 @penguin42@mastodon.org.uk
@penguin42@mastodon.org.uk2026-06-28 16:37:12
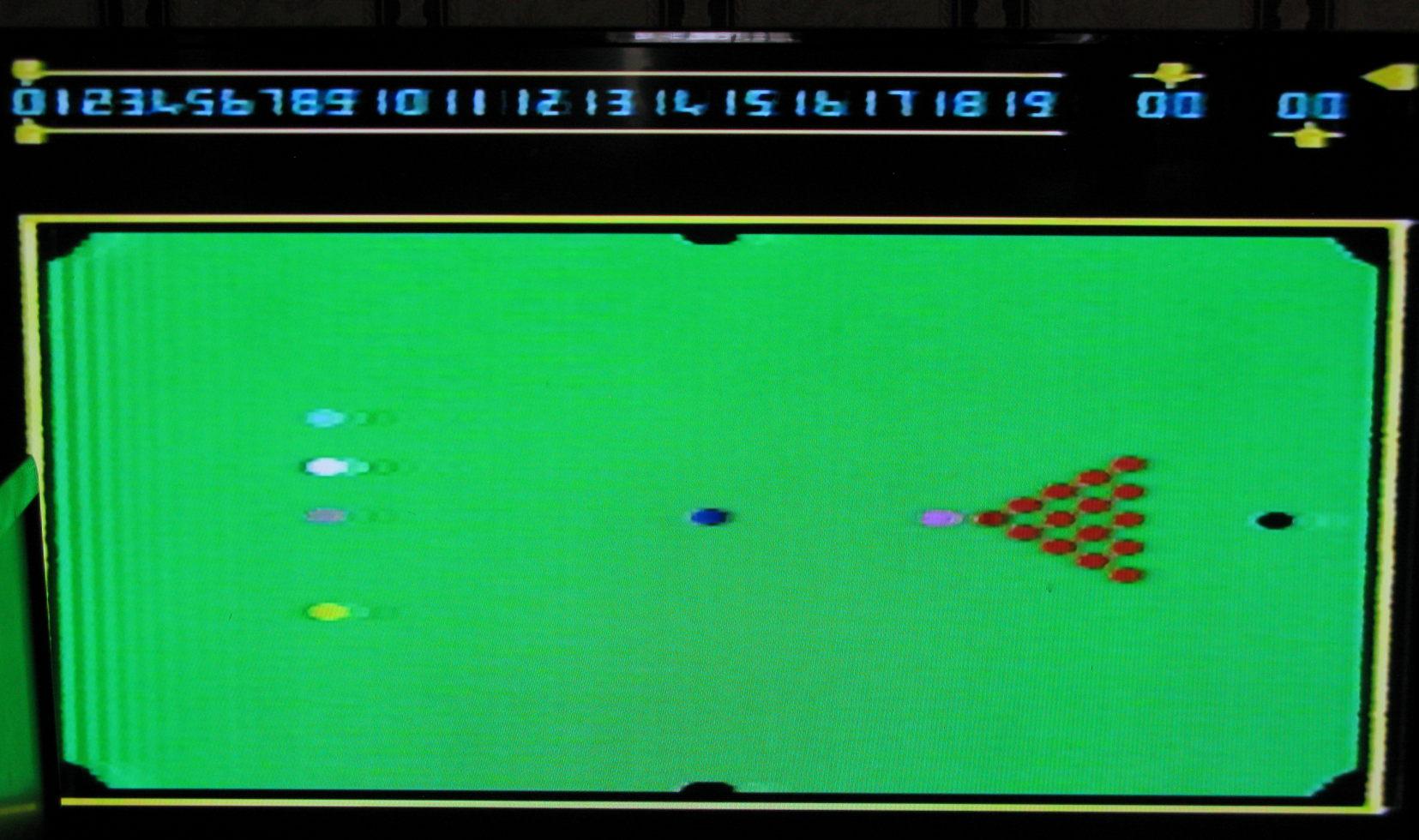
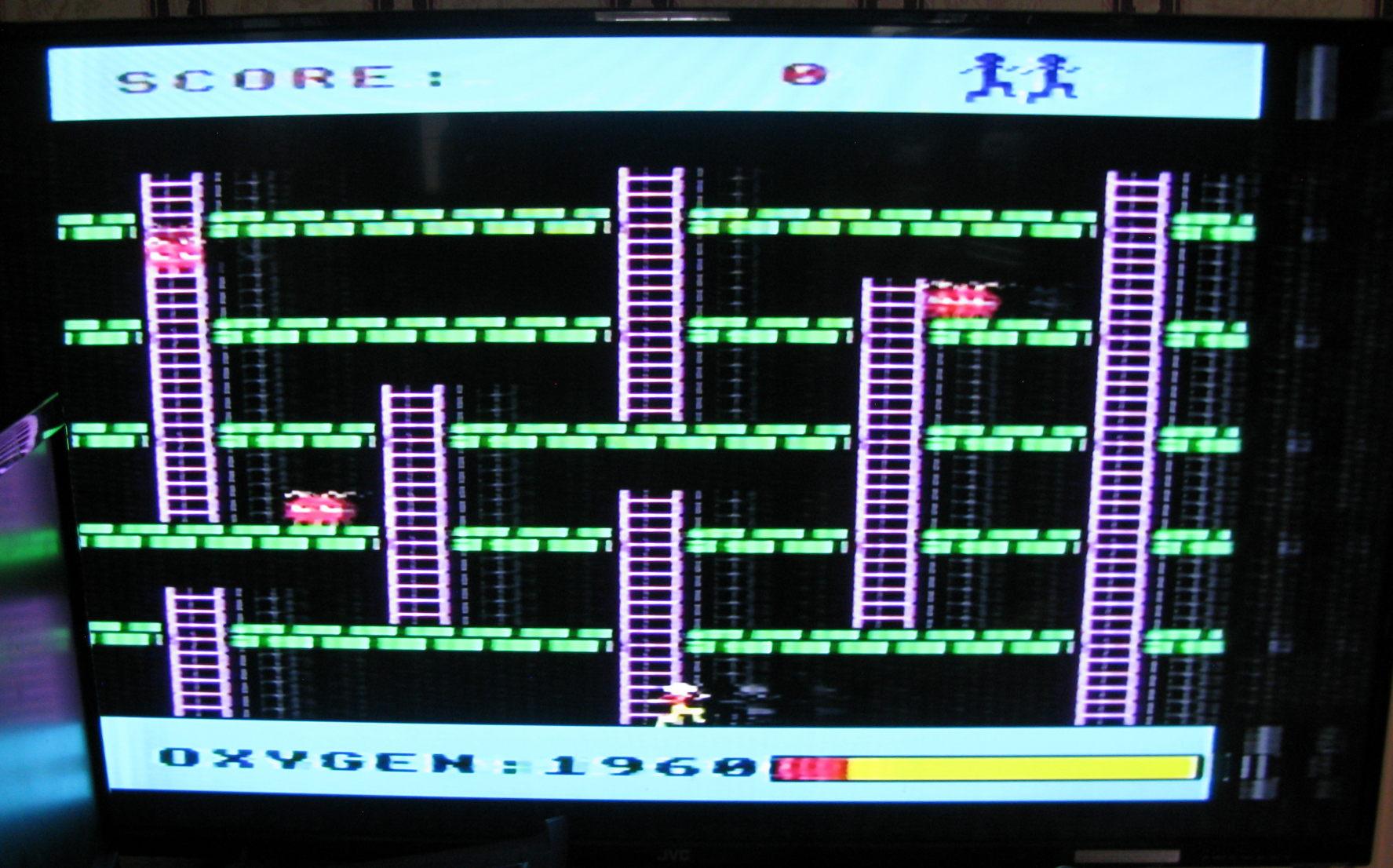
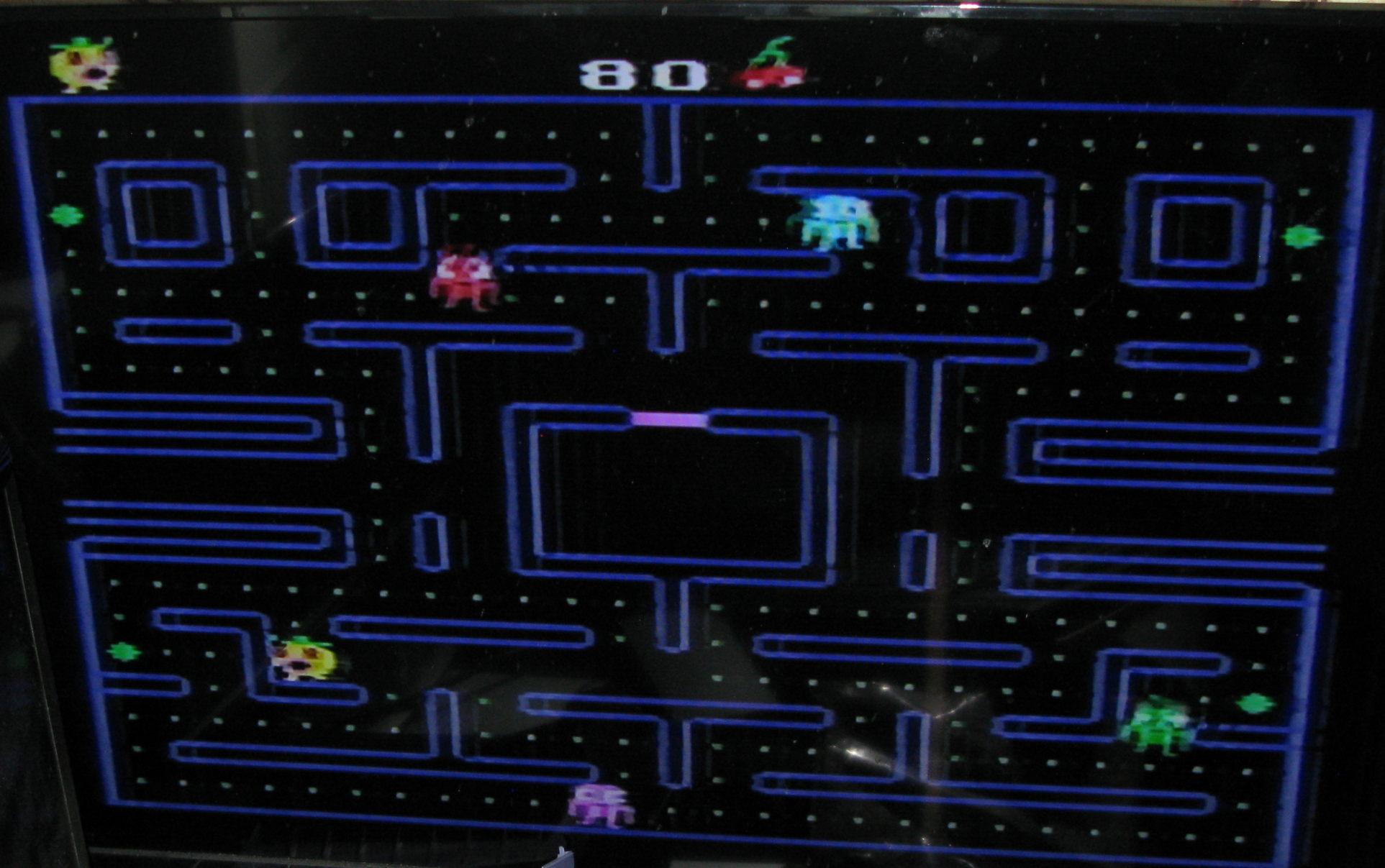
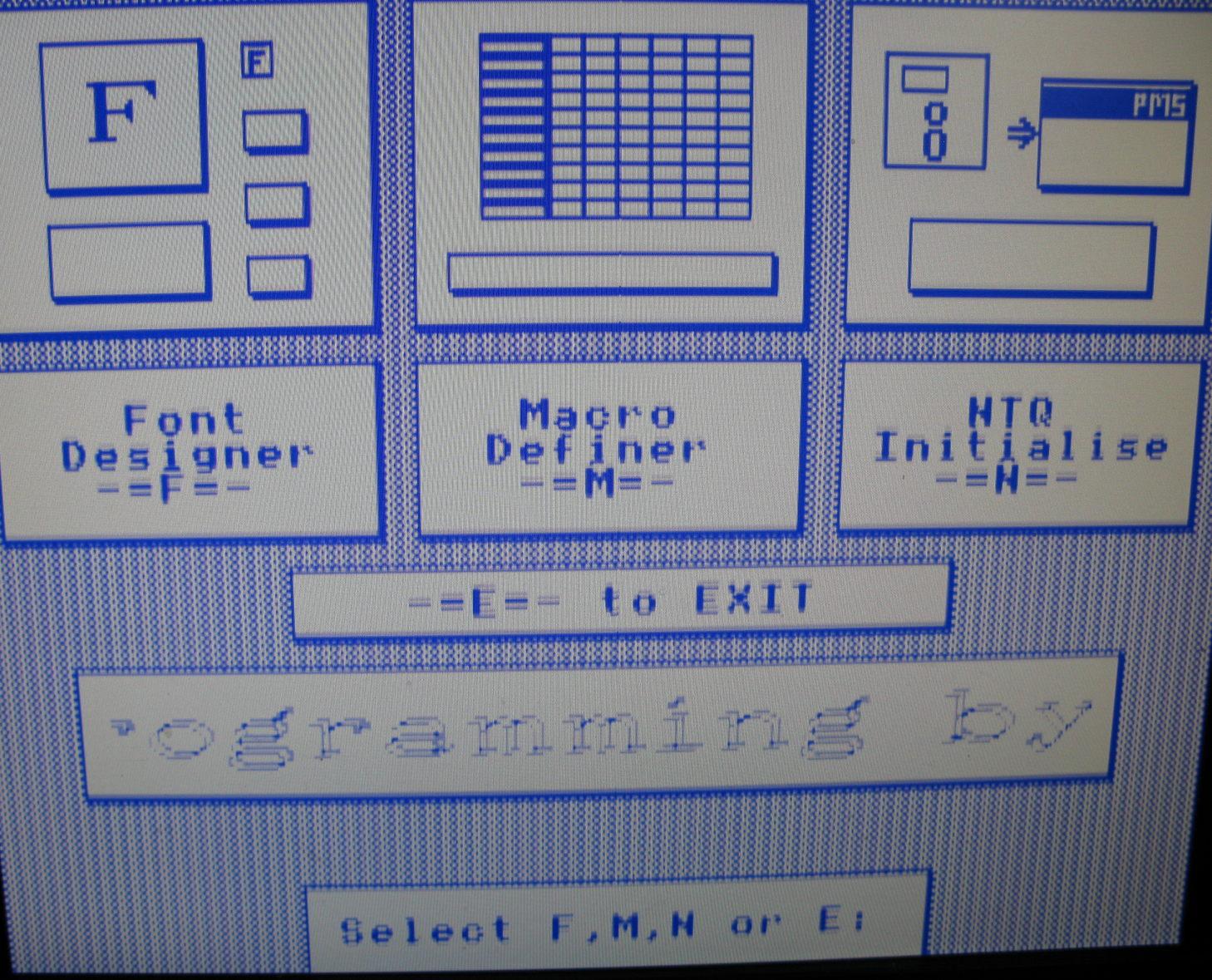
Some more BBC B screen shots - I put my beeb on a TV via UHF and os now I've got screenshots here from Acornsoft {Snooker, Monsters and Snapper}, and as a Bonus, PMS Multifont - which I think was part of a 64k external 1MHz bus RAM box; which I must look at some day.
(Was UHF always this bad but our TVs were small enough not to notice?)
(My Beeb only started some stuff after I took it's lid off - is it's got some heat problems!)
 @arXiv_csCR_bot@mastoxiv.page
@arXiv_csCR_bot@mastoxiv.page2026-07-24 07:52:20
Evaluating Large Language Models for Symbolic Security Protocol Analysis
Paolo Modesti, Syed Ahmed, Ioannis Sfyrakis, Derek Enodolomwanyi
https://arxiv.org/abs/2607.20712 https://arxiv.org/pdf/2607.20712 https://arxiv.org/html/2607.20712
arXiv:2607.20712v1 Announce Type: new
Abstract: Security protocol verification relies on formal tools such as ProVerif and OFMC. This study evaluates whether Large Language Models (LLMs) can perform comparable analysis. We test GPT and DeepSeek in chat and reasoning modes over three runs on 130 obfuscated AnB/AnBx protocols covering 388 security goals, scored against ProVerif and OFMC. Chat models reach 69 to 81% recall at precision below 31%. Reasoning models reverse this trade-off, reaching 66.5% precision for GPT and 45.4% for DeepSeek, but detect just over half the attacks. DeepSeek's two modes share one underlying model, so the comparison isolates reasoning itself, which raises precision from 27.2% to 45.4%. The GPT contrast spans a model-version change and is only suggestive. All models perform worst on authentication goals: reasoning models detect well under half of injective and non-injective agreement attacks, whereas chat models over-flag them at low precision. Confidentiality is the exception, with F1 up to 95.7% in reasoning mode. Verdicts are unstable across runs, identical on 89.7% of goals for GPT but 74.0% for DeepSeek. Self-reported confidence is uniformly high yet shows no meaningful correlation with correctness. On this benchmark LLMs do not match formal verification, but may serve, at best, as pre-screening filters.
toXiv_bot_toot