would understand that the question doesn't make sense based on how race is constructed. That person might understand that race, especially whiteness, is more fluid than they at first understood. They might realize that whiteness is often chosen at the exclusion of other racialized identities. They would, perhaps, realize that to actually align with any racialized identity, they would first have to understand the boot of whiteness on their neck, have to recognize the need to destroy this oppressive identity for their own future liberation. The best, perhaps only, way to do this would be to use the privilege afforded by that identity to destroy it, and in doing so would either destroy their own privilege or destroy the system of privilege. The must either become themselves completely ratialized or destroy the system of race itself such being "transracial" wouldn't really make sense anymore.
But that most annoying of white person would, of course, not do any such work. Nevertheless, one hopes that they may recognize the paradox that they are trapped by their white identity, forced forever by it to do the work of maintaining it. And such is true for all privileged identities, where privilege is only maintained through restrictions where these restrictions ultimately become walls that imprison both the privileged and the marginalized in a mutually reinforcing hell that can only be escaped by destroying the system of privilege itself.
@cdarwin@c.im2025-11-22 20:07:02
After years of struggling to find enough workers for some of the nation’s toughest lockups,
the Federal Bureau of Prisons is facing a new challenge:
Corrections officers are jumping ship for more lucrative jobs at Immigration and Customs Enforcement.
This is one of the unintended consequences of the Trump administration’s focus on mass deportations.
For months, ICE has been on a recruiting blitz,
offering $50,000 starting bonuses and tuition reimbursement
