 @andyq@mastodon.social
@andyq@mastodon.social2026-01-25 21:13:00
Got one of those little Polono P31s thermal label printers from shown on TikTok - actually a neat little gadget, only thing I'm not a fan of the Labelnise app - no idea what/if its sending out. So with the assistance of Claude, knocked up a small Python CLI to print text, images, qr and barcodes to it over BLE.
https://

 @hynek@mastodon.social
@hynek@mastodon.social2026-03-24 15:54:38
Here’s a prometheus-async 26.1.0 with improved Twisted support courtesy of the Twisted Lord @… himself!
https://github.com/hynek/prometheus-async/relea…
 @Mediagazer@mstdn.social
@Mediagazer@mstdn.social2026-03-24 16:55:42
AAM: WaPo's average daily print circulation fell 21.2% YoY in the six months to September 30, 2025; LAT's fell 19.8%, WSJ's 12.9%, NYT's 8.6%, and NYP's 4.2% (Alice Brooker/Press Gazette)
https://pressgazette.co.uk/north-ameri

 @seeingwithsound@mas.to
@seeingwithsound@mas.to2026-03-24 06:43:15
Forbes: Are humans the only primates with white eyes? An evolutionary biologist explains the research https://www.forbes.com/sites/scotttravers/2026/03/22/why-are-humans-the-only-primates-with-white-eyes-an-e…

 @kctipton@mas.to
@kctipton@mas.to2026-02-25 01:45:52
ICE Took Their Papers—and Won’t Give Them Back – Mother Jones https://www.motherjones.com/politics/2026/02/ice-detention-keeping-not-returning-immigration-documents-work-permits/

 @blakes7bot@mas.torpidity.net
@blakes7bot@mas.torpidity.net2026-02-24 07:27:09
#Blakes7 Series C, Episode 08 - Rumours of Death
ORAC: To cross it undetected would be impossible.
AVON: I'll take your best option within the perimeter.
https://blake.torpidity.net/m/308/378…

 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2026-01-25 20:00:05
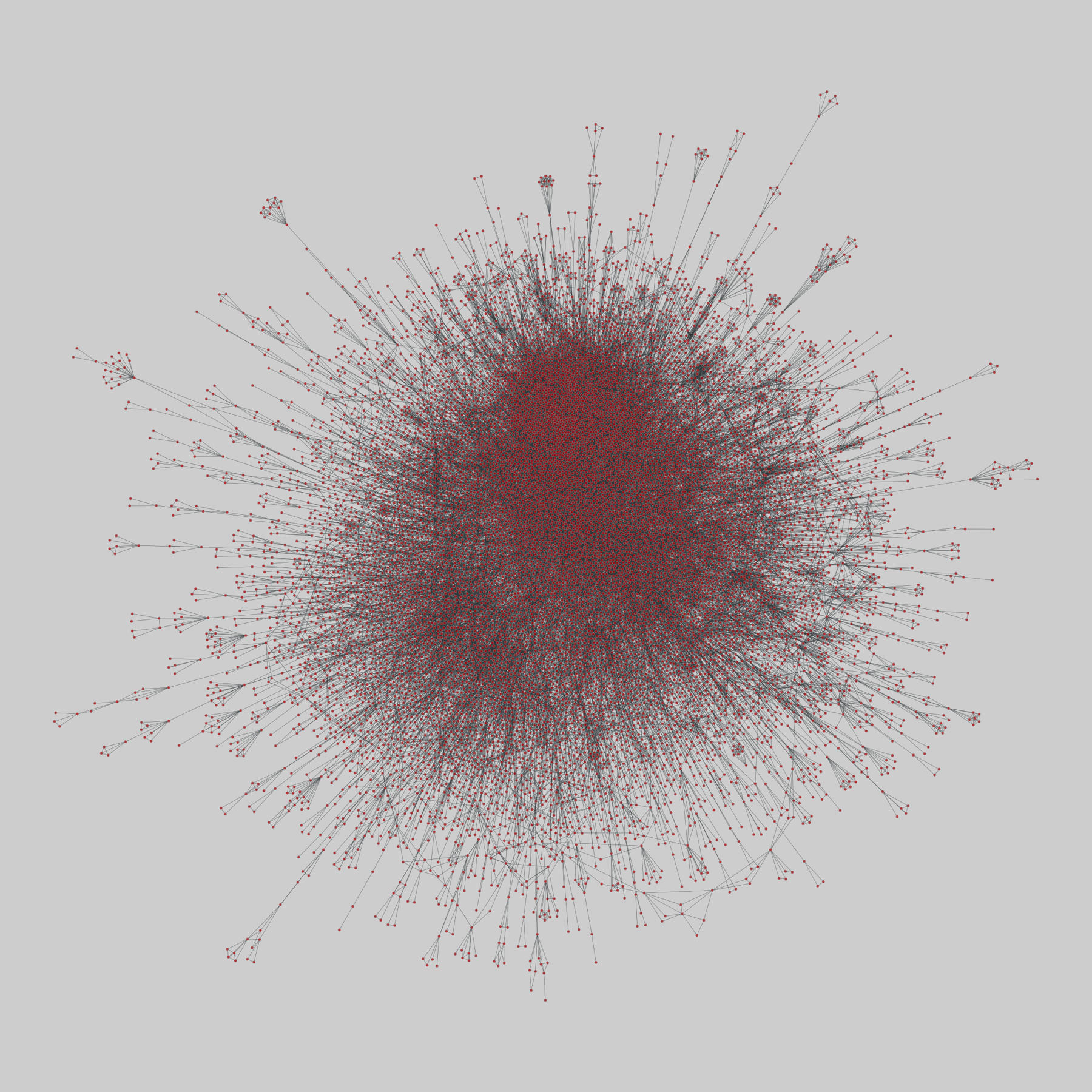
arxiv_collab: Scientific collaborations in physics (1995-2005)
Collaboration graphs for scientists, extracted from the Los Alamos e-Print arXiv (physics), for 1995-1999 for three categories, and additionally for 1995-2003 and 1995-2005 for one category. For copyright reasons, the MEDLINE (biomedical research) and NCSTRL (computer science) collaboration graphs from this paper are not publicly available.
This network has 16726 nodes and 47594 edges.
Tags: Social, Collaboratio…
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.page2026-02-25 10:37:11
Exploring the Impact of Parameter Update Magnitude on Forgetting and Generalization of Continual Learning
JinLi He, Liang Bai, Xian Yang
https://arxiv.org/abs/2602.20796 https://arxiv.org/pdf/2602.20796 https://arxiv.org/html/2602.20796
arXiv:2602.20796v1 Announce Type: new
Abstract: The magnitude of parameter updates are considered a key factor in continual learning. However, most existing studies focus on designing diverse update strategies, while a theoretical understanding of the underlying mechanisms remains limited. Therefore, we characterize model's forgetting from the perspective of parameter update magnitude and formalize it as knowledge degradation induced by task-specific drift in the parameter space, which has not been fully captured in previous studies due to their assumption of a unified parameter space. By deriving the optimal parameter update magnitude that minimizes forgetting, we unify two representative update paradigms, frozen training and initialized training, within an optimization framework for constrained parameter updates. Our theoretical results further reveals that sequence tasks with small parameter distances exhibit better generalization and less forgetting under frozen training rather than initialized training. These theoretical insights inspire a novel hybrid parameter update strategy that adaptively adjusts update magnitude based on gradient directions. Experiments on deep neural networks demonstrate that this hybrid approach outperforms standard training strategies, providing new theoretical perspectives and practical inspiration for designing efficient and scalable continual learning algorithms.
toXiv_bot_toot
@Mediagazer@mstdn.social2026-02-24 02:55:39
The Boston Globe won't print a paper for February 24 delivery due to the blizzard, the first time executives canceled a print edition in its 153-year history (Aidan Ryan/The Boston Globe)
https://www.bostonglobe.com/2026/02/23/business/boston-globe-…
