 @memeorandum@universeodon.com
@memeorandum@universeodon.com2026-05-23 19:30:49
Trump Administration Chips Away at Last Traces of Broad Inquiry Into Jan. 6 (Alan Feuer/New York Times)
https://www.nytimes.com/2026/05/23/us/politics/trump-prosecutors-jan-6.html?unlocked_article_code=1.klA.slPN.ZrKd_ImvyhDg&smid=url-share
http://www.memeorandum.com/260523/p19#a260523p19
 @Techmeme@techhub.social
@Techmeme@techhub.social2026-05-23 20:10:58
How Anthropic's ongoing discussions with the Vatican about ethics and AI led to Christopher Olah being invited to Pope Leo's unveiling of an encyclical on AI (Jack Jenkins/RNS)
https://religionnews.com/2026/05/22/why-anthropic-is-he…

 @cdarwin@c.im
@cdarwin@c.im2026-06-14 18:10:11
Birthday greetings for President Trump as he turns 80
– from Greta Thunberg, Piers Morgan and more
Let him eat cake!
https://www.theguardian.com/us-news/ng-interactive/2026/ju…
 @ErikJonker@mastodon.social
@ErikJonker@mastodon.social2026-06-05 11:21:21
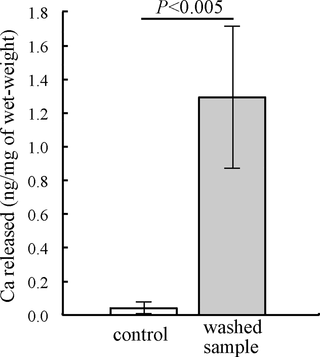
These kind of interesting stories make browsing the internet worthwhile for me, aluminum amphipods in the deepsea 😀
"An aluminum shield enables the amphipod Hirondellea gigas to inhabit deep-sea environments"
https://journals.plos.org/plosone/article?i…
 @burger_jaap@mastodon.social
@burger_jaap@mastodon.social2026-05-06 09:25:13
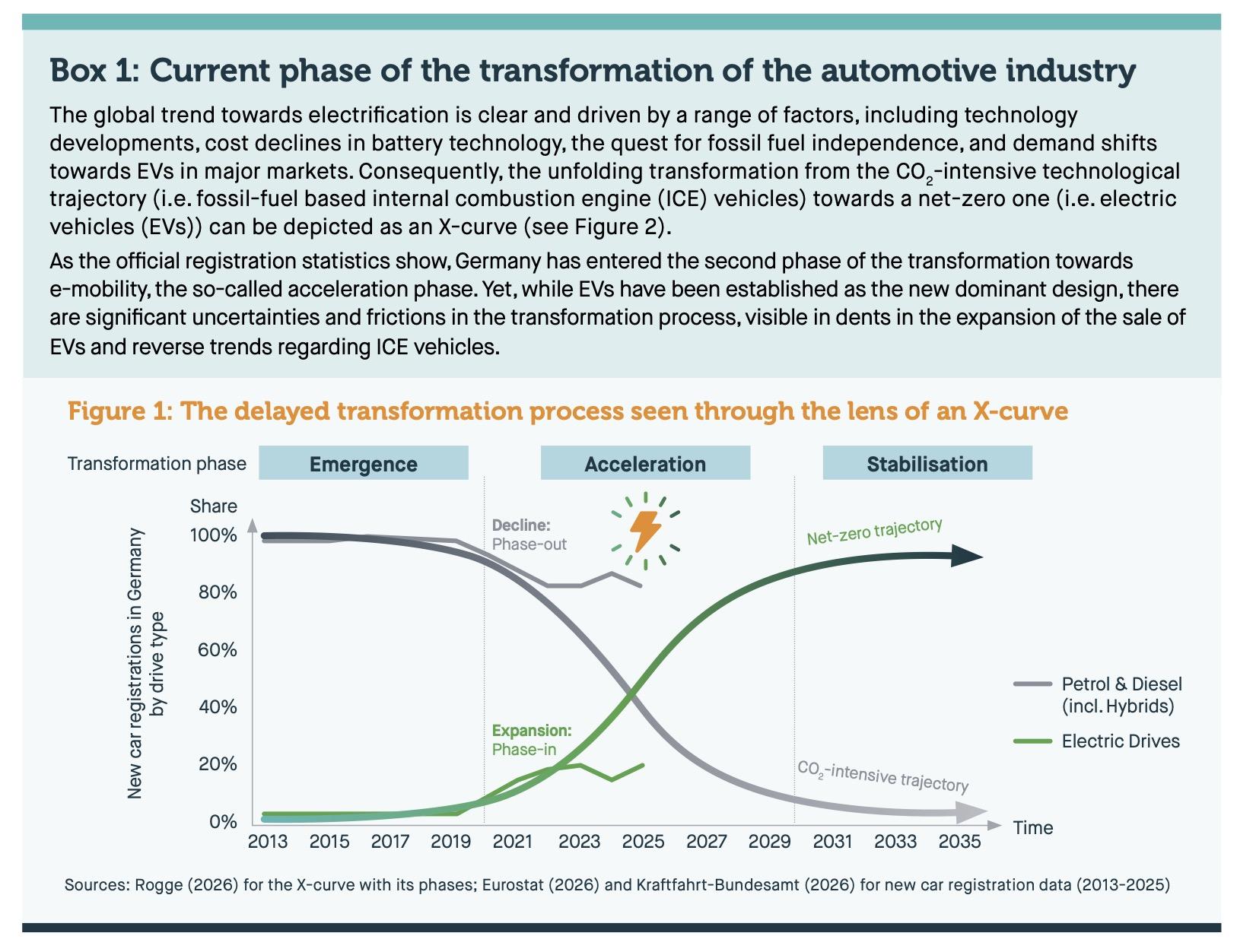
"Don't punish the pioneers"
The slow transition from combustion engines to EVs is putting pressure on the German car industry. However, unlike the German government, innovators in the sector wish to stick to the European CO2 targets (for 2035 and the path towards them).
https://zenodo.org/records/20030452
 @Techmeme@techhub.social
@Techmeme@techhub.social2026-05-07 03:51:10
Bristol Myers Squibb's Massachusetts facility boosted drug production volume for clinical and commercial use by ~40% with AI, a bright spot in US manufacturing (Farah Stockman/New York Times)
https://www.nytimes.com/2026/05…

 @arXiv_csIT_bot@mastoxiv.page
@arXiv_csIT_bot@mastoxiv.page2026-06-11 08:07:41
Reconfigurable Antennas for Next-generation Mobile Communication Networks: A Comprehensive Survey and Tutorial
Yizhe Zhao, Long Zhang, Halvin Yang, Kun Yang, Rui Zhang, Lingyang Song, Yuanwei Liu
https://arxiv.org/abs/2606.12139 https://arxiv.org/pdf/2606.12139 https://arxiv.org/html/2606.12139
arXiv:2606.12139v1 Announce Type: new
Abstract: The transition to next-generation mobile communication networks, particularly 6G, demands advanced technologies to meet the requirements for ultra-reliable, low-latency communication, massive connectivity, and intelligent applications. Reconfigurable antennas (RAs) play a crucial role in achieving these objectives by enabling dynamic adjustments to the radio frequency (RF) characteristics of antennas, such as gain, radiation pattern, impedance, and polarization. Unlike traditional fixed-position antennas, RAs can alter both their radiation patterns and positions, offering flexibility in response to varying communication environments. This paper presents a comprehensive survey and tutorial on RAs, with a focus on fluid antennas (FAs), movable antennas (MAs), pinching antennas (PAs), and reconfigurable holographic antennas (RHAs), examining their potential in next-generation mobile networks. We explore the channel modelling and estimation, performance analysis, resource allocation strategies, and their synergy with other emerging wireless technologies for each type of RA. Finally, we provide a comparative analysis of different RAs and discuss the open challenges and future research directions, offering insights and guidance for future investigations in the exciting research area.
toXiv_bot_toot
 @bibbleco@infosec.exchange
@bibbleco@infosec.exchange2026-06-11 11:55:57
The AI backlash gathers pace! \o/
https://www.theguardian.com/technology/2026/jun/11/ai-absolutism-apocalyptic-future
This is a neat restatement of my general prejudice and angle on the whole thing. It's not a miracle that will make th…

 @CubitOom@social.linux.pizza
@CubitOom@social.linux.pizza2026-07-04 14:55:04
Fascists paramilitary invaders abduct mother holding U.S. citizen daughter, don't allow her to call the father to come get the child, and force a decision (Houston, TX • 07/02/2026)
Video Source:
https://reddit.com/comments/1umlgvm
 @ErikJonker@mastodon.social
@ErikJonker@mastodon.social2026-06-06 07:29:30
