 @usul@piaille.fr
@usul@piaille.fr2026-02-26 05:45:10
« Tu restes un Arabe doublé d’une pédale », le parquet de Perpignan ouvre une enquête pour menaces contre un militant LFI - Le Parisien
https://www.leparisien.fr/politique/tu-res…

 @mxp@mastodon.acm.org
@mxp@mastodon.acm.org2026-03-23 16:47:43
«‹Le véhicule n'était pas un camion frigorifique, ce qui constitue une violation des prescriptions en matière de sécurité alimentaire›, note l'OFDF dans un communiqué. Les droits de douane n'avaient pas été payés et le poids maximal autorisé était dépassé.»
http…
 @fractaleblog@masto.comversive.com
@fractaleblog@masto.comversive.com2026-02-24 20:24:47

 @_tillwe_@mastodon.social
@_tillwe_@mastodon.social2026-02-25 09:36:09
Die letzte reguläre Sitzung des Landtags ist schon eine Weile her ... dennoch gibt es heute um 11 Uhr nochmals eine Plenarsitzung im Landtag BW. Dabei geht es um den Beschluss eines "Gesetzes über einen Ausgleich im Zusammenhang mit Coronasoforthilfen [...]" - sprich: die Rückzahlung unrechtmäßig zurückgeforderter Hilfszahlungen. Klingt kompliziert, dürfte aber gerade für Handwerk und kleine Unternehmen wichtig sein.
 @jdrm@social.linux.pizza
@jdrm@social.linux.pizza2025-12-26 08:21:13
#footPathfriday
Ayer en el puerto de Navacerrada, el camino de subida al alto de Guarramillas

 @jerome@jasette.facil.services
@jerome@jasette.facil.services2026-03-23 12:50:45
Accident mortel d’un avion d’Air Canada Š New York
Les deux pilotes de ce vol d'Air Canada Express ont perdu la vie.
L’avion venait de #Montreal
https://ici.radio-…
 @metacurity@infosec.exchange
@metacurity@infosec.exchange2026-03-24 11:59:17
Hack discovered at Dutch Ministry of Finance; Unclear if data was accessed
https://nltimes.nl/2026/03/24/hack-discovered-ministry-finance-unclear-data-accessed
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.page2026-02-25 10:37:21
Probing Dec-POMDP Reasoning in Cooperative MARL
Kale-ab Tessera, Leonard Hinckeldey, Riccardo Zamboni, David Abel, Amos Storkey
https://arxiv.org/abs/2602.20804 https://arxiv.org/pdf/2602.20804 https://arxiv.org/html/2602.20804
arXiv:2602.20804v1 Announce Type: new
Abstract: Cooperative multi-agent reinforcement learning (MARL) is typically framed as a decentralised partially observable Markov decision process (Dec-POMDP), a setting whose hardness stems from two key challenges: partial observability and decentralised coordination. Genuinely solving such tasks requires Dec-POMDP reasoning, where agents use history to infer hidden states and coordinate based on local information. Yet it remains unclear whether popular benchmarks actually demand this reasoning or permit success via simpler strategies. We introduce a diagnostic suite combining statistically grounded performance comparisons and information-theoretic probes to audit the behavioural complexity of baseline policies (IPPO and MAPPO) across 37 scenarios spanning MPE, SMAX, Overcooked, Hanabi, and MaBrax. Our diagnostics reveal that success on these benchmarks rarely requires genuine Dec-POMDP reasoning. Reactive policies match the performance of memory-based agents in over half the scenarios, and emergent coordination frequently relies on brittle, synchronous action coupling rather than robust temporal influence. These findings suggest that some widely used benchmarks may not adequately test core Dec-POMDP assumptions under current training paradigms, potentially leading to over-optimistic assessments of progress. We release our diagnostic tooling to support more rigorous environment design and evaluation in cooperative MARL.
toXiv_bot_toot
@metacurity@infosec.exchange2026-02-23 14:33:46
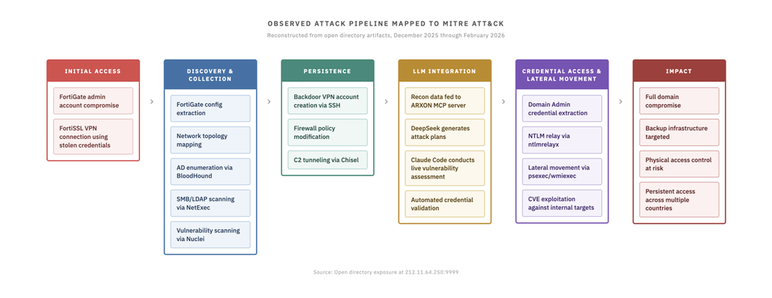
A lot has happened in the infosec world since Friday morning, so don't miss today's Metacurity for the most critical developments you should know, including
--Russian-speaking hacker used multiple genAI services to breach 600 FortiGate firewalls,
--Spanish cops bust four Anonymous members for 2025 DDoS attacks,
--Wynn Resorts is the latest casino victim of ShinyHunters,
--PayPal business loan app was breached,
--The UAE claims it thwarted multiple cybera…
 @metacurity@infosec.exchange
@metacurity@infosec.exchange2026-01-21 14:55:21
Don't miss today's packed Metacurity for the most critical infosec developments you need to know, including
--DOGE workers shared SSN data with outsiders, derailed DISA operations,
--UK launches national fraud reporting service,
--China blames Taiwan for cyberattacks,
--EU proposes freezing out Chinese tech suppliers,
--New Zealand launches Manage My Health breach probe,
--Curl ends its bug bounty program due to AI flood,
--Cloudflare fixes WAF…
