RE: https://hachyderm.io/@thomasfuchs/116290622362845597
My main point here is that this is completely normal.
For example it can be cathartic to set someone right and start writing a reply and basically finishing it but then you decide you don't want to have a conversation after all and instead you just ignore the post, or even mute or block.
When writing a parser for a new (programming) language and you find yourself doing a lot of lookahead, and making design compromises to avoid that.. I wonder what a language would end up like if you parsed it backwards from the start? Like just reversed the code as a string. Would the language end up more humane? I guess this is already a thing but don't know the search term..
Love it when I start writing a brief post to blab out here, and it starts becoming a list of ideas, and I quickly realize a blog post needs to happen 🔥
#writing #blogs #blogging
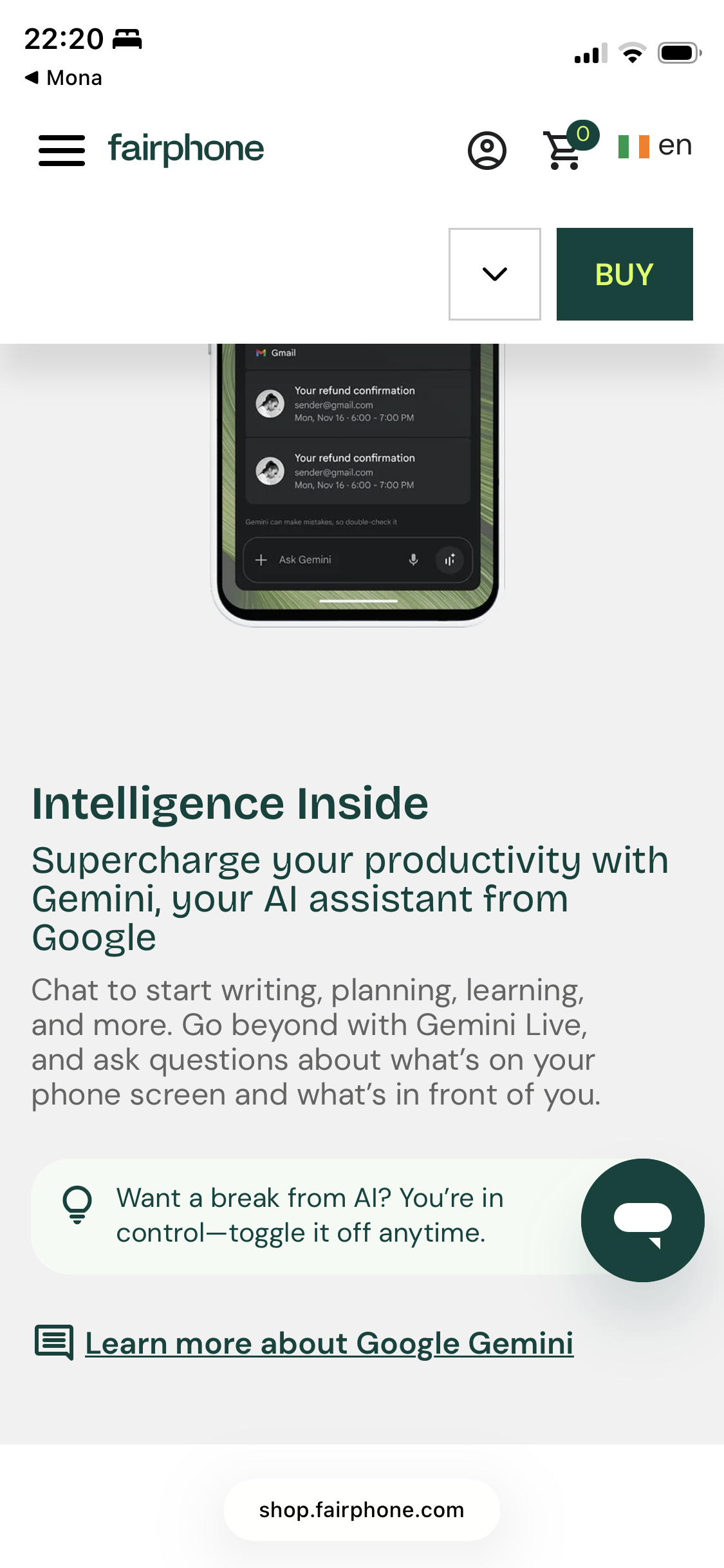
Me: Let’s see how the FairPhone folks are doing… maybe I was overly harsh on them and they’ve used the time to wean themselves off of Google… what with being Waag and all…
Also me: fucking what the fuck now?
*sigh* 🤬
... I'm not too sure if that is feasible, though. I have a former coworker who stopped writing code to start selling houses and I figured that I'm going to start by picking his brain over a cup of coffee.
I also figure that I have ~5 years before the cost of doing such a thing will normalize in any way in America. If every part of the process has a 150% tariff on the cost of materials, it probably won't be worth it.
I just looked for my knitting needles I knew I had, but knitting was so many obsession/fixations ago. I had to look through the detritus of successful and false-start obsessions of years past. There's creative writing. There's photography. There's travel. There's fandom. There's running. There's sewing. There's needlepoint/cross-stitch.
Ah, ha! There's my knitting needles. I knew I had the right ones for this project. Now, where did I put my knitting ba…
the real sign of becoming middle-aged is when you start writing unit tests for even "simple" code
🔊 #NowPlaying on #BBCRadio3:
#SundayMorning
- Three hours of classical sparkle
Join Sarah Walker for a warm, good-humoured soundtrack for the start of February, blending lyrical string writing, joyful Bach and expansive symphonic music.
Relisten now 👇
https://www.bbc.co.uk/programmes/m002qhb6
RE: https://mastodon.social/@eff/115979920525500001
As if we got swallowed in the divinatory nightmarish trip hallucination that would horrify Orwell enough to wake up in the middle of the night to start writing 1984.
 @thomasfuchs@hachyderm.io
@thomasfuchs@hachyderm.io