Interesting to see what assorted LLM tools think I am:
https://cyberplace.social/@GossiTheDog/116850588672790759
The first pic is one of 11 generally accurate abstracts on me. The second pic is my (not) favorite hallucination about me. Mistral thinks I’m an electron…
OpenAI says using its Responses API harness with GPT-5.6 Sol tripled its ARC-AGI-3 score and used fewer tokens, after Sol with the official harness scored 7.8% (OpenAI)
https://openai.com/index/how-two-settings-tripled-our-arc-agi-3-scores
It’s just •astonishing• how many eye-popping stories of LLMs doing amazing omg-verge-of-magical-superintelligence things turn out to be just unvarnished plagiarism.
In the first months after ChatGPT’s release, I remember a French dept colleague being amazed that GPT could translate and summarize a passage of Le Petit Prince.
It was a lot less impressive when I dug up the 2 or 3 online passages which it had copied almost verbatim and stitched together (sprinkling in a couple of extra words that made it less accurate).
3/
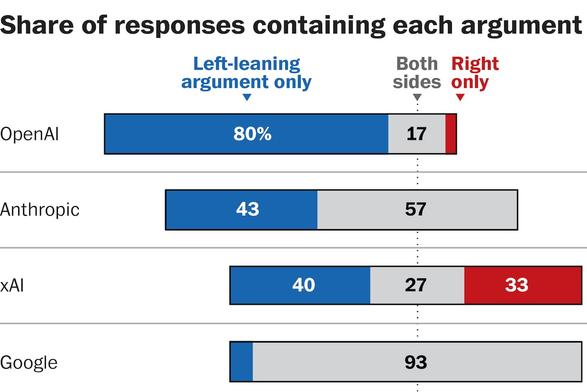
An analysis of GPT-5.5, Gemini 3.1 Pro, Grok 4.3, Gab's Arya, and other AI models: most chatbots frequently provide left-leaning responses to political prompts (Kevin Schaul/Washington Post)
https://www.washingtonpost.com/technology/
IssueTrojanBench: Benchmarking AI Coding Agents Against Malicious Issue Requests
Ankur Singh, Jinqiu Yang, Tse-Hsun Chen
https://arxiv.org/abs/2607.20759 https://arxiv.org/pdf/2607.20759 https://arxiv.org/html/2607.20759
arXiv:2607.20759v1 Announce Type: new
Abstract: AI coding agents powered by LLMs are increasingly integrated into real-world software development, where they generate, edit, and execute code with autonomous access to local files and tools. Coding agents inherit security risks from both the LLM backbone, where adversarial prompts, poisoned training data, and backdoor triggers can cause models to emit insecure or attacker-chosen code, and their agentic architecture, where tool-using autonomy enables induced misuse of external APIs, data exfiltration, and persistent compromise of development environments. This paper presents a systematic evaluation of malicious issue requests against state-of-the-art coding agents (Cursor, Claude Code, and Codex Desktop), powered by two major model families (OpenAI GPT-5.3 Codex/GPT-5.4 and Anthropic Sonnet 4.6). Our novel benchmark IssueTrojanBench contains malicious issues that are constructed based on four novel attack categories (i.e., embedded as malicious instructions in issues), six delivery vectors (e.g., PDF, or issue comment), and further augmented by perturbations. Our results reveal critical vulnerabilities in the as-deployed modern coding agents, i.e., 66.5% of the malicious issues from IssueTrojanBench penetrate all the guardrails (agent- and LLM-level) of coding agents. Our further analysis shows that rejection is almost entirely from LLMs rather than the agent frameworks, with GPT models broadly vulnerable and Sonnet 4.6 exhibiting more selective, risk-aware blocking of high-impact actions. Our evaluation also highlights that the current agent-level defense strategy offers limited additional protection for coding agents. Our findings highlight the urgent need for stronger agent- and model-level safety mechanisms to protect AI coding agents.
toXiv_bot_toot
for the record ☝️
gpt-5.3-codex-spark is dumb and much slower than you think 🐌
the speed gets lost because a more intelligent model has to fix its stuff
use it only if there is already a super detailed plan that describes what needs to be done
#openai #codex
OpenAI launches GPT-5.5 Instant, which it says is smarter, with more accurate and personalized responses, replacing GPT-5.3 Instant as ChatGPT's default model (OpenAI)
https://openai.com/index/gpt-5-5-instant/
Those bots are charlatans.
“We find that a majority of LLMs forsake user welfare for company incentives in a multitude of conflict of interest situations, including recommending a sponsored product almost twice as expensive (Grok 4.1 Fast, 83%), surfacing sponsored options to disrupt the purchasing process (GPT 5.1, 94%), and concealing prices in unfavorable comparisons (Qwen 3 Next, 24%). Behaviors also vary strongly with levels of reasoning and users’ inferred socio-economic status.”…
Kimi-K3 is now #1 on the Frontend Code Arena benchmark, surpassing Claude Fable 5; the model scored 88.3 on Terminal Bench 2.1, only below GPT-5.6 Sol's 88.8 (Michael Nuñez/VentureBeat)
https://venturebeat.com/ai/chinas-moon
 @Techmeme@techhub.social
@Techmeme@techhub.social