@toxi@mastodon.thi.ng
@toxi@mastodon.thi.ng2025-07-18 16:34:20
Memoirs of the CP/M creator released:
“Our father, Gary Kildall, was one of the founders of the personal computer industry, but you probably don’t know his name. Those who have heard of him may recall the myth that he ‘missed’ the opportunity to become Bill Gates by going flying instead of meeting with IBM. Unfortunately, this tall tale paints Gary as a ‘could-have-been,’ ignores his deep contributions, and overshadows his role as an inventor of key technologies that define how compute…

 @tiotasram@kolektiva.social
@tiotasram@kolektiva.social2025-08-19 05:08:29
Just finished Transiruby, along with a 9k-line journal file for it. I almost got 100, but not quite; I don't have time to go back to it before the semester starts though.
If you like exploration games, it's an excellent one, with great level design & tons of secrets. It actually makes you do significant secret-finding and map-reading in order to beat the game, not just for extras or a special ending, which is something that a lot of metroidvania games since Super Metroid don't do. My one complaint is that the map system isn't perfect, and finding obscure secrets to progress is fine when the map hints at them but much less fun when it hints incorrectly (I looked one progress item up in a speedrun video because of this).
Decently cool movement mechanics, although the combat does take a back seat and almost all of the bosses are easy (I beat the final two bosses in the third and second tries respectively). I don't think that's any better or worse than a game like Nine Sols where the final boss took me hundreds of tries though; just a different flavor. The world-building isn't as rich as the more epic metroidvanias like Hollow Knight or Lone Fungus (or again, Nine Sols) but again I'm fine with that. It's just a more casual game that has really excellent level design & exploration poetics.
#AmPlaying
 @Techmeme@techhub.social
@Techmeme@techhub.social2025-06-19 08:55:38
An interview with Craig Federighi on the journey to iPadOS' new windowing system and menu bar, the iPad's essence as a "magical piece of glass", and more (Federico Viticci/MacStories)
https://www.macstories.net/…

 @vosje62@mastodon.nl
@vosje62@mastodon.nl2025-09-19 09:03:02
Samsung brings ads to US fridges | The Verge
https://www.theverge.com/news/780757/samsung-brings-ads-to-us-fridges
Daar stond je als je als consument echt niet op te wachten...

 @netzschleuder@social.skewed.de
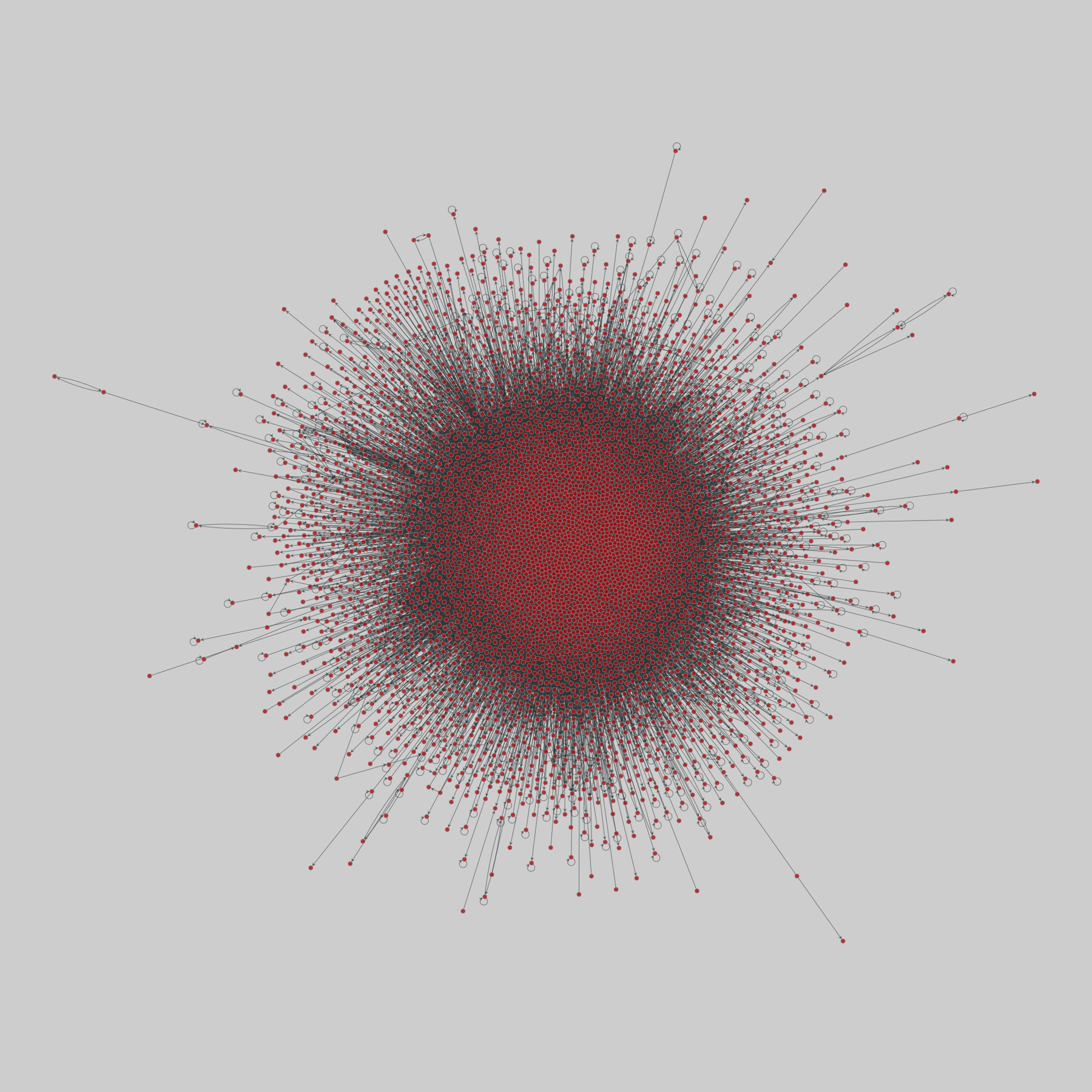
@netzschleuder@social.skewed.de2025-08-19 09:00:04
advogato: Advogato trust network (2009)
A network of trust relationships among users on Advogato, an online community of open source software developers. Edge direction indicates that node i trusts node j, and edge weight denotes one of four increasing levels of declared trust from i to j: observer (0.4), apprentice (0.6), journeyer (0.8), and master (1.0).
This network has 6541 nodes and 51127 edges.
Tags: Social, Online, Weighted
 @Techmeme@techhub.social
@Techmeme@techhub.social2025-08-18 01:15:33
A profile of Epic Systems CEO Judy Faulkner, who has led the EHR software company for 46 years, building it into one of the largest US private tech companies (Ashley Capoot/CNBC)
https://www.cnbc.com/2025/08/16/how-epics-82-year-old-ceo…

 @arXiv_csSE_bot@mastoxiv.page
@arXiv_csSE_bot@mastoxiv.page2025-09-18 09:38:01
A Study on Thinking Patterns of Large Reasoning Models in Code Generation
Kevin Halim, Sin G. Teo, Ruitao Feng, Zhenpeng Chen, Yang Gu, Chong Wang, Yang Liu
https://arxiv.org/abs/2509.13758
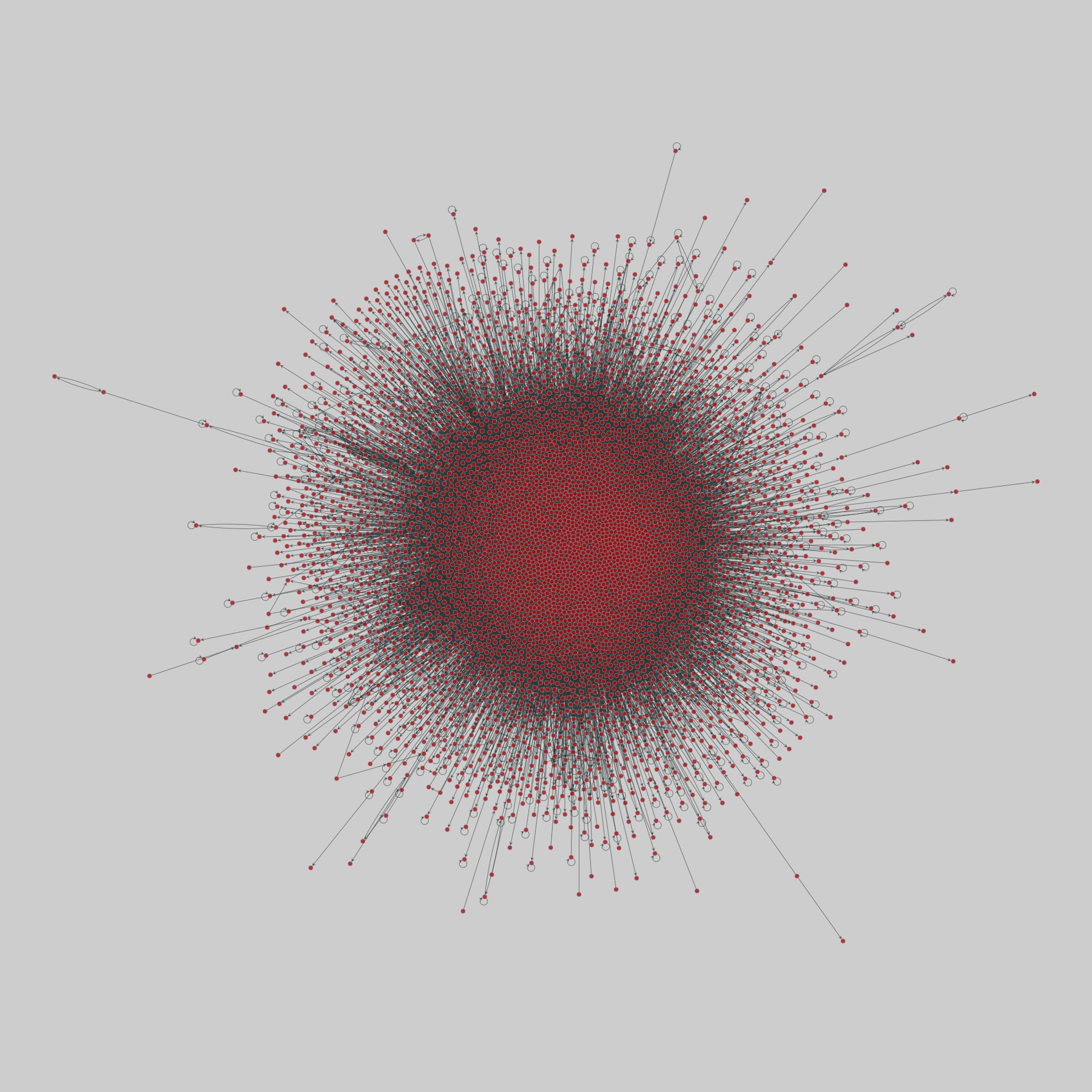
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2025-08-19 17:00:04
advogato: Advogato trust network (2009)
A network of trust relationships among users on Advogato, an online community of open source software developers. Edge direction indicates that node i trusts node j, and edge weight denotes one of four increasing levels of declared trust from i to j: observer (0.4), apprentice (0.6), journeyer (0.8), and master (1.0).
This network has 6541 nodes and 51127 edges.
Tags: Social, Online, Weighted
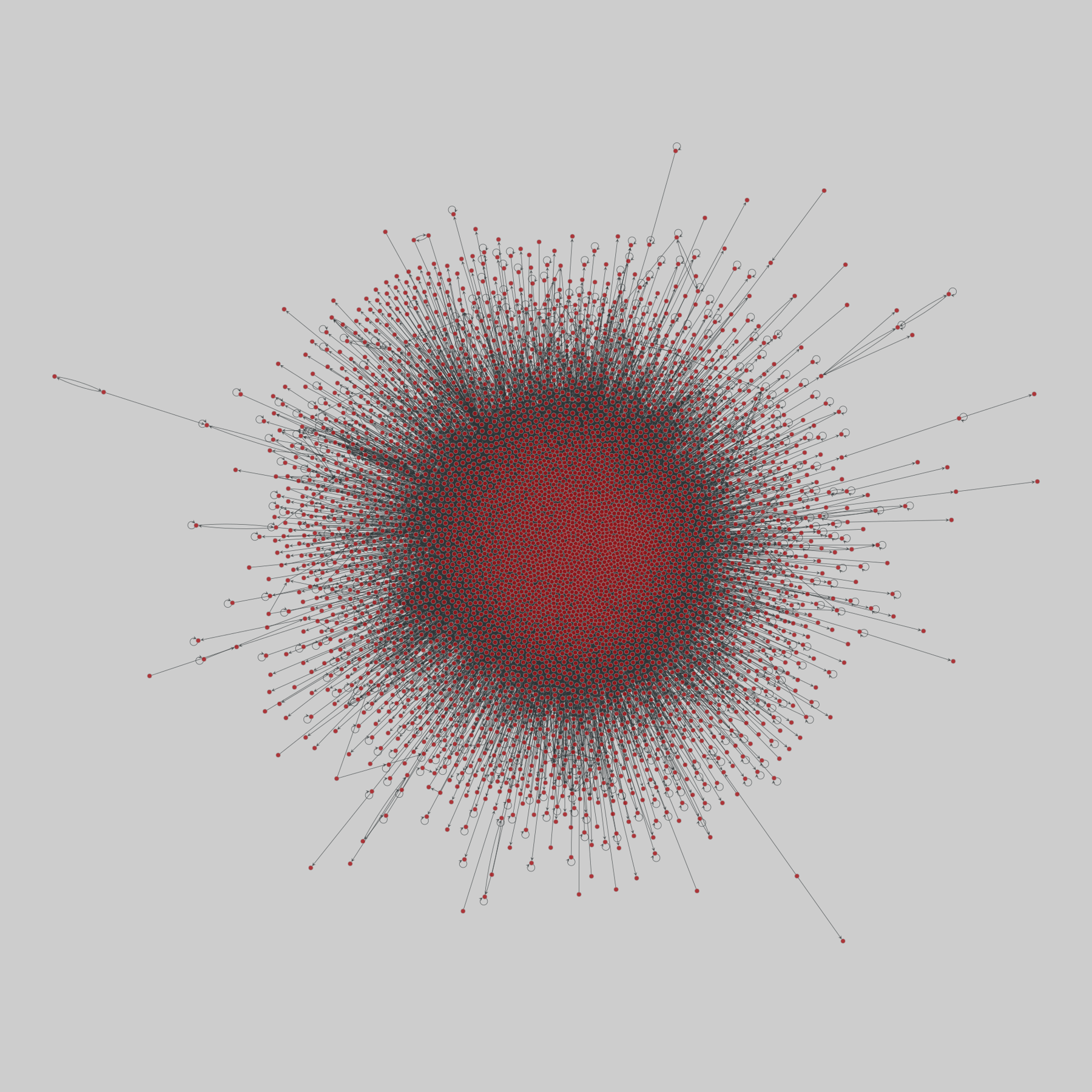 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2025-08-17 23:00:04
advogato: Advogato trust network (2009)
A network of trust relationships among users on Advogato, an online community of open source software developers. Edge direction indicates that node i trusts node j, and edge weight denotes one of four increasing levels of declared trust from i to j: observer (0.4), apprentice (0.6), journeyer (0.8), and master (1.0).
This network has 6541 nodes and 51127 edges.
Tags: Social, Online, Weighted
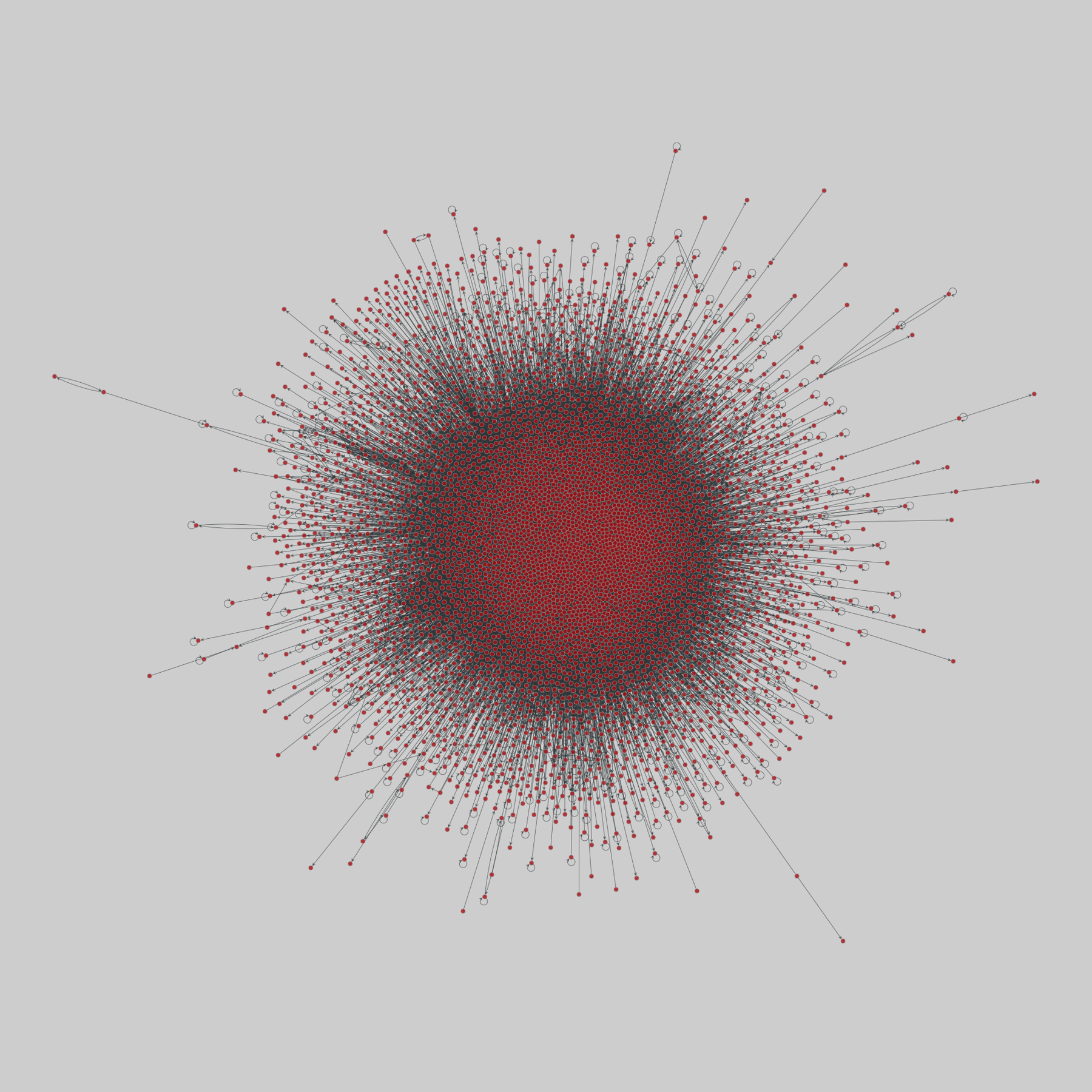 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de2025-06-19 18:00:04
advogato: Advogato trust network (2009)
A network of trust relationships among users on Advogato, an online community of open source software developers. Edge direction indicates that node i trusts node j, and edge weight denotes one of four increasing levels of declared trust from i to j: observer (0.4), apprentice (0.6), journeyer (0.8), and master (1.0).
This network has 6541 nodes and 51127 edges.
Tags: Social, Online, Weighted