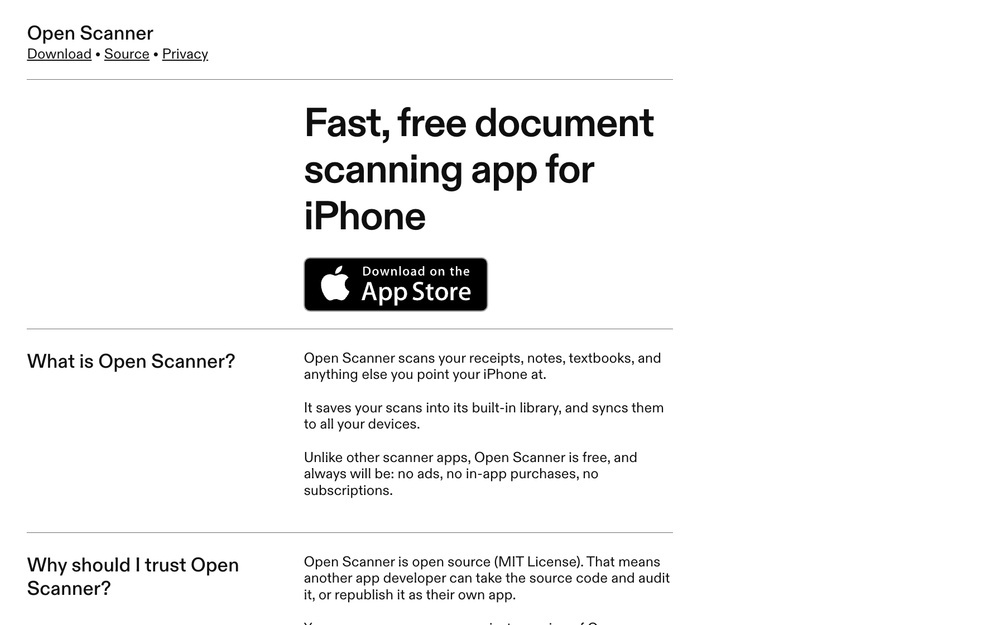
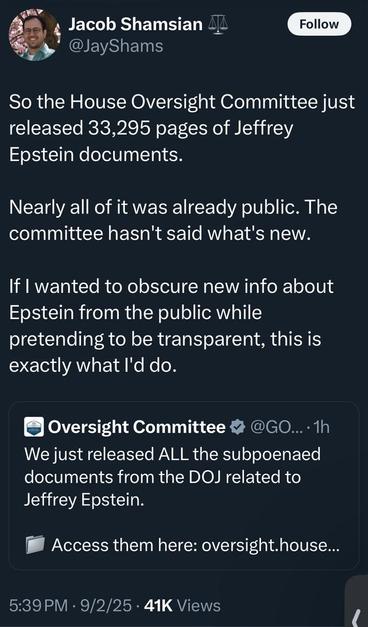
@axbom@axbom.me
@axbom@axbom.me2025-10-29 12:27:59
@… Ja det där underlättar en del. Fick mig att minnas “kreditkortet” med genomskinliga rutor för att lättare avskilja delar av OCR-numret när man skrev av det. Och så hittade jag den här manicken! 😄
https://www.smartasaker.se/sv/ocr-lasare
https://www.smartasaker.se/sv/ocr-lasare