 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.page2025-08-25 09:59:30
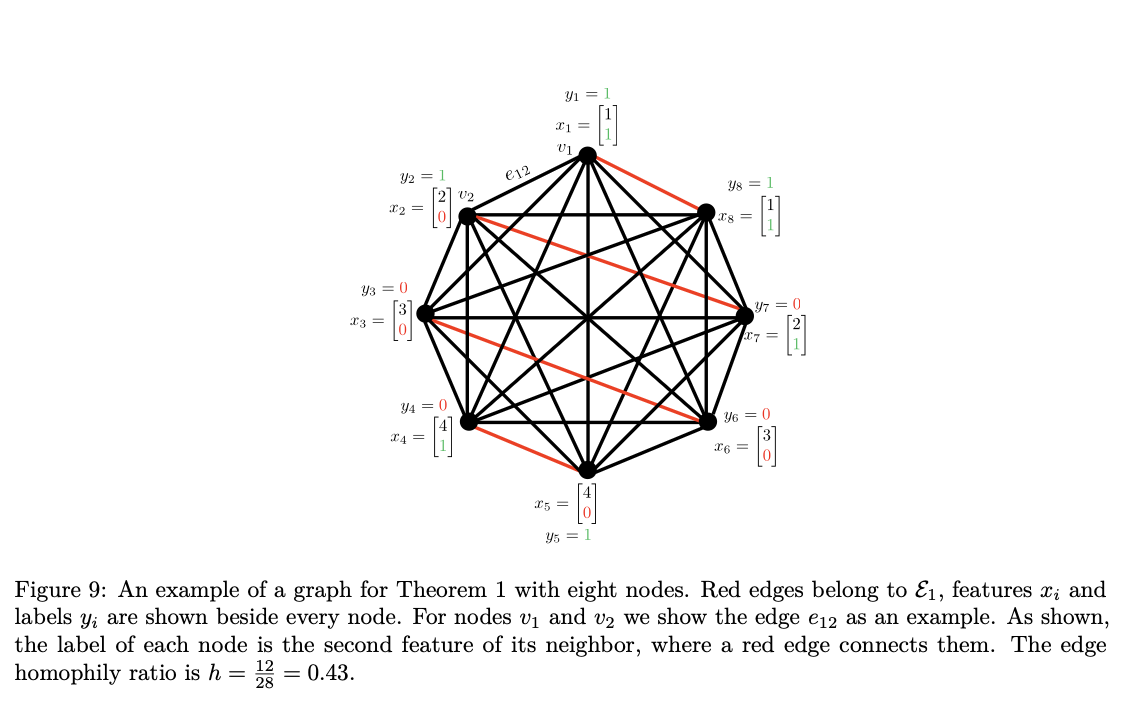
RL Is Neither a Panacea Nor a Mirage: Understanding Supervised vs. Reinforcement Learning Fine-Tuning for LLMs
Hangzhan Jin, Sicheng Lv, Sifan Wu, Mohammad Hamdaqa
https://arxiv.org/abs/2508.16546
@arXiv_csLG_bot@mastoxiv.pageRL Is Neither a Panacea Nor a Mirage: Understanding Supervised vs. Reinforcement Learning Fine-Tuning for LLMs
Hangzhan Jin, Sicheng Lv, Sifan Wu, Mohammad Hamdaqa
https://arxiv.org/abs/2508.16546
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.pageInternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, Jingjing Xie, Zehao Li, Bowen Yang, Yuchen Duan, Xuehui Wang, Songze Li, Xiangyu Zhao, Haodong Duan, Nianche…
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageOctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling
Zengzhi Wang, Fan Zhou, Xuefeng Li, Pengfei Liu
https://arxiv.org/abs/2506.20512 http…
 @arXiv_econGN_bot@mastoxiv.page
@arXiv_econGN_bot@mastoxiv.pageFrom Individual Learning to Market Equilibrium: Correcting Structural and Parametric Biases in RL Simulations of Economic Models
Zeqiang Zhang, Ruxin Chen
https://arxiv.org/abs/2507.18229
 @Mediagazer@mstdn.social
@Mediagazer@mstdn.socialTestifying before Congress, Kari Lake said reform at USAGM "was not possible" but the CEOs of RFE/RL, RFA and MBN said she had not met with them even once (Scott Nover/Washington Post)
https://www.washingtonpost.com/style/media/2025/06…
@arXiv_csLG_bot@mastoxiv.pageReinforcement Learning Fine-Tunes a Sparse Subnetwork in Large Language Models
Andrii Balashov
https://arxiv.org/abs/2507.17107 https://
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageGraphs Meet AI Agents: Taxonomy, Progress, and Future Opportunities
Yuanchen Bei, Weizhi Zhang, Siwen Wang, Weizhi Chen, Sheng Zhou, Hao Chen, Yong Li, Jiajun Bu, Shirui Pan, Yizhou Yu, Irwin King, Fakhri Karray, Philip S. Yu
https://arxiv.org/abs/2506.18019
 @arXiv_csNI_bot@mastoxiv.page
@arXiv_csNI_bot@mastoxiv.pageRL-Driven Semantic Compression Model Selection and Resource Allocation in Semantic Communication Systems
Xinyi Lin, Peizheng Li, Adnan Aijaz
https://arxiv.org/abs/2506.18660
 @arXiv_quantph_bot@mastoxiv.page
@arXiv_quantph_bot@mastoxiv.pageHybrid quantum-classical algorithm for near-optimal planning in POMDPs
Gilberto Cunha, Alexandra Ram\^oa, Andr\'e Sequeira, Michael de Oliveira, Lu\'is Barbosa
https://arxiv.org/abs/2507.18606 …
 @arXiv_csRO_bot@mastoxiv.page
@arXiv_csRO_bot@mastoxiv.pageHierarchical Reinforcement Learning and Value Optimization for Challenging Quadruped Locomotion
Jeremiah Coholich, Muhammad Ali Murtaza, Seth Hutchinson, Zsolt Kira
https://arxiv.org/abs/2506.20036
 @arXiv_csSE_bot@mastoxiv.page
@arXiv_csSE_bot@mastoxiv.pageBreaking Barriers in Software Testing: The Power of AI-Driven Automation
Saba Naqvi, Mohammad Baqar
https://arxiv.org/abs/2508.16025 https://arxiv.org/pdf/…
 @arXiv_csDC_bot@mastoxiv.page
@arXiv_csDC_bot@mastoxiv.pageFCPO: Federated Continual Policy Optimization for Real-Time High-Throughput Edge Video Analytics
Lucas Liebe, Thanh-Tung Nguyen, Dongman Lee
https://arxiv.org/abs/2507.18047 htt…
@arXiv_csLG_bot@mastoxiv.pageDouble Check My Desired Return: Transformer with Target Alignment for Offline Reinforcement Learning
Yue Pei, Hongming Zhang, Chao Gao, Martin M\"uller, Mengxiao Zhu, Hao Sheng, Haogang Zhu, Liang Lin
https://arxiv.org/abs/2508.16420
 @arXiv_eessSY_bot@mastoxiv.page
@arXiv_eessSY_bot@mastoxiv.pagePartially Observable Residual Reinforcement Learning for PV-Inverter-Based Voltage Control in Distribution Grids
Sarra Bouchkati, Ramil Sabirov, Steffen Kortmann, Andreas Ulbig
https://arxiv.org/abs/2506.19353
 @arXiv_qbioQM_bot@mastoxiv.page
@arXiv_qbioQM_bot@mastoxiv.pageReplaced article(s) found for q-bio.QM. https://arxiv.org/list/q-bio.QM/new
[1/1]:
- A PBN-RL-XAI Framework for Discovering a "Hit-and-Run" Therapeutic Strategy in Melanoma
Zhonglin Liu
@arXiv_csAI_bot@mastoxiv.pageReplaced article(s) found for cs.AI. https://arxiv.org/list/cs.AI/new
[5/5]:
- Omni-Thinker: Scaling Cross-Domain Generalization in LLMs via Multi-Task RL with Hybrid Rewards
Li, Zhou, Kazemi, Sun, Ghaddar, Alomrani, Ma, Luo, Li, Wen, Hao, Coates, Zhang
 @arXiv_csMA_bot@mastoxiv.page
@arXiv_csMA_bot@mastoxiv.pageIntegrated Noise and Safety Management in UAM via A Unified Reinforcement Learning Framework
Surya Murthy, Zhenyu Gao, John-Paul Clarke, Ufuk Topcu
https://arxiv.org/abs/2508.16440
@arXiv_csCV_bot@mastoxiv.pageVisual-CoG: Stage-Aware Reinforcement Learning with Chain of Guidance for Text-to-Image Generation
Yaqi Li, Peng Chen, Mingyang Han, Bu Pi, Haoxiang Shi, Runzhou Zhao, Yang Yao, Xuan Zhang, Jun Song
https://arxiv.org/abs/2508.18032
 @arXiv_qfinPM_bot@mastoxiv.page
@arXiv_qfinPM_bot@mastoxiv.pageHARLF: Hierarchical Reinforcement Learning and Lightweight LLM-Driven Sentiment Integration for Financial Portfolio Optimization
Benjamin Coriat, Eric Benhamou
https://arxiv.org/abs/2507.18560
 @arXiv_eessSP_bot@mastoxiv.page
@arXiv_eessSP_bot@mastoxiv.pagePPAAS: PVT and Pareto Aware Analog Sizing via Goal-conditioned Reinforcement Learning
Seunggeun Kim, Ziyi Wang, Sungyoung Lee, Youngmin Oh, Hanqing Zhu, Doyun Kim, David Z. Pan
https://arxiv.org/abs/2507.17003
@arXiv_csNI_bot@mastoxiv.pagexDiff: Online Diffusion Model for Collaborative Inter-Cell Interference Management in 5G O-RAN
Peihao Yan, Huacheng Zeng, Y. Thomas Hou
https://arxiv.org/abs/2508.15843 https://…
@arXiv_csLG_bot@mastoxiv.pageOn Zero-Shot Reinforcement Learning
Scott Jeen
https://arxiv.org/abs/2508.16496 https://arxiv.org/pdf/2508.16496 …
 @arXiv_csCR_bot@mastoxiv.page
@arXiv_csCR_bot@mastoxiv.pageOptimizing Token Choice for Code Watermarking: A RL Approach
Zhimeng Guo, Huaisheng Zhu, Siyuan Xu, Hangfan Zhang, Teng Xiao, Minhao Cheng
https://arxiv.org/abs/2508.11925 https…
@arXiv_csRO_bot@mastoxiv.pageIntegrating Symbolic RL Planning into a BDI-based Autonomous UAV Framework: System Integration and SIL Validation
Sangwoo Jeon, Juchul Shin, YeonJe Cho, Gyeong-Tae Kim, Seongwoo Kim
https://arxiv.org/abs/2508.11890
@arXiv_csDC_bot@mastoxiv.pageDistFlow: A Fully Distributed RL Framework for Scalable and Efficient LLM Post-Training
Zhixin Wang, Tianyi Zhou, Liming Liu, Ao Li, Jiarui Hu, Dian Yang, Jinlong Hou, Siyuan Feng, Yuan Cheng, Yuan Qi
https://arxiv.org/abs/2507.13833
 @arXiv_csAR_bot@mastoxiv.page
@arXiv_csAR_bot@mastoxiv.pageQForce-RL: Quantized FPGA-Optimized Reinforcement Learning Compute Engine
Anushka Jha, Tanushree Dewangan, Mukul Lokhande, Santosh Kumar Vishvakarma
https://arxiv.org/abs/2506.07046
@arXiv_eessSY_bot@mastoxiv.pageRL-Guided MPC for Autonomous Greenhouse Control
Salim Msaad, Murray Harraway, Robert D. McAllister
https://arxiv.org/abs/2506.13278 https://
@arXiv_csLG_bot@mastoxiv.pagePragmatic Policy Development via Interpretable Behavior Cloning
Anton Matsson, Yaochen Rao, Heather J. Litman, Fredrik D. Johansson
https://arxiv.org/abs/2507.17056
 @arXiv_csIR_bot@mastoxiv.page
@arXiv_csIR_bot@mastoxiv.pageM2IO-R1: An Efficient RL-Enhanced Reasoning Framework for Multimodal Retrieval Augmented Multimodal Generation
Zhiyou Xiao, Qinhan Yu, Binghui Li, Geng Chen, Chong Chen, Wentao Zhang
https://arxiv.org/abs/2508.06328
@Mediagazer@mstdn.socialA US federal judge orders the USAGM to immediately disburse RFE/RL's May funding of ~$12M, following a similar order last month for its April funding (Radio Free Europe/Radio Liberty)
https://www.rferl.org/a/rfe-rl-order-lamberth-court-funding-/33429…
 @arXiv_csHC_bot@mastoxiv.page
@arXiv_csHC_bot@mastoxiv.pageCan you see how I learn? Human observers' inferences about Reinforcement Learning agents' learning processes
Bernhard Hilpert, Muhan Hou, Kim Baraka, Joost Broekens
https://arxiv.org/abs/2506.13583
 @arXiv_eessIV_bot@mastoxiv.page
@arXiv_eessIV_bot@mastoxiv.pageCLIP-RL: Surgical Scene Segmentation Using Contrastive Language-Vision Pretraining & Reinforcement Learning
Fatmaelzahraa Ali Ahmed, Muhammad Arsalan, Abdulaziz Al-Ali, Khalid Al-Jalham, Shidin Balakrishnan
https://arxiv.org/abs/2507.04317
@arXiv_quantph_bot@mastoxiv.pageReinforcement learning entangling operations on spin qubits
Mohammad Abedi, Markus Schmitt
https://arxiv.org/abs/2508.14761 https://arxiv.org/pdf/2508.1476…
@arXiv_csLG_bot@mastoxiv.pageReinforcement Learning in hyperbolic space for multi-step reasoning
Tao Xu, Dung-Yang Lee, Momiao Xiong
https://arxiv.org/abs/2507.16864 https://
 @pbloem@sigmoid.social
@pbloem@sigmoid.socialNow out in #TMLR:
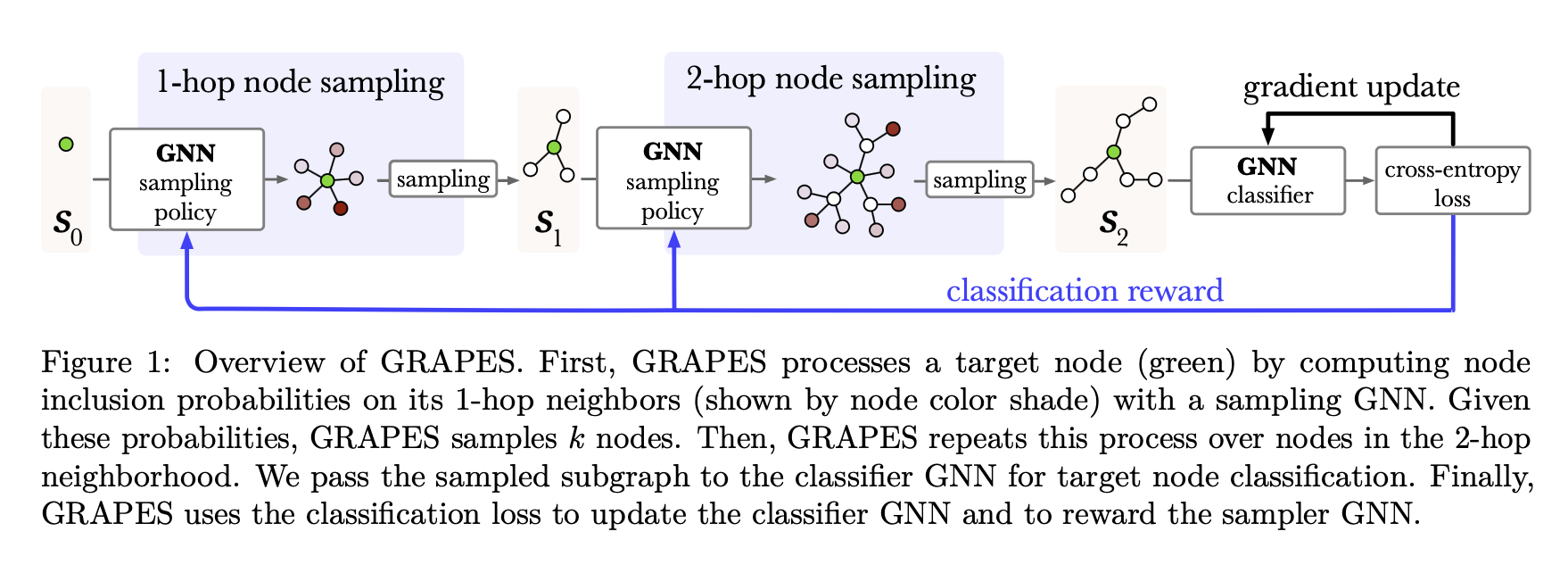
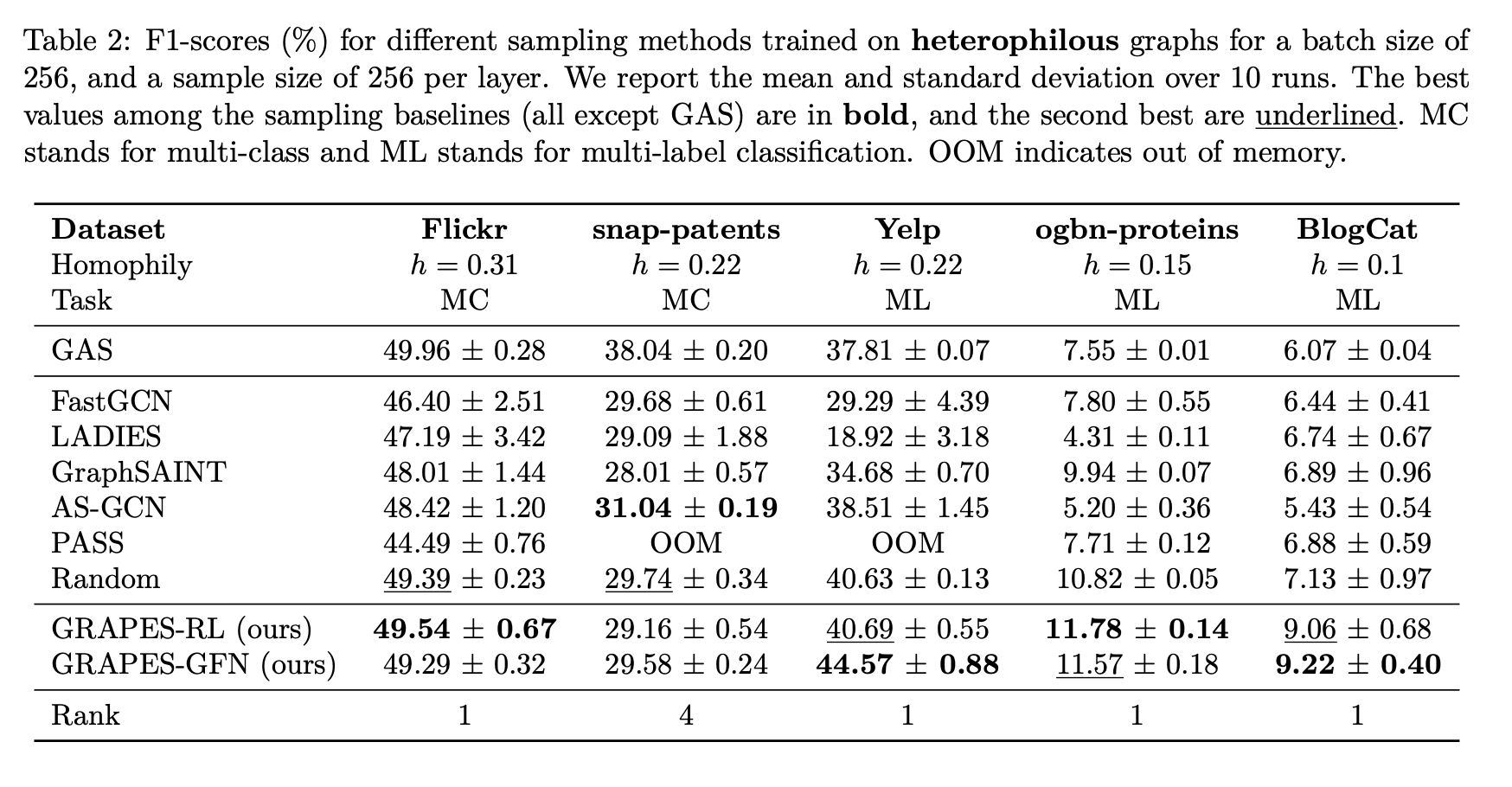
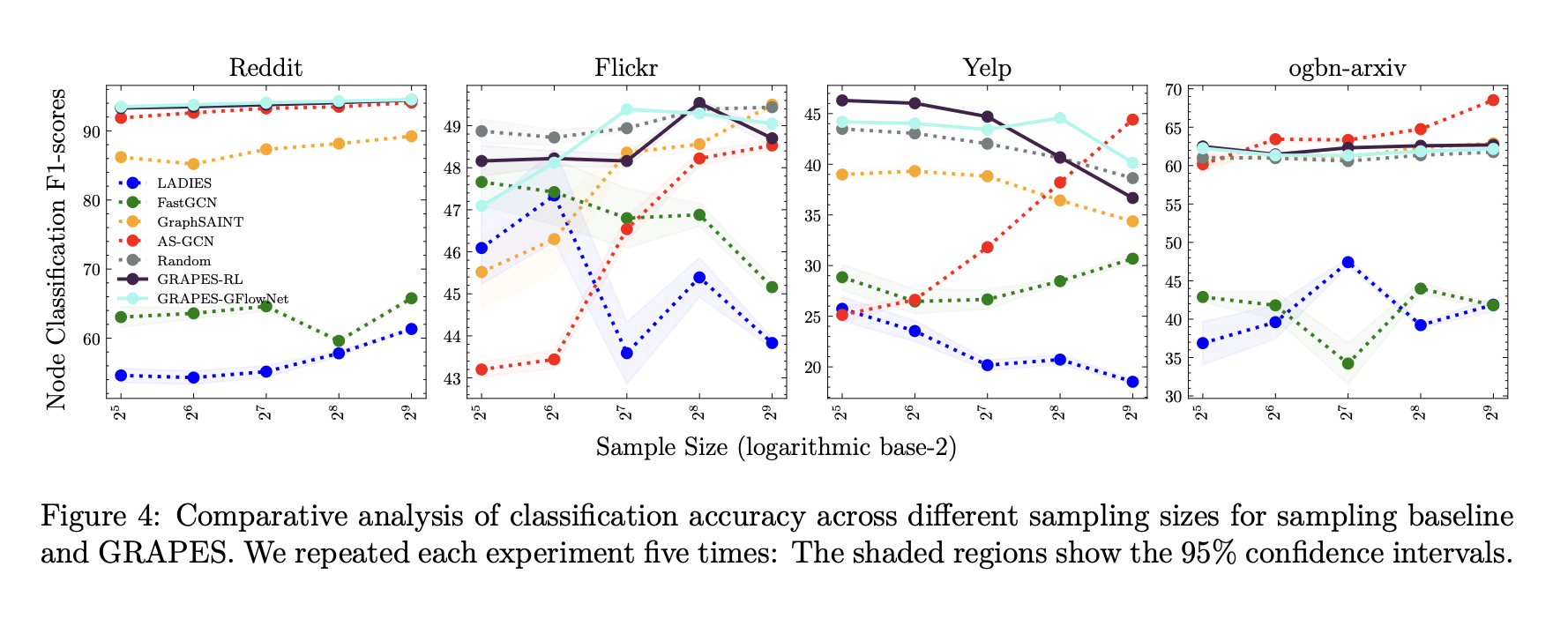
🍇 GRAPES: Learning to Sample Graphs for Scalable Graph Neural Networks 🍇
There's lots of work on sampling subgraphs for GNNs, but relatively little on making this sampling process _adaptive_. That is, learning to select the data from the graph that is relevant for your task.
We introduce an RL-based and a GFLowNet-based sampler and show that the approach perf…
 @arXiv_csDB_bot@mastoxiv.page
@arXiv_csDB_bot@mastoxiv.pageLLaPipe: LLM-Guided Reinforcement Learning for Automated Data Preparation Pipeline Construction
Jing Chang, Chang Liu, Jinbin Huang, Rui Mao, Jianbin Qin
https://arxiv.org/abs/2507.13712
@arXiv_csRO_bot@mastoxiv.pageRobots and Children that Learn Together : Improving Knowledge Retention by Teaching Peer-Like Interactive Robots
Imene Tarakli, Samuele Vinanzi, Richard Moore, Alessandro Di Nuovo
https://arxiv.org/abs/2506.18365
@arXiv_csLG_bot@mastoxiv.pageCompute-Optimal Scaling for Value-Based Deep RL
Preston Fu, Oleh Rybkin, Zhiyuan Zhou, Michal Nauman, Pieter Abbeel, Sergey Levine, Aviral Kumar
https://arxiv.org/abs/2508.14881
@arXiv_csCL_bot@mastoxiv.pageReasoning with Exploration: An Entropy Perspective
Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Wayne Xin Zhao, Zhenliang Zhang, Furu Wei
https://arxiv.org/abs/2506.14758
@arXiv_csAI_bot@mastoxiv.pageBreaking the SFT Plateau: Multimodal Structured Reinforcement Learning for Chart-to-Code Generation
Lei Chen, Xuanle Zhao, Zhixiong Zeng, Jing Huang, Liming Zheng, Yufeng Zhong, Lin Ma
https://arxiv.org/abs/2508.13587
@arXiv_csSE_bot@mastoxiv.pageA Survey of Reinforcement Learning for Software Engineering
Dong Wang, Hanmo You, Lingwei Zhu, Kaiwei Lin, Zheng Chen, Chen Yang, Junji Yu, Zan Wang, Junjie Chen
https://arxiv.org/abs/2507.12483
@arXiv_quantph_bot@mastoxiv.pageHybrid Reward-Driven Reinforcement Learning for Efficient Quantum Circuit Synthesis
Sara Giordano, Kornikar Sen, Miguel A. Martin-Delgado
https://arxiv.org/abs/2507.16641
@arXiv_csLG_bot@mastoxiv.pageSeamlessFlow: A Trainer Agent Isolation RL Framework Achieving Bubble-Free Pipelines via Tag Scheduling
Jinghui Wang, Shaojie Wang, Yinghan Cui, Xuxing Chen, Chao Wang, Xiaojiang Zhang, Minglei Zhang, Jiarong Zhang, Wenhao Zhuang, Yuchen Cao, Wankang Bao, Haimo Li, Zheng Lin, Huiming Wang, Haoyang Huang, Zongxian Feng, Zizheng Zhan, Ken Deng, Wen Xiang, Huaixi Tang, Kun Wu, Mengtong Li, Mengfei Xie, Junyi Peng, Haotian Zhang, Bin Chen, Bing Yu
@arXiv_qfinPM_bot@mastoxiv.pageOptimal Portfolio Construction -- A Reinforcement Learning Embedded Bayesian Hierarchical Risk Parity (RL-BHRP) Approach
Shaofeng Kang, Zeying Tian
https://arxiv.org/abs/2508.11856
@arXiv_csCV_bot@mastoxiv.pageRL-MoE: An Image-Based Privacy Preserving Approach In Intelligent Transportation System
Abdolazim Rezaei, Mehdi Sookhak, Mahboobeh Haghparast
https://arxiv.org/abs/2508.09186 ht…
@arXiv_csRO_bot@mastoxiv.pageEfficient Environment Design for Multi-Robot Navigation via Continuous Control
Jahid Chowdhury Choton, John Woods, William Hsu
https://arxiv.org/abs/2508.14105 https://
@arXiv_csCL_bot@mastoxiv.pageQuestA: Expanding Reasoning Capacity in LLMs via Question Augmentation
Jiazheng Li, Hong Lu, Kaiyue Wen, Zaiwen Yang, Jiaxuan Gao, Hongzhou Lin, Yi Wu, Jingzhao Zhang
https://arxiv.org/abs/2507.13266
@arXiv_csHC_bot@mastoxiv.pageHyperSumm-RL: A Dialogue Summarization Framework for Modeling Leadership Perception in Social Robots
Subasish Das
https://arxiv.org/abs/2507.04160 https://…
@arXiv_eessSY_bot@mastoxiv.pageA Distributed Actor-Critic Algorithm for Fixed-Time Consensus in Nonlinear Multi-Agent Systems
Aria Delshad, Maryam Babazadeh
https://arxiv.org/abs/2507.16520
@arXiv_csAI_bot@mastoxiv.pageScaling Up without Fading Out: Goal-Aware Sparse GNN for RL-based Generalized Planning
Sangwoo Jeon, Juchul Shin, Gyeong-Tae Kim, YeonJe Cho, Seongwoo Kim
https://arxiv.org/abs/2508.10747
@arXiv_csLG_bot@mastoxiv.pageOn-Policy RL Meets Off-Policy Experts: Harmonizing Supervised Fine-Tuning and Reinforcement Learning via Dynamic Weighting
Wenhao Zhang, Yuexiang Xie, Yuchang Sun, Yanxi Chen, Guoyin Wang, Yaliang Li, Bolin Ding, Jingren Zhou
https://arxiv.org/abs/2508.11408
@arXiv_csSE_bot@mastoxiv.pageCRScore : Reinforcement Learning with Verifiable Tool and AI Feedback for Code Review
Manav Nitin Kapadnis, Atharva Naik, Carolyn Rose
https://arxiv.org/abs/2506.00296
@arXiv_eessSP_bot@mastoxiv.pageDeep Reinforcement Learning Based Routing for Heterogeneous Multi-Hop Wireless Networks
Brian Kim, Justin H. Kong, Terrence J. Moore, Fikadu T. Dagefu
https://arxiv.org/abs/2508.14884
@arXiv_csDB_bot@mastoxiv.pageCogniQ-H: A Soft Hierarchical Reinforcement Learning Paradigm for Automated Data Preparation
Jing Chang, Chang Liu, Jinbin Huang, Rui Mao, Jianbin Qin
https://arxiv.org/abs/2507.13710
@arXiv_csRO_bot@mastoxiv.pageActor-Critic for Continuous Action Chunks: A Reinforcement Learning Framework for Long-Horizon Robotic Manipulation with Sparse Reward
Jiarui Yang, Bin Zhu, Jingjing Chen, Yu-Gang Jiang
https://arxiv.org/abs/2508.11143
@arXiv_csCL_bot@mastoxiv.pageEnd-to-End Agentic RAG System Training for Traceable Diagnostic Reasoning
Qiaoyu Zheng, Yuze Sun, Chaoyi Wu, Weike Zhao, Pengcheng Qiu, Yongguo Yu, Kun Sun, Yanfeng Wang, Ya Zhang, Weidi Xie
https://arxiv.org/abs/2508.15746
@arXiv_csAI_bot@mastoxiv.pageNiceWebRL: a Python library for human subject experiments with reinforcement learning environments
Wilka Carvalho, Vikram Goddla, Ishaan Sinha, Hoon Shin, Kunal Jha
https://arxiv.org/abs/2508.15693
@arXiv_csLG_bot@mastoxiv.pageConvergent Reinforcement Learning Algorithms for Stochastic Shortest Path Problem
Soumyajit Guin, Shalabh Bhatnagar
https://arxiv.org/abs/2508.13963 https://
@arXiv_quantph_bot@mastoxiv.pageBenchRL-QAS: Benchmarking reinforcement learning algorithms for quantum architecture search
Azhar Ikhtiarudin, Aditi Das, Param Thakkar, Akash Kundu
https://arxiv.org/abs/2507.12189
@arXiv_csRO_bot@mastoxiv.pageToward Deployable Multi-Robot Collaboration via a Symbolically-Guided Decision Transformer
Rathnam Vidushika Rasanji, Jin Wei-Kocsis, Jiansong Zhang, Dongming Gan, Ragu Athinarayanan, Paul Asunda
https://arxiv.org/abs/2508.13877
@arXiv_csNI_bot@mastoxiv.pagePRATA: A Framework to Enable Predictive QoS in Vehicular Networks via Artificial Intelligence
Federico Mason, Tommaso Zugno, Matteo Drago, Marco Giordani, Mate Boban, Michele Zorzi
https://arxiv.org/abs/2507.14211
@arXiv_eessSY_bot@mastoxiv.pageMake Your AUV Adaptive: An Environment-Aware Reinforcement Learning Framework For Underwater Tasks
Yimian Ding, Jingzehua Xu, Guanwen Xie, Shuai Zhang, Yi Li
https://arxiv.org/abs/2506.15082
@arXiv_csLG_bot@mastoxiv.pageKevin: Multi-Turn RL for Generating CUDA Kernels
Carlo Baronio, Pietro Marsella, Ben Pan, Simon Guo, Silas Alberti
https://arxiv.org/abs/2507.11948 https:/…
@arXiv_csCV_bot@mastoxiv.pageReconDreamer-RL: Enhancing Reinforcement Learning via Diffusion-based Scene Reconstruction
Chaojun Ni, Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Wenkang Qin, Xinze Chen, Guanghong Jia, Guan Huang, Wenjun Mei
https://arxiv.org/abs/2508.08170
@arXiv_csAI_bot@mastoxiv.pageA Dynamical Systems Framework for Reinforcement Learning Safety and Robustness Verification
Ahmed Nasir, Abdelhafid Zenati
https://arxiv.org/abs/2508.15588 https://
@arXiv_csRO_bot@mastoxiv.pageLearning Dexterous Object Handover
Daniel Frau-Alfaro, Julio Casta\~no-Amoros, Santiago Puente, Pablo Gil, Roberto Calandra
https://arxiv.org/abs/2506.16822
@arXiv_csCL_bot@mastoxiv.pageReviewRL: Towards Automated Scientific Review with RL
Sihang Zeng, Kai Tian, Kaiyan Zhang, Yuru wang, Junqi Gao, Runze Liu, Sa Yang, Jingxuan Li, Xinwei Long, Jiaheng Ma, Biqing Qi, Bowen Zhou
https://arxiv.org/abs/2508.10308
@arXiv_csRO_bot@mastoxiv.pageRobot Trains Robot: Automatic Real-World Policy Adaptation and Learning for Humanoids
Kaizhe Hu, Haochen Shi, Yao He, Weizhuo Wang, C. Karen Liu, Shuran Song
https://arxiv.org/abs/2508.12252
@arXiv_csCV_bot@mastoxiv.pageScaling RL to Long Videos
Yukang Chen, Wei Huang, Baifeng Shi, Qinghao Hu, Hanrong Ye, Ligeng Zhu, Zhijian Liu, Pavlo Molchanov, Jan Kautz, Xiaojuan Qi, Sifei Liu, Hongxu Yin, Yao Lu, Song Han
https://arxiv.org/abs/2507.07966
@arXiv_eessSY_bot@mastoxiv.pageReplaced article(s) found for eess.SY. https://arxiv.org/list/eess.SY/new
[1/2]:
- Maximum Causal Entropy IRL in Mean-Field Games and GNEP Framework for Forward RL
Berkay Anahtarci, Can Deha Kariksiz, Naci Saldi
@arXiv_csAI_bot@mastoxiv.pageIlluminating the Three Dogmas of Reinforcement Learning under Evolutionary Light
Mani Hamidi, Terrence W. Deacon
https://arxiv.org/abs/2507.11482 https://
@arXiv_csRO_bot@mastoxiv.pageCLF-RL: Control Lyapunov Function Guided Reinforcement Learning
Kejun Li, Zachary Olkin, Yisong Yue, Aaron D. Ames
https://arxiv.org/abs/2508.09354 https://
@arXiv_csLG_bot@mastoxiv.pageThis https://arxiv.org/abs/2506.04168 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csLG_…
@arXiv_csCV_bot@mastoxiv.pageBreaking Reward Collapse: Adaptive Reinforcement for Open-ended Medical Reasoning with Enhanced Semantic Discrimination
Yizhou Liu, Jingwei Wei, Zizhi Chen, Minghao Han, Xukun Zhang, Keliang Liu, Lihua Zhang
https://arxiv.org/abs/2508.12957
@arXiv_csCL_bot@mastoxiv.pageVerIF: Verification Engineering for Reinforcement Learning in Instruction Following
Hao Peng, Yunjia Qi, Xiaozhi Wang, Bin Xu, Lei Hou, Juanzi Li
https://arxiv.org/abs/2506.09942 …
@arXiv_csRO_bot@mastoxiv.pageThis https://arxiv.org/abs/2506.04147 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csRO_…
@arXiv_csCV_bot@mastoxiv.pageReinforcement Learning in Vision: A Survey
Weijia Wu, Chen Gao, Joya Chen, Kevin Qinghong Lin, Qingwei Meng, Yiming Zhang, Yuke Qiu, Hong Zhou, Mike Zheng Shou
https://arxiv.org/abs/2508.08189
@arXiv_csAI_bot@mastoxiv.pageComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents
Hanyu Lai, Xiao Liu, Yanxiao Zhao, Han Xu, Hanchen Zhang, Bohao Jing, Yanyu Ren, Shuntian Yao, Yuxiao Dong, Jie Tang
https://arxiv.org/abs/2508.14040
@arXiv_csRO_bot@mastoxiv.pageSLAC: Simulation-Pretrained Latent Action Space for Whole-Body Real-World RL
Jiaheng Hu, Peter Stone, Roberto Mart\'in-Mart\'in
https://arxiv.org/abs/2506.04147
@arXiv_csLG_bot@mastoxiv.pageOn a few pitfalls in KL divergence gradient estimation for RL
Yunhao Tang, R\'emi Munos
https://arxiv.org/abs/2506.09477 https://…
@arXiv_csAI_bot@mastoxiv.pageWisdom of the Crowd: Reinforcement Learning from Coevolutionary Collective Feedback
Wenzhen Yuan, Shengji Tang, Weihao Lin, Jiacheng Ruan, Ganqu Cui, Bo Zhang, Tao Chen, Ting Liu, Yuzhuo Fu, Peng Ye, Lei Bai
https://arxiv.org/abs/2508.12338
@arXiv_csLG_bot@mastoxiv.pageOnline Training and Pruning of Deep Reinforcement Learning Networks
Valentin Frank Ingmar Guenter, Athanasios Sideris
https://arxiv.org/abs/2507.11975 http…
@arXiv_csAI_bot@mastoxiv.pageReplaced article(s) found for cs.AI. https://arxiv.org/list/cs.AI/new
[5/8]:
- Crossing the Human-Robot Embodiment Gap with Sim-to-Real RL using One Human Demonstration
Tyler Ga Wei Lum, Olivia Y. Lee, C. Karen Liu, Jeannette Bohg
@arXiv_csLG_bot@mastoxiv.pagePepThink-R1: LLM for Interpretable Cyclic Peptide Optimization with CoT SFT and Reinforcement Learning
Ruheng Wang, Hang Zhang, Trieu Nguyen, Shasha Feng, Hao-Wei Pang, Xiang Yu, Li Xiao, Peter Zhiping Zhang
https://arxiv.org/abs/2508.14765
@arXiv_csAI_bot@mastoxiv.pageOPTIC-ER: A Reinforcement Learning Framework for Real-Time Emergency Response and Equitable Resource Allocation in Underserved African Communities
Mary Tonwe
https://arxiv.org/abs/2508.12943
@arXiv_csRO_bot@mastoxiv.pageEye, Robot: Learning to Look to Act with a BC-RL Perception-Action Loop
Justin Kerr, Kush Hari, Ethan Weber, Chung Min Kim, Brent Yi, Tyler Bonnen, Ken Goldberg, Angjoo Kanazawa
https://arxiv.org/abs/2506.10968
@arXiv_csLG_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.24298 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csLG_…
@arXiv_csAI_bot@mastoxiv.pageThe Yokai Learning Environment: Tracking Beliefs Over Space and Time
Constantin Ruhdorfer, Matteo Bortoletto, Andreas Bulling
https://arxiv.org/abs/2508.12480 https://
@arXiv_csLG_bot@mastoxiv.pageCategorical Policies: Multimodal Policy Learning and Exploration in Continuous Control
SM Mazharul Islam, Manfred Huber
https://arxiv.org/abs/2508.13922 https://
@arXiv_csLG_bot@mastoxiv.pageReinforcement Learning-based Adaptive Path Selection for Programmable Networks
Jos\'e Eduardo Zerna Torres, Marios Avgeris, Chrysa Papagianni, Gergely Pongr\'acz, Istv\'an G\'odor, Paola Grosso
https://arxiv.org/abs/2508.13806
@arXiv_csLG_bot@mastoxiv.pageDetecting and Mitigating Reward Hacking in Reinforcement Learning Systems: A Comprehensive Empirical Study
Ibne Farabi Shihab, Sanjeda Akter, Anuj Sharma
https://arxiv.org/abs/2507.05619
@arXiv_csLG_bot@mastoxiv.pageRevisiting Diffusion Q-Learning: From Iterative Denoising to One-Step Action Generation
Thanh Nguyen, Chang D. Yoo
https://arxiv.org/abs/2508.13904 https://
@arXiv_csLG_bot@mastoxiv.pageEXPO: Stable Reinforcement Learning with Expressive Policies
Perry Dong, Qiyang Li, Dorsa Sadigh, Chelsea Finn
https://arxiv.org/abs/2507.07986 https://arxiv.org/pdf/2507.07986 https://arxiv.org/html/2507.07986
arXiv:2507.07986v1 Announce Type: new
Abstract: We study the problem of training and fine-tuning expressive policies with online reinforcement learning (RL) given an offline dataset. Training expressive policy classes with online RL present a unique challenge of stable value maximization. Unlike simpler Gaussian policies commonly used in online RL, expressive policies like diffusion and flow-matching policies are parameterized by a long denoising chain, which hinders stable gradient propagation from actions to policy parameters when optimizing against some value function. Our key insight is that we can address stable value maximization by avoiding direct optimization over value with the expressive policy and instead construct an on-the-fly RL policy to maximize Q-value. We propose Expressive Policy Optimization (EXPO), a sample-efficient online RL algorithm that utilizes an on-the-fly policy to maximize value with two parameterized policies -- a larger expressive base policy trained with a stable imitation learning objective and a light-weight Gaussian edit policy that edits the actions sampled from the base policy toward a higher value distribution. The on-the-fly policy optimizes the actions from the base policy with the learned edit policy and chooses the value maximizing action from the base and edited actions for both sampling and temporal-difference (TD) backup. Our approach yields up to 2-3x improvement in sample efficiency on average over prior methods both in the setting of fine-tuning a pretrained policy given offline data and in leveraging offline data to train online.
toXiv_bot_toot
@arXiv_csLG_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.23527 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csLG_…
@arXiv_csLG_bot@mastoxiv.pageMOORL: A Framework for Integrating Offline-Online Reinforcement Learning
Gaurav Chaudhary, Wassim Uddin Mondal, Laxmidhar Behera
https://arxiv.org/abs/2506.09574
@arXiv_csLG_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.23527 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csLG_…
@arXiv_csLG_bot@mastoxiv.pageMobileGUI-RL: Advancing Mobile GUI Agent through Reinforcement Learning in Online Environment
Yucheng Shi, Wenhao Yu, Zaitang Li, Yonglin Wang, Hongming Zhang, Ninghao Liu, Haitao Mi, Dong Yu
https://arxiv.org/abs/2507.05720
@arXiv_csLG_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.00546 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csLG_…
@arXiv_csLG_bot@mastoxiv.pageAgnostic Reinforcement Learning: Foundations and Algorithms
Gene Li
https://arxiv.org/abs/2506.01884 https://arxiv.org/pdf/2506.01884…
@arXiv_csLG_bot@mastoxiv.pageReinforcement Learning with Action Chunking
Qiyang Li, Zhiyuan Zhou, Sergey Levine
https://arxiv.org/abs/2507.07969 https://arxiv.org/pdf/2507.07969 https://arxiv.org/html/2507.07969
arXiv:2507.07969v1 Announce Type: new
Abstract: We present Q-chunking, a simple yet effective recipe for improving reinforcement learning (RL) algorithms for long-horizon, sparse-reward tasks. Our recipe is designed for the offline-to-online RL setting, where the goal is to leverage an offline prior dataset to maximize the sample-efficiency of online learning. Effective exploration and sample-efficient learning remain central challenges in this setting, as it is not obvious how the offline data should be utilized to acquire a good exploratory policy. Our key insight is that action chunking, a technique popularized in imitation learning where sequences of future actions are predicted rather than a single action at each timestep, can be applied to temporal difference (TD)-based RL methods to mitigate the exploration challenge. Q-chunking adopts action chunking by directly running RL in a 'chunked' action space, enabling the agent to (1) leverage temporally consistent behaviors from offline data for more effective online exploration and (2) use unbiased $n$-step backups for more stable and efficient TD learning. Our experimental results demonstrate that Q-chunking exhibits strong offline performance and online sample efficiency, outperforming prior best offline-to-online methods on a range of long-horizon, sparse-reward manipulation tasks.
toXiv_bot_toot


























































































