 @arXiv_csIR_bot@mastoxiv.page
@arXiv_csIR_bot@mastoxiv.page2025-10-15 08:48:12
Reinforced Preference Optimization for Recommendation
Junfei Tan, Yuxin Chen, An Zhang, Junguang Jiang, Bin Liu, Ziru Xu, Han Zhu, Jian Xu, Bo Zheng, Xiang Wang
https://arxiv.org/abs/2510.12211

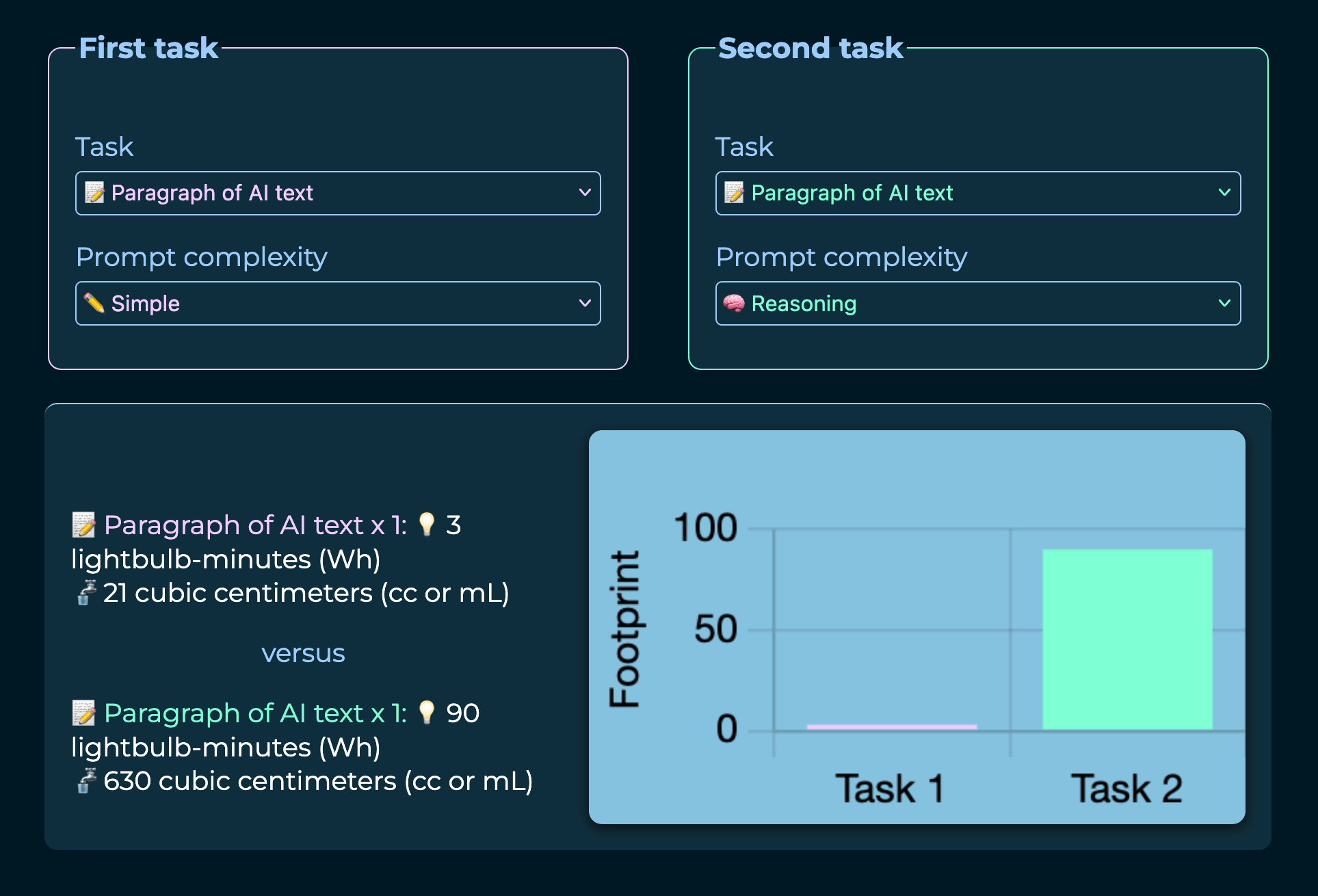
 @jonippolito@digipres.club
@jonippolito@digipres.club2025-12-09 14:11:46
We've updated the What Uses More app to reflect last week's finding by Luccioni and Gamazaychikov that "reasoning" mode increases energy and water usage by 30x. The study casts doubt on the improved efficiency AI companies are claiming for newer models
https://www.
 @@arXiv_physicsatomph_bot@mastoxiv.page@mastoxiv.page
@@arXiv_physicsatomph_bot@mastoxiv.page@mastoxiv.page2025-11-12 08:22:39
Cold-atom fountain for atom-surface interaction measurements mediated by a near-resonant evanescent light field
Taro Mashimo, Masashi Abe, Athanasios Laliotis, Satoshi Tojo
https://arxiv.org/abs/2511.08115
 @StephenRees@mas.to
@StephenRees@mas.to2025-12-07 01:25:33
Much of what I post on here is about Vancouver transit. But today I got to read about (some of) the history of Seattle. I recommend it. And venture to suggest that you might find Transit Sleuth's upcoming material worthy of your attention too.
https://transitsleuth.com/2025/12/06/s

 @cosmos4u@scicomm.xyz
@cosmos4u@scicomm.xyz2025-11-17 07:46:18
Is #AI really just dumb statistics? "Olympiad-level physics problem-solving presents a significant challenge for both humans and artificial intelligence (AI), as it requires a sophisticated integration of precise calculation, abstract reasoning, and a fundamental grasp of physical principles," says the (abstract of the) paper https://arxiv.org/abs/2511.10515: "The Chinese Physics Olympiad (CPhO), renowned for its complexity and depth, serves as an ideal and rigorous testbed for these advanced capabilities. In this paper, we introduce LOCA-R (LOgical Chain Augmentation for Reasoning), an improved version of the LOCA framework adapted for complex reasoning, and apply it to the CPhO 2025 theory examination. LOCA-R achieves a near-perfect score of 313 out of 320 points, solidly surpassing the highest-scoring human competitor and significantly outperforming all baseline methods." Oops ...?