 @carloshr@lile.cl
@carloshr@lile.cl2026-05-17 18:28:28
Trent Reznor, el hombre de Nine Inch Nails, hoy celebra 61 años de vida. Nació el 17 de mayo de 1965. Ojalš que lo tengamos de visita pronto por estos lados.
#TrentReznor #CumpleañosRockero #NineInchNails

 @grumpybozo@toad.social
@grumpybozo@toad.social2026-07-17 22:12:05
So, https://mastodon.social/@JenniferSmith345 is an odd bot. I don’t think it’s even a LLM behind it, the replies are just too weird.
Profile looks like it was taken from someone real…

 @cellfourteen@social.petertoushkov.eu
@cellfourteen@social.petertoushkov.eu2026-05-19 06:32:01
A.Word.A.Day --laconism
"The Laconians, especially the Spartans, were famous for verbal thrift. When Philip II of Macedon warned that if he invaded Laconia he would destroy Sparta, the Spartans reportedly replied: 'If.'"
https://wordsmith.org/words/laconism.html
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2026-05-17 23:00:05
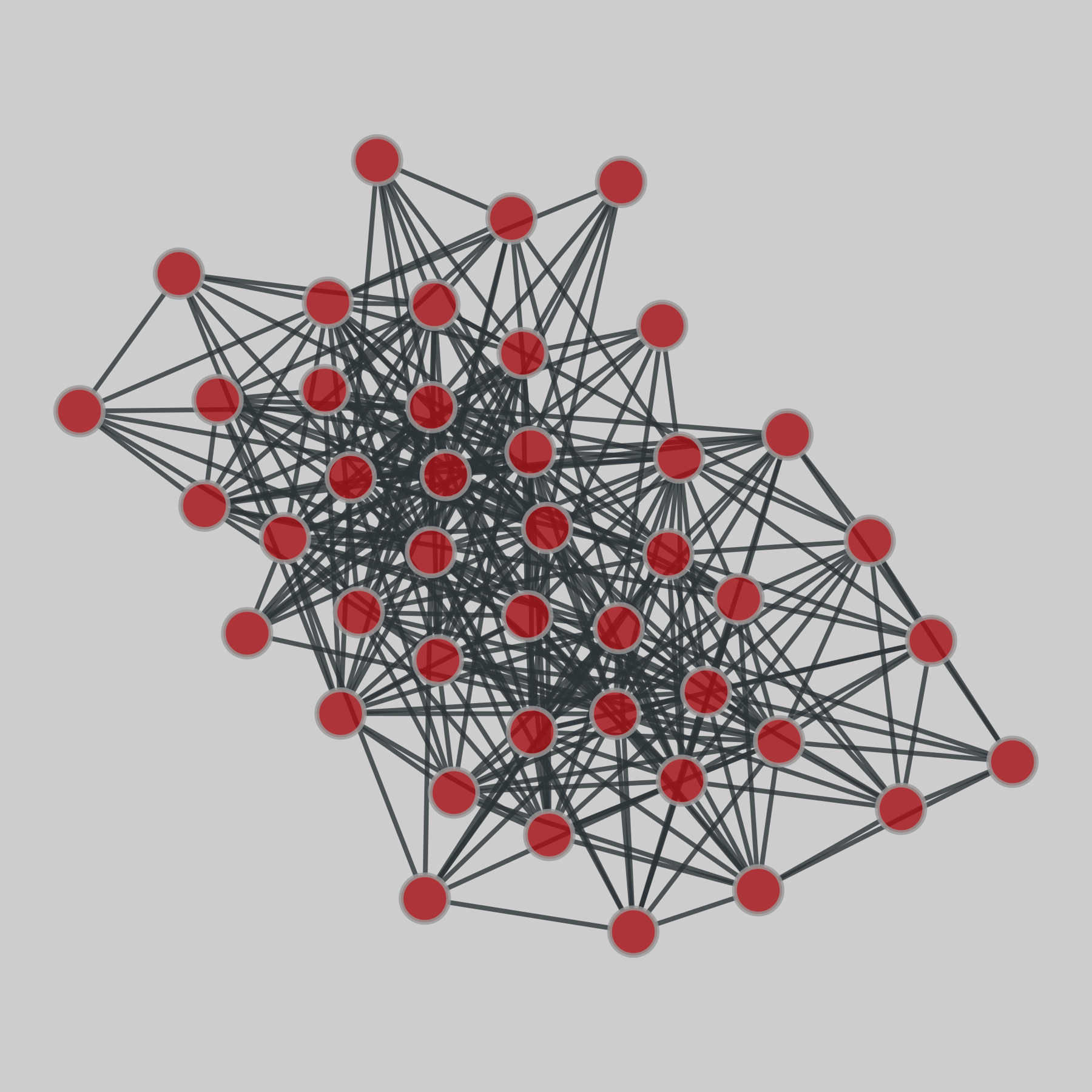
windsurfers: Windsurfers network (1986)
A network of interpersonal contacts among windsurfers in southern California during the Fall of 1986. The edge weights indicate the perception of social affiliations majored by the tasks in which each individual was asked to sort cards with other surfer’s name in the order of closeness.
This network has 43 nodes and 336 edges.
Tags: Social, Offline, Weighted
 @Carwil@mastodon.online
@Carwil@mastodon.online2026-05-16 20:11:42
Fascinating details on the Max & Marianne Weber/Else von Richtofen; Erwin Schrodinger et al.; Virginia Woolf et al. polycules in this publication…
Storming then Performing": Historical Non‑Monogamy
and Metamour Collaboration
https://link.springer.com/article/10.1
 @cdarwin@c.im
@cdarwin@c.im2026-07-15 23:19:49
On Monday, two days before the Senate hearing to consider Todd Blanche’s nomination to become the nation’s chief law enforcement official,
a federal judge strongly suggested that he may not even be fit to practice law.
Of all the powers Americans give their government,
none can curtail personal liberty like those of the Department of Justice,
and this editorial board has listed the ways Mr. Blanche has abused that authority.
He has celebrated the Jan. 6 rioters…
 @cellfourteen@social.petertoushkov.eu
@cellfourteen@social.petertoushkov.eu2026-05-17 09:04:16
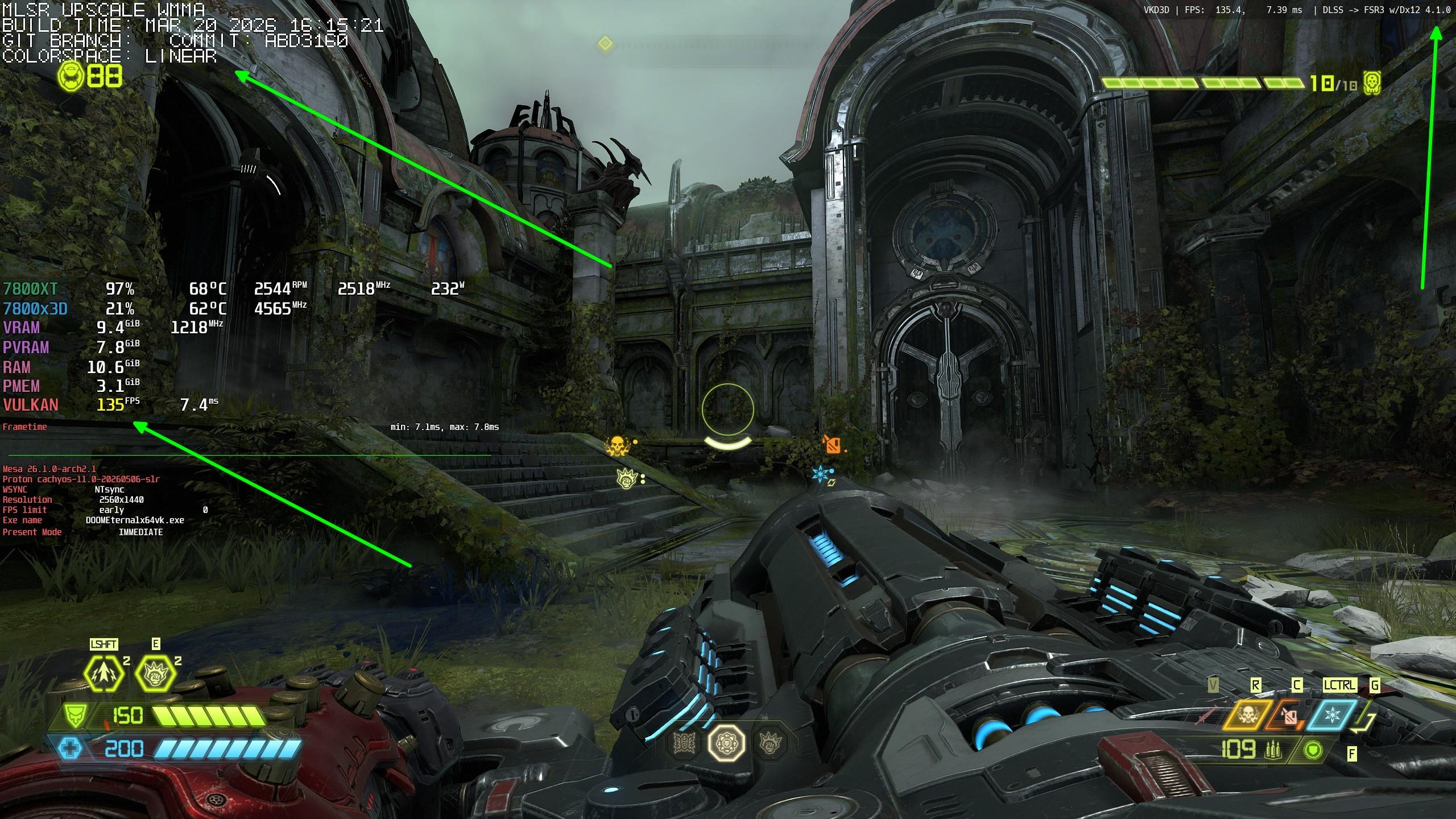
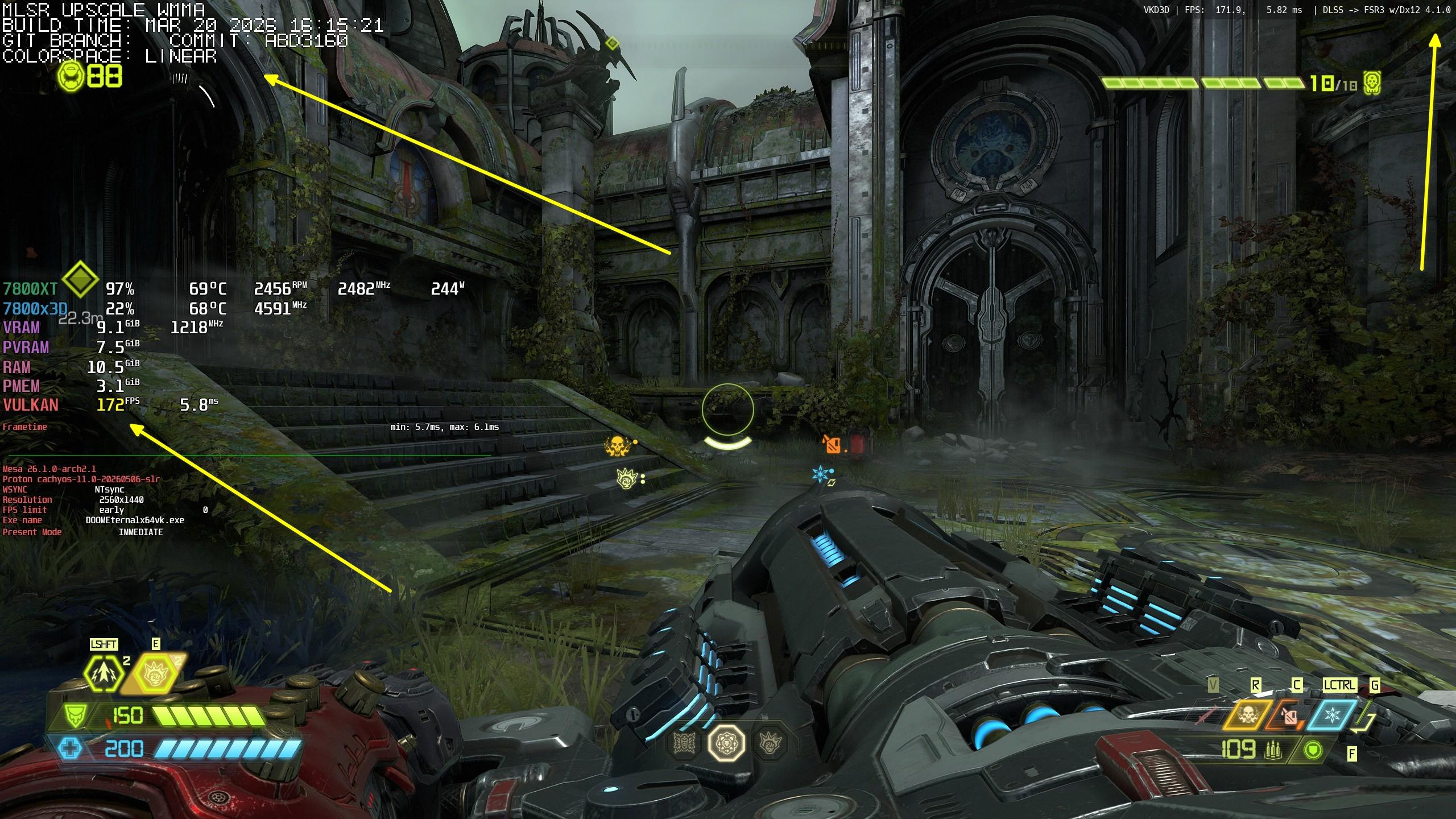
I finally cracked it! Not ideal, but it's working. For more than a month on #CachyOS #Linux (RDNA3), Doom Eternal just froze on me after some time when I tried running it with #OptiScaler
 @tiotasram@kolektiva.social
@tiotasram@kolektiva.social2026-07-12 16:28:07
Since it was relevant to a discussion I just had on here and is something most people probably haven't thought about much (unless you've taken one of a handful of philosophy classes), I thought I'd try to lay out a key piece of Descartes' Meditations (#philosophy
 @relcfp@mastodon.social
@relcfp@mastodon.social2026-05-16 16:30:19
Renaissance Conference of Southern California (RCSC)-Sponsored Panels for RSA Philadelphia
https://ift.tt/NFTr2O7
updated: Friday, May 15, 2026 - 11:45amfull name / name of organization: Renaissance Conference of…
via Input 4 RELCFP
@relcfp@mastodon.social2026-05-16 16:30:18
Renaissance Conference of Southern California (RCSC)-Sponsored Panels for RSA Philadelphia
https://ift.tt/NFTr2O7
updated: Friday, May 15, 2026 - 11:45amfull name / name of organization: Renaissance Conference of…
via Input 4 RELCFP