@NFL@darktundra.xyz
@NFL@darktundra.xyz2026-03-20 19:49:05
Draft daze: Pittsburgh to close schools for NFL https://www.espn.com/nfl/story/_/id/48259609/pittsburgh-schools-switch-remote-learning-nfl-draft
@NFL@darktundra.xyzDraft daze: Pittsburgh to close schools for NFL https://www.espn.com/nfl/story/_/id/48259609/pittsburgh-schools-switch-remote-learning-nfl-draft
 @lpryszcz@genomic.social
@lpryszcz@genomic.socialSeriously, knowing the dire predicament we are in, we should be busy learning and re-learning how to produce food, clothing and housing on a planet transitioning into a radically different climate. We desperately need a plan how to scale back on technology use, in tandem with the natural decline in resource and energy availability.
https://
 @Techmeme@techhub.social
@Techmeme@techhub.socialDeeptune, which builds high-fidelity reinforcement learning environments that simulate professional workflows for AI agents, raised a $43M Series A led by a16z (Lily Mae Lazarus/Fortune)
https://fortune.com/2026/03/19/andreessen-horowitz-ai-startups-deeptune…
 @zachleat@zachleat.com
@zachleat@zachleat.com@… we’re learning, we’re growing, we’re iterating 🙌
 @cdarwin@c.im
@cdarwin@c.imEverything we’re learning now strongly suggests that Donald Trump’s war is about to get worse.
♦️First, officials leaked word to The Washington Post that the Pentagon and the White House are likely to
💥demand $200 billion more from Congress.
Trump sort of confirmed this in remarks to reporters while adding some unsettling threats of unspecified additional military action.
♦️Second, sources told Reuters that Trump is considering the deployment of thousands of troops…
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.delivemocha: Livemocha friendship network (2010)
A network of friendships among users on Livemocha, a large online language learning community. Nodes represent users and edges represent a mutual declaration of friendship.
This network has 104103 nodes and 2193083 edges.
Tags: Social, Online, Unweighted
https://ne…

 @inthehands@hachyderm.io
@inthehands@hachyderm.ioPlease watch their charming video! Watch, and look at the faces: kids of many races and many genders, all different levels of knowledge, every one of them showing this deep-seated sense of agency and ownership about science and about their own learning: “I belong here. This is for me.” It’s everything the fascists fear.
Full disclosure: my kid is one of the kids in the program (but not in the video, sorry!). I can thus vouch for this fundraiser with extra confidence.
https://vimeo.com/1152657185
2/
 @simon_brooke@mastodon.scot
@simon_brooke@mastodon.scotOK, #Zig language looks usable, but it's going to be a learning curve, and I don't think auto-translating my existing C code to Zig is going to be either easy or worth doing, considering how dissatisfied I now am with both the design and the coding of the C code.
H'mmmm...
 @hex@kolektiva.social
@hex@kolektiva.socialIn my head I'm just replacing "counter insurgency" with "horse cavalry."
"We're going to keep learning how to leverage horse cavalry against machine guns and tanks until we get it right."
No. No you will not. You will keep trying until you learn the hard way that it can't be done.
 @georgiamuseum@glammr.us
@georgiamuseum@glammr.usMuseums don't build job skills. That's what many people think. But our newest experiential learning program is not only preparing these #UniversityOfGeorgia students for their next step, it's also building bridges between campus and community.

 @cheryanne@aus.social
@cheryanne@aus.socialThe Event Debrief
A podcast community for event planners and event professionals focused on learning, sharing ideas, and growing better events together...
Great Australian Pods Podcast Directory: https://www.greataustralianpods.com/the-event-debrief/
 @yetiinabox@todon.nl
@yetiinabox@todon.nlAcabado surveys terraced mountain agriculture - humans have been shaping montane landscapes and creating habitats worldwide for a very long time.
https://phys.org/news/2026-01-mountain-terraces-indigenous-peoples-climate.html
 @primonatura@mstdn.social
@primonatura@mstdn.social"Satellite images indicate that the Doñana Marshland will disappear within 60 years"
#Environment
https://phys.org/news/2026-02-satellite-images-doana-…
@NFL@darktundra.xyzSelf-learning AI generates NFL picks, exact score predictions for 2026 NFC, AFC Championship Games
https://www.cbssports.com/nfl/news/nfl-afc-nfc-championship-games-20…
 @theodric@social.linux.pizza
@theodric@social.linux.pizzaSpent my evening learning enough about the rpmbuild system to beat another Arch aur package into submission on openSUSE (Firefox with global menu support.)
I probably need to learn how to use quilt to properly rebase the patch on the current Firefox release rather than just forcing patching to fuzz level 3. One thing at a time.
@Techmeme@techhub.socialMiniMax releases M2.7, a proprietary "self-evolving" LLM that the company used to build, monitor, and optimize the model's own reinforcement learning harnesses (Carl Franzen/VentureBeat)
https://venturebeat.com/technology/new
@zachleat@zachleat.com@… I too did not like learning this
@cdarwin@c.imWe have learnt to look at the world through ratings, reviews, and whether a place is “Instagrammable.”
Nuance is pressed flat into a system of stars.
Even mountains and valleys are scored on Google Maps,
while countless unassuming places slip silently through the net.
I often wonder, ruefully, how much we are missing when only the ranked and the rated rise to the surface.
It begins to feel as though such systems are not merely cataloguing the world,
bu…
 @brichapman@mastodon.social
@brichapman@mastodon.socialWe avoid hard things thinking we're protecting our peace. But we might just be shrinking our lives.
Not all discomfort breaks you down. Some of it builds you up.
The question is learning which is which.
What if the thing you're avoiding is actually where your power is hiding?
New on my Substack: there's more to life than constant stability.
 @thomasfuchs@hachyderm.io
@thomasfuchs@hachyderm.ioMy years of learning the intricacies of eBay buying what’s best described as electronic waste finally paid for themselves, I got another piece of electronic waste for a really good price!
 @geant@mstdn.social
@geant@mstdn.social✨ SIG-Marcomms and SIG-MSP Joint Meeting Recap ✨
Earlier this month, NRENs gathered in Lisbon for two days of shared learning across two Special Interest Groups (SIGs).
The question that ran through both days: what changes when the people who build services and the people who communicate them work together from the very beginning?
🔗 Read the full recap:

 @UP8@mastodon.social
@UP8@mastodon.social🐞 New species of ladybird beetle discovered on university campus in Japan
#insects
 @datascience@genomic.social
@datascience@genomic.social @compfu@mograph.social
@compfu@mograph.socialRE: https://mograph.social/@thevfxfeed/116093105283317376
To be honest, a machine-learning model for Nuke where the training data is clearly sourced and free of legal baggage would be a really good thing. There are so many image segmentation and inpainti…
 @arXiv_qfinPM_bot@mastoxiv.page
@arXiv_qfinPM_bot@mastoxiv.pageDeep Reinforcement Learning for Optimal Portfolio Allocation: A Comparative Study with Mean-Variance Optimization
Srijan Sood, Kassiani Papasotiriou, Marius Vaiciulis, Tucker Balch
https://arxiv.org/abs/2602.17098
@cdarwin@c.imOne of the most amazing destinations in the Manitoba, Churchill, is known as the polar bear capital of the world.
And while seeing polar bears in the wild is certainly a once-in-a-lifetime experience,
there are many other things to do in Churchill, too.
Churchill Polar Bear Statue
x
From the Northern Lights to kayaking with belugas to learning about the local Inuit culture, we’ve put together this guide for you with everything you need to know about Churchill. …
 @jonippolito@digipres.club
@jonippolito@digipres.club"Friction makes learning more effective"—yes, but for whom? Like "discipline" and "grit," friction in the classroom may serve teachers and future bosses more than students.
Read @… @…

 @ErikJonker@mastodon.social
@ErikJonker@mastodon.socialFor people that use LLMs regularly this is probably not a surprise. In my own environment i have seen examples where for example Gemini 3.1 (paid version) is very good in creating math excercises, customized to your need/demand. There is large potential for GenAI in education.
"Our work provides large-scale field evidence that student-chatbot interactions provide valuable signals for proactively optimizing and personalizing student learning."
 @arXiv_physicsaccph_bot@mastoxiv.page
@arXiv_physicsaccph_bot@mastoxiv.pageToward a Fully Autonomous, AI-Native Particle Accelerator
Chris Tennant
https://arxiv.org/abs/2602.17536 https://arxiv.org/pdf/2602.17536 https://arxiv.org/html/2602.17536
arXiv:2602.17536v1 Announce Type: new
Abstract: This position paper presents a vision for self-driving particle accelerators that operate autonomously with minimal human intervention. We propose that future facilities be designed through artificial intelligence (AI) co-design, where AI jointly optimizes the accelerator lattice, diagnostics, and science application from inception to maximize performance while enabling autonomous operation. Rather than retrofitting AI onto human-centric systems, we envision facilities designed from the ground up as AI-native platforms. We outline nine critical research thrusts spanning agentic control architectures, knowledge integration, adaptive learning, digital twins, health monitoring, safety frameworks, modular hardware design, multimodal data fusion, and cross-domain collaboration. This roadmap aims to guide the accelerator community toward a future where AI-driven design and operation deliver unprecedented science output and reliability.
toXiv_bot_toot
 @usul@piaille.fr
@usul@piaille.frTwo Years of Building AI in Firefox | Tarek Ziadé
https://blog.ziade.org/2025/12/05/two-years-of-ai-at-mozilla/?trk=feed_main-feed-card_feed-article-content
 @frankel@mastodon.top
@frankel@mastodon.top @v_i_o_l_a@openbiblio.social
@v_i_o_l_a@openbiblio.social"Digital Learning: Exploring Perceived Usefulness and Perceived Ease of Use of Open Educational Resources"
#OpenIrony
 @kexpmusicbot@mastodonapp.uk
@kexpmusicbot@mastodonapp.uk🇺🇦 #NowPlaying on KEXP's #PacificNotions
Passarani:
🎵 Learning To Let Go
#Passarani
https://marcopassarani.bandcamp.com/track/learning-to-let-go
 @almad@fosstodon.org
@almad@fosstodon.orgToday I had a nonironic conversation about why I think learning in human works differently than iteratively building a SKILL.md that you drop into a context to condition the LLM neural net.
I’m starting to understand why old people go around saying how tired they are…
@NFL@darktundra.xyz49ers say they'll keep Mac Jones, but stars could be aligning for a trade https://www.nytimes.com/athletic/7045014/2026/02/19/mac-jones-trade-49ers-offseason/
@cheryanne@aus.social @jerome@jasette.facil.services
@jerome@jasette.facil.servicesI was hoping that all those Finch LRT closures were just part of the learning process to operate it.
Now with the line shut down on the day AFTER a storm, I wonder if the whole engineering of it is wrong.
Going to be much more expensive to fix.
#ttc #finchwestlrt<…
 @doktrock@toad.social
@doktrock@toad.social2026 Shipboard Immersion - Waterfronts Past & Present: Learning How Engineers Design with Nature
"Opportunity to learn about the #GreatLakes and coastal engineering in Milwaukee."
For "formal or nonformal educators who teach at the middle or high-school level that are experienced or new to the Great Lakes Literacy Principles"
STIPENDS Will be provided to o…
 @cowboys@darktundra.xyz
@cowboys@darktundra.xyzJoe Milton reflects on learning moments, growth in year one with Cowboys https://www.dallascowboys.com/news/joe-milton-reflects-on-learning-moments-growth-in-year-one-with-cowboys
@inthehands@hachyderm.ioI’ve felt for a decade like I’m a fool for deploying on either self-managed Linux VMs or (for small projects) free tier Heroku, and now I feel like I was accidentally doing it the smart way the whole time and didn’t know it.
…or maybe I’m still in the familiarity bias phase of learning a new tool?
 @candidexmedia@mastodon.design
@candidexmedia@mastodon.design@0xdjdev@mastodon.art Here are my recs:
General design principles: https://baselinehq.com/course.html
For learning software tools: If you can access Lynda.com / LinkedIn Learning through your public library, I highly recommend it.
Additional Learning Resources:
- Extra Bold:
 @raiders@darktundra.xyz
@raiders@darktundra.xyzRaiders’ Maxx Crosby ‘livid, confused’ at first over rescinded trade https://www.reviewjournal.com/sports/raiders/raiders-maxx-crosby-livid-confused-at-first-over-rescinded-trade-3726127/
 @curiouscat@fosstodon.org
@curiouscat@fosstodon.orgThe Leader's Handbook Study Series
https://www.in2in.org/shop/p/the-leadership-handbook-study-series
In his forward to the Leader’s Handbook Ackoff offers a format to study the book which we will follow in these sessions:
“I suggest a small group …
 @michabbb@social.vivaldi.net
@michabbb@social.vivaldi.net🖼️ Native vision-language design with early multimodal fusion trained on massive text-image-video data
🌍 Expanded multilingual coverage to 201 languages & dialects
🤖 Demonstrates visual agent workflows across mobile & desktop interfaces beyond passive chat
📊 First open-weight release: Qwen3.5-397B-A17B ultra-sparse MoE model
🔬 Large-scale reinforcement learning across multi-agent environments for real-world adaptability
 @rasterweb@mastodon.social
@rasterweb@mastodon.socialIt's been a while since I used Processing but I'm happy to say I can still launch it and quickly write a silly application in a dozen lines of code in about 10 minutes.
https://processing.org/
 @mcdanlj@social.makerforums.info
@mcdanlj@social.makerforums.infoI've spent the past year learning Morse code, and it's ended up being a great deal of fun. I've had a lot of questions. I've tried to share what I've learned with others as I've gone along.
To celebrate the end of the year, I wrote a combination of information, story, and advice. How to get started, mobile apps and websites, books, getting on the air, learning to send, POTA, SST, keys and keyers. I'm not fluent or expert yet, but that means that I still remember what's hard!
 @outer@mas.to
@outer@mas.to“The beautiful thing about learning is nobody can take it away from you.”
― B.B. King
#Learning #Music #Knowledge
@netzschleuder@social.skewed.delivemocha: Livemocha friendship network (2010)
A network of friendships among users on Livemocha, a large online language learning community. Nodes represent users and edges represent a mutual declaration of friendship.
This network has 104103 nodes and 2193083 edges.
Tags: Social, Online, Unweighted
https://ne…

 @berlinbuzzwords@floss.social
@berlinbuzzwords@floss.socialOnly one month remains until our Call for Papers ends!
Seize the opportunity to submit your proposal for this year's Berlin Buzzwords and be part of Europe’s leading conference for modern data infrastructure, search, and machine learning.
Submit now: https://2026.berlinbuzzwords.de/call-for-papers/

 @AimeeMaroux@mastodon.social
@AimeeMaroux@mastodon.socialA friend who is a teacher claimed that LLMs can write consistent plots now and are allegedly used for stories in textbooks or course material in language learning classes.
I find that quite hard to believe because in my limited experience, what information the #LLM will "remember" is quite random and it will just make stuff up if it "forgot", i.e. it doesn't matter if I…
 @Adam@social.lein.us
@Adam@social.lein.usLearning how to use the new 70-100mm 200Mp camera on the Xiaomi 17 Ultra. Not bad! https://www.instagram.com/p/DUvtwhPkRBl/?img_index=1
 @lightweight@mastodon.nzoss.nz
@lightweight@mastodon.nzoss.nzHello all - it's that time again - tomorrow evening, Tue 13 Jan, at 20:00 NZDT, we'll be having our Jan Libre/FOSS meeting at https://meeting.iridescent.nz - anyone welcome to join us. It'll be held on our BigBlueButton instance (thanks to Prodigi.nz for sponsored hosting infrastructure!). We'll …
 @timbray@cosocial.ca
@timbray@cosocial.caWhere we’re at is like learning the right way to operate the controls of a large passenger airliner.
While it’s full of passengers.
“Under “contributing factors” the note included “novel GenAI usage for which best practices and safeguards are not yet fully established.”
“Junior and mid-level engineers will now require more senior engineers to sign off any AI-assisted changes, Treadwell added.”

 @davidaugust@mastodon.online
@davidaugust@mastodon.onlineLearning about mass defects, or the change in mass due to nuclear binding energy in atoms.
Also, all forms of potential energy, like nuclear binding energy, change the mass of the system they're part of.
So when you go upstairs, you increase your potential energy (what would become kinetic if you fell down the stairs) and so increase your mass (a tiny amount).
But, since you are farther from the center of the Earth, when you go upstairs, you lower your weight.
1/…
 @dennisfaucher@infosec.exchange
@dennisfaucher@infosec.exchangeRun your own local chat on your laptop. Plus add web search like Perplexity. I do this on my Mac to to save a few AI DC BTUs and to learn stuff based on real web pages rather than hallucinated LLMs.
• Run your own chat: https://carlosvaz.com/posts/running-ll
 @cellfourteen@social.petertoushkov.eu
@cellfourteen@social.petertoushkov.euI am developing
a strong trust issue
with corporations
People around me
respected professionals
one by one falling under the AI spell
learning to worship it daily
despite it eating up their lives
in front of their eyes
The orange man
in a semi bulldozed
shiny White House
at the top of the hill
halfway across the world
bragging about his non-war
shrugging off 165 girls murdered
aged between 7 and 12
as the …
 @thesaigoneer@social.linux.pizza
@thesaigoneer@social.linux.pizzaOf course, before heading out at 4AM tomorrow morning, I had to wrap up that laptop. And finally got LUKS LVM with EfiBootmanager working on Gentoo🥳Close to 20 installs and still learning new things, great.
When I come back I'll be doing a clean install of dwm 6.8 on it. Not just re-making my old dots.Now that's something to look forward to!
#archlabs
@cdarwin@c.imA damning new study could put AI companies on the defensive.
In it, Stanford and Yale researchers found compelling evidence that AI models are actually copying all that data,
not “learning” from it.
Specifically, four prominent LLMs
— OpenAI’s GPT-4.1, Google’s Gemini 2.5 Pro, xAI’s Grok 3, and Anthropic’s Claude 3.7 Sonnet
— happily reproduced lengthy excerpts from popular
— and protected
— works, with a stunning degree of accuracy.
They fou…
@thomasfuchs@hachyderm.io @emd@cosocial.ca
@emd@cosocial.ca @ruth_mottram@fediscience.org
@ruth_mottram@fediscience.orgMachine Learning techniques are upending multiple scientific fields. Operational 5-day forecasting of air quality in 1 minute in this paper from Chinese researchers.
This is awesome work with very clear public health implications.
EDIT for clarity: I am.not suggesting LLMs have anything to do with this work, but many people hear AI and imagine LLMs. And many of them.are perhaps rightly sceptical of AI as a result.
But AI or ML techniques can be useful for lots of things, not just chatbots. And we should probably invest more in those.
https://www.nature.com/articles/s41586-026-10234-y
 @dr2chase@ohai.social
@dr2chase@ohai.socialIs Our Computers Learning?
"The name on your account must exactly match the name on your reservations to ensure that you receive mileage credit and other benefits."
Global Entry number matches, passport number matches, date of birth matches, but no, if there's a difference in the name, including that usually optional middle initial and/or full middle name, I'm sorry, we were too busy training LLMs to handle basic fucking database 101.
 @mszll@datasci.social
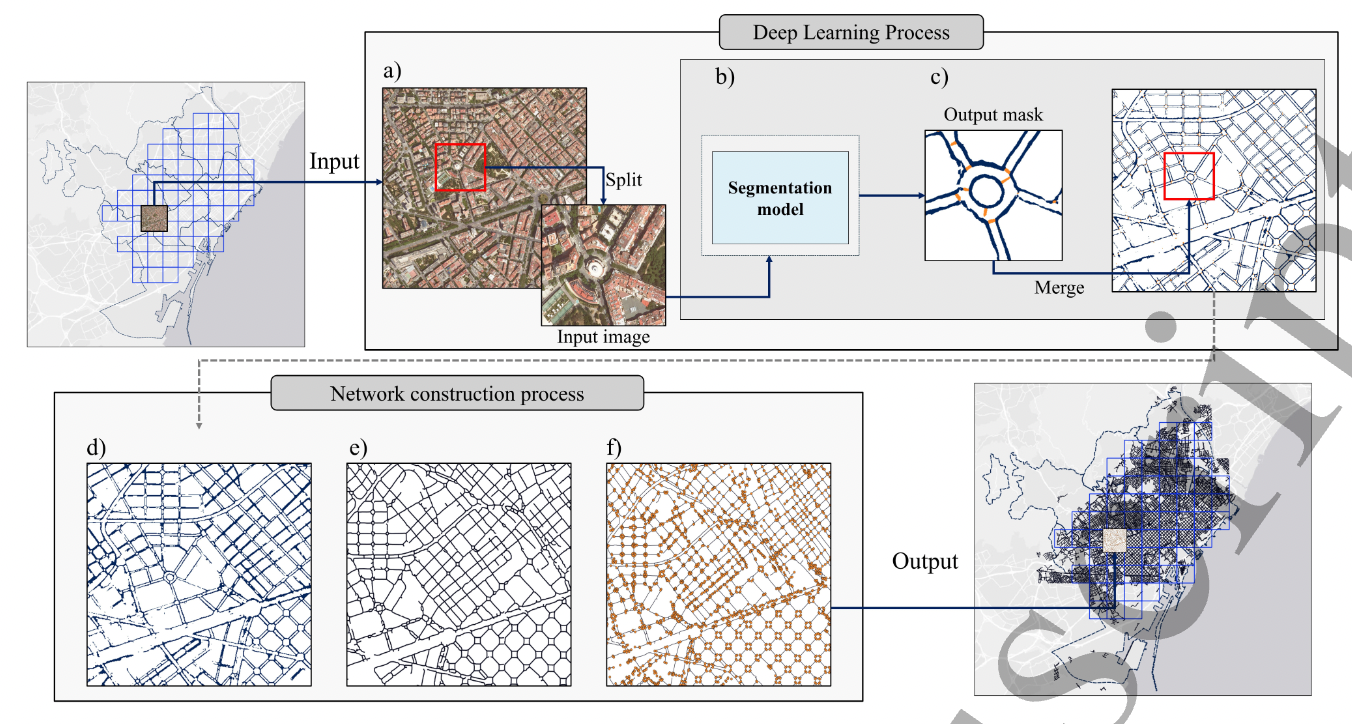
@mszll@datasci.socialMind the gap: Revealing sidewalk networks at scale
pdf: https://iopscience.iop.org/article/10.1088/2632-072X/ae35b9/pdf
Nice to see important research on the both most important and neglected mode of transport 🚶
 @grumpybozo@toad.social
@grumpybozo@toad.socialThis is my 1st time learning of #Guacamole, despite being an ASF Member. Looks cool…
Basically a J2EE app that talks HTML5 with WebSocket (or falls back to a custom HTTP-based stream proto) to a JS client in the browser on the front end, and speaks its own abstract remote desktop proto to a backend proxy that talks RDP or VNC to desktop servers. Apparently there’s also a X11 graphics drive…
 @cheryanne@aus.social
@cheryanne@aus.socialRMS Hospitality Learning Labs
A practical webinar series from RMS that explore how technology can make hospitality simpler, smarter, and more human...
Great Australian Pods Podcast Directory: https://www.greataustralianpods.com/rms-hospitality-learning-labs/
 @relcfp@mastodon.social
@relcfp@mastodon.socialWhy Teaching Jewish Texts in Not Enough
https://ift.tt/tLT9ZpM
Slave subjectivities in the Iberian Worlds (15th- 20th centuries) Date: October 31,…
via Input 4 RELCFP https://
 @radioeinsmusicbot@mastodonapp.uk
@radioeinsmusicbot@mastodonapp.uk🇺🇦 Auf radioeins läuft...
Tom Petty & The Heartbreakers:
🎵 Learning To Fly
#NowPlaying #TomPetty #TheHeartbreakers
https://djeddyredrums.bandcamp.com/track/tom-petty-and-the-heartbreakers-learning-to-fly-dj-eddy-rockdrum
https://open.spotify.com/track/17S4XrLvF5jlGvGCJHgF51
 @bourgwick@heads.social
@bourgwick@heads.social50 years ago tonight in palo alto, the last of two shows by the jerry garcia band as half-accidental backing combo for piano genius james booker, a loose cannon’s loose canon, band sometimes sounding as if they’re learning songs on the fly. audience tape: https://archive.org/details/jg76-01-10<…
 @theodric@social.linux.pizza
@theodric@social.linux.pizzaI'm afraid that's all I wanted help with
 @UP8@mastodon.social
@UP8@mastodon.social🎶 TweetyBERT parses canary songs to better understand how brains learn language
#birds
@Techmeme@techhub.socialHow Disney Imagineering built an Olaf robot, set to arrive at Disneyland Paris this month, and taught it to move via reinforcement learning and simulation (Jacob Krol/TechRadar)
https://www.
@cowboys@darktundra.xyzJoe Milton reflects on learning moments, growth in year one with Cowboys https://www.dallascowboys.com/news/joe-milton-reflects-on-learning-moments-growth-in-year-one-with-cowboys
@frankel@mastodon.top @netzschleuder@social.skewed.delivemocha: Livemocha friendship network (2010)
A network of friendships among users on Livemocha, a large online language learning community. Nodes represent users and edges represent a mutual declaration of friendship.
This network has 104103 nodes and 2193083 edges.
Tags: Social, Online, Unweighted
https://ne…
 @primonatura@mstdn.social
@primonatura@mstdn.social"AI for Nature Restoration Tools: How Companies are Transforming Ecosystem Recovery Projects"
#AI #ArtificialIntelligence #Nature
@Techmeme@techhub.socialHow an appeal changed the way the USPTO assesses AI patents under the US Patent Act, signaling a shift towards more favorable treatment of AI and ML inventions (Matthew Carey/Bloomberg Law)
https://news.bloomberglaw.com/tech-and
@NFL@darktundra.xyzCamaraderie, learning from each other has led rebuilt Patriots' offensive line https://www.nfl.com/news/patriots-offensive-line-camaraderie-learning-from-each-other-super-bowl-lx
@cowboys@darktundra.xyzMailbag: Learning from past mistakes? https://www.dallascowboys.com/news/mailbag-learning-from-past-mistakes
@ruth_mottram@fediscience.orgThe preprint of the paper is here btw: #MachineLearning methods to emulate #Greenland ice sheet melt via European Weather Cloud computing
https://europeanweather.cloud/use-cases/machine-learning-emulation-accelerate-climate-science
@inthehands@hachyderm.ioRE: https://mastodon.social/@airspeedswift/116070142432692632
Reflections on Trusting Trust and the Trust You’re Trusting is an Opaque, Nondeterministic Machine Learning Model
@netzschleuder@social.skewed.delivemocha: Livemocha friendship network (2010)
A network of friendships among users on Livemocha, a large online language learning community. Nodes represent users and edges represent a mutual declaration of friendship.
This network has 104103 nodes and 2193083 edges.
Tags: Social, Online, Unweighted
https://ne…
 @raiders@darktundra.xyz
@raiders@darktundra.xyzRaiders alumni, staff receive a 'priceless' learning experience in the Las Vegas Historic Westside https://www.raiders.com/news/raiders-alumni-staff-receive-priceless-learning-experience-in-the-las-vegas-historic-we…
@UP8@mastodon.social⚰️ Fentanyl or phony? Machine learning algorithm learns to pick out opioid signatures
#sensors
@NFL@darktundra.xyzSelf-learning AI generates NFL picks, score predictions for every 2026 divisional round matchup
https://www.cbssports.com/nfl/news/nfl-divisional-round-2026-picks-ai-score-predi…
@primonatura@mstdn.social @Techmeme@techhub.socialUkrainian-founded language learning marketplace Preply raised a $150M Series D led by WestCap at a $1.2B valuation; the startup has a 150-person office in Kyiv (Anna Heim/TechCrunch)
https://techcrunch.com/2026/01/21/langu…
@thomasfuchs@hachyderm.ioThe two best feelings in the world are:
1. Helping another person
2. Learning something new
Interesting how both big tech with “AI” and “conservatives” do not want you to do either.
@ruth_mottram@fediscience.orgProud PhD supervisor moment: @… have nice write up to Elke Schlager's brilliant work, (now a preprint in @…) on how we can use #MachineLearning methods to emulate #Greenland ice sheet melt via European Weather Cloud computing
https://europeanweather.cloud/use-cases/machine-learning-emulation-accelerate-climate-science
@cdarwin@c.imLearning To See Again:
For over twenty years I've been seeking out alternative stories in our surviving material culture and sharing them with my photographs and words.
-- Andy Marshall
https://www.digest.andymarshall.co/about-2/
@cheryanne@aus.socialEasy Croatian - Lagani hrvatski
Brought to you by SBS Croatian and the Croatian Studies Centre at Macquarie University, intended for those learning or wanting to brush up on their Croatian...
Great Australian Pods Podcast Directory: https://www.greataustralianpods.com/easy-croati…
 @inthehands@hachyderm.io
@inthehands@hachyderm.ioPart of the answer is that the district has given all students the option to stay home and do remote learning for the next month. Good. I mean, that really sucks for the families doing it, it sucks that any families are boxed into that corner — but good for the district coming up with that option.
That doesn’t mean that school is safe, however — not even for families who aren’t being targeted by ICE.
2/
@cdarwin@c.imCETI is a nonprofit organization
applying advanced machine learning and state-of-the-art robotics
to listen to and translate the communication of sperm whales.
Our research focus is in Dominica
in the Eastern Caribbean
https://www.projectceti.org/
@NFL@darktundra.xyzNFL Divisional Round anytime touchdown scorer picks, odds: Model locks in anytime TD scorer best bets
https://www.cbssports.com/nfl/news/nfl-divi…
@cheryanne@aus.socialMagical Learning Podcast
With a holistic view, this podcast covers not only how to improve your business, but how to help your employees enjoy their work, and how to improve yourself...
Great Australian Pods Podcast Directory: https://www.greataustralianpods.com/magical-learni…
 @inthehands@hachyderm.io
@inthehands@hachyderm.ioI’ve just had occasion to use Svelte / SvelteKit on a web project, and…
…it’s quite good. The core features are well chosen, and they work. The learning curve pays dividends. The resulting code is reasonably pleasant to read. As often as not, the surprises have sensible decisions behind them. It feels like it •is• the thing that React is •trying to be•.
There are gaps and quirks and barriers — it is a tool, after all — but if you’re writing a highly interactive SPA-style site, it gets the Paul Seal of Approval.
@Techmeme@techhub.socialA profile of Amanda Askell, Anthropic's resident philosopher, who is learning Claude's reasoning patterns in a bid to endow it with a sense of morality (Wall Street Journal)
https://www.wsj.com/tech/ai/anthropic-aman
@NFL@darktundra.xyzRavens vs. Steelers NFL player props, SGP: Self-learning AI backs Aaron Rodgers Over 1.5 passing TDs on 'SNF'
https://www.cbssports.com/nfl/news/ravens-steelers-nf…
@Techmeme@techhub.socialGoogle's experience in India has become a proving ground to scale AI in education, as the country accounts for the highest global usage of Gemini for learning (Jagmeet Singh/TechCrunch)
https://techcrunch.com/2026/01/29/india-is-teaching-google-h…
@NFL@darktundra.xyzSelf-learning AI generates 2026 Super Bowl picks, score prediction for Seahawks vs. Patriots
https://www.cbssports.com/nfl/news/super-bowl-2026-…