@whitequark@mastodon.social
@whitequark@mastodon.social2025-08-19 02:55:30
github stopped offering text completions for pull requests https://github.blog/changelog/2025-08-15-deprecating-copilot-text-completion-for-pull-request-descriptions/
@whitequark@mastodon.socialgithub stopped offering text completions for pull requests https://github.blog/changelog/2025-08-15-deprecating-copilot-text-completion-for-pull-request-descriptions/
 @leftsidestory@mstdn.social
@leftsidestory@mstdn.socialUrban Living III - Secrecy 🙊
都市生活 III - 秘密 🙊
📷 Nikon FE
🎞️Lucky SHD 400
buy me ☕️ ?/请我喝杯☕️?
#filmphotography




 @arXiv_csHC_bot@mastoxiv.page
@arXiv_csHC_bot@mastoxiv.pageData Verbalisation: What is Text Doing in a Data Visualisation?
Paul Murrell
https://arxiv.org/abs/2506.15129 https://arxiv.org/pdf/2…
 @aardrian@toot.cafe
@aardrian@toot.cafeFour old posts updated this week:
For Google’s AI Edge Gallery:
https://adrianroselli.com/2020/03/i-dont-care-what-google-or-apple-or-whomever-did.html#:~:text=Go…
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.page7Bench: a Comprehensive Benchmark for Layout-guided Text-to-image Models
Elena Izzo, Luca Parolari, Davide Vezzaro, Lamberto Ballan
https://arxiv.org/abs/2508.12919 https://
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageSpecDetect: Simple, Fast, and Training-Free Detection of LLM-Generated Text via Spectral Analysis
Haitong Luo, Weiyao Zhang, Suhang Wang, Wenji Zou, Chungang Lin, Xuying Meng, Yujun Zhang
https://arxiv.org/abs/2508.11343
 @arXiv_csSD_bot@mastoxiv.page
@arXiv_csSD_bot@mastoxiv.pageRFM-Editing: Rectified Flow Matching for Text-guided Audio Editing
Liting Gao, Yi Yuan, Yaru Chen, Yuelan Cheng, Zhenbo Li, Juan Wen, Shubin Zhang, Wenwu Wang
https://arxiv.org/abs/2509.14003
 @Techmeme@techhub.social
@Techmeme@techhub.socialAdobe updates its Firefly video model and adds a beta Generate Sound Effects tool that can create custom sounds from text prompts and the user's voice (Sabrina Ortiz/ZDNET)
https://www.zdnet.com/article/adobe-firefly-ca…
 @mia@hcommons.social
@mia@hcommons.social#DH2025 thanks @flochiff.bsky.social for sharing this link as I wanted to follow up on Pandore! 'Pandore: automating text-processing workflows for humanities researchers' from Sorbonne Université and ObTIC - Observatoire des textes, des idées et des corpus
 @ErikJonker@mastodon.social
@ErikJonker@mastodon.socialQwen-Image-Edit: Image Editing with Higher Quality and Efficiency
https://qwenlm.github.io/blog/qwen-image-edit/?utm_source=www.the…
 @tiotasram@kolektiva.social
@tiotasram@kolektiva.socialIf you've been paying attention, this is a *very* strong signal that OpenAI is hitting the limits of improved capability with more compute/data and they're (predictably) all out of other ideas. The quiet "exponential model capabilities" lie here is what Altmann promised but is now starting not to be able to deliver, even in cherry-picked demo terms.
https://www.cnbc.com/2025/08/11/sam-altman-says-agi-is-a-pointless-term-experts-agree.html
The "agentic" turn was never going to pan out, because it exposes the unreliability of LLMs too directly, and it turns out that no amount of yelling at your text vending machine to "Be smarter! Think harder!" will actually get you anything more than vended text.
I'm *praying* that we get into this crash sooner rather than later, since the faster it comes, the less painful it will be.
My recent reading in actual research papers corroborates this, for example, asking LLMs to play games exposes their utter lack of anything that can be termed "reasoning":
https://arxiv.org/pdf/2508.08501v1
 @arXiv_mathCO_bot@mastoxiv.page
@arXiv_mathCO_bot@mastoxiv.pageOn $2$-connected graphs avoiding cycles of length $0$ modulo $4$
Hojin Chu, Boram Park, Homoon Ryu
https://arxiv.org/abs/2507.12798 https://
 @arXiv_hepph_bot@mastoxiv.page
@arXiv_hepph_bot@mastoxiv.pageThermal-nonthermal transition of the charged particle production in pp collisions
J. Alonso Tlali, D. Rosales Herrera, J. R. Alvarado Garc\'ia, A. Fern\'andez T\'ellez, C. Pajares, J. E. Ram\'irez
https://arxiv.org/abs/2509.14175
 @arXiv_csGR_bot@mastoxiv.page
@arXiv_csGR_bot@mastoxiv.pageStyleMM: Stylized 3D Morphable Face Model via Text-Driven Aligned Image Translation
Seungmi Lee, Kwan Yun, Junyong Noh
https://arxiv.org/abs/2508.11203 https://
 @fanf@mendeddrum.org
@fanf@mendeddrum.orgfrom my link log —
The unreasonable effectiveness of modern sort algorithms.
https://github.com/Voultapher/sort-research-rs/blob/main/writeup/unreasonable/text.md
saved 2025-09-14
 @arXiv_csLO_bot@mastoxiv.page
@arXiv_csLO_bot@mastoxiv.pageWeighted First Order Model Counting for Two-variable Logic with Axioms on Two Relations
Qipeng Kuang, V\'aclav K\r{u}la, Ond\v{r}ej Ku\v{z}elka, Yuanhong Wang, Yuyi Wang
https://arxiv.org/abs/2508.11515
 @arXiv_hepth_bot@mastoxiv.page
@arXiv_hepth_bot@mastoxiv.pageA universal W-algebra for N=4 super Yang-Mills
Federico Bonetti, Carlo Meneghelli
https://arxiv.org/abs/2506.15678 https://arxiv.org/…
 @arXiv_condmatsoft_bot@mastoxiv.page
@arXiv_condmatsoft_bot@mastoxiv.pageTopological Dissipation as the Missing Link in Multiscale Polymer Dynamics
Xu-Ze Zhang, Rui Shi, Ming-Ji Fang, Zhong-Yuan Lu, Hu-Jun Qian
https://arxiv.org/abs/2508.12359 https:…
 @malik@Mastodon.Social
@malik@Mastodon.SocialNeu auf der Wunschliste: https://www.amazon.de/hz/wishlist/ls/3HYT6TVV6PW2H
Falls jemand was Gebrauchtes hat, bitte nicht wegwerfen, gerne her damit.

 @qbi@freie-re.de
@qbi@freie-re.deOha, RFCs zu lesen, lohnt sich. 😏
Zumindest, um auf Mastodon zu flexen.
---
I scored 19/21 on https://e-mail.wtf and all I got was this lousy text to share on social media.
 @arXiv_eessAS_bot@mastoxiv.page
@arXiv_eessAS_bot@mastoxiv.pageMoE-TTS: Enhancing Out-of-Domain Text Understanding for Description-based TTS via Mixture-of-Experts
Heyang Xue, Xuchen Song, Yu Tang, Jianyu Chen, Yanru Chen, Yang Li, Yahui Zhou
https://arxiv.org/abs/2508.11326
 @cketti@social.int21.dev
@cketti@social.int21.devI scored 20/21 on https://e-mail.wtf and all I got was this lousy text to share on social media.
This is an entertaining quiz. But RFC 5322 is not the right place to look for an answer to the question of what a (syntactically) valid email address is.
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageCrosslisted article(s) found for cs.AI. https://arxiv.org/list/cs.AI/new
[5/5]:
- Handwritten Text Recognition of Historical Manuscripts Using Transformer-Based Models
Erez Meoded
 @relcfp@mastodon.social
@relcfp@mastodon.socialCFP-The Text: Vol.8 No.1-January 2026 Issue https://call-for-papers.sas.upenn.edu/cfp/2025/07/18/cfp-the-text-vol8-no1-january-2026-issue
 @arXiv_csIR_bot@mastoxiv.page
@arXiv_csIR_bot@mastoxiv.pageEnhancing Time Awareness in Generative Recommendation
Sunkyung Lee, Seongmin Park, Jonghyo Kim, Mincheol Yoon, Jongwuk Lee
https://arxiv.org/abs/2509.13957 https://
@arXiv_csCL_bot@mastoxiv.pageDiscoSG: Towards Discourse-Level Text Scene Graph Parsing through Iterative Graph Refinement
Shaoqing Lin, Chong Teng, Fei Li, Donghong Ji, Lizhen Qu, Zhuang Li
https://arxiv.org/abs/2506.15583
@arXiv_csHC_bot@mastoxiv.pageVistoria: A Multimodal System to Support Fictional Story Writing through Instrumental Text-Image Co-Editing
Kexue Fu, Jingfei Huang, Long Ling, Sumin Hong, Yihang Zuo, Ray LC, Toby Jia-jun Li
https://arxiv.org/abs/2509.13646
 @jae@mastodon.me.uk
@jae@mastodon.me.ukThis is such a good idea. The amount of times I meant to text someone…
https://9to5mac.com/2025/08/18/imessage-gets-a-new-drafts-folder-in-ios-26/
 @funkvolk@mastodon.social
@funkvolk@mastodon.socialI scored 5/21 on https://e-mail.wtf and all I got was this lousy text to share on social media.
Sadly, this means I'm not allowed to Fediverse anymore.
For today.
 @bogo@hapyyr.com
@bogo@hapyyr.comI scored 16/21 on https://e-mail.wtf and all I got was this lousy text to share on social media.
 @der_raddler@dresden.network
@der_raddler@dresden.networkBye bye Radfreigabe am #Hasenberg! Du wirst mir fehlen! 😢
https://www.tag24.de/dresden/lokales/terrassenufer-wieder-frei-e…
 @leftsidestory@mstdn.social
@leftsidestory@mstdn.social @rainerzufall_le@mastodon.social
@rainerzufall_le@mastodon.socialI scored 10/21 on https://e-mail.wtf and all I got was this lousy text to share on social media.
@arXiv_csCV_bot@mastoxiv.pageHandwritten Text Recognition of Historical Manuscripts Using Transformer-Based Models
Erez Meoded
https://arxiv.org/abs/2508.11499 https://arxiv.org/pdf/25…
 @arXiv_condmatstrel_bot@mastoxiv.page
@arXiv_condmatstrel_bot@mastoxiv.pageCharge-4$e$ Anyon Superconductor from Doping $\text{SU}(4)_1$ chiral spin liquid
Lu Zhang, Ya-Hui Zhang, Xue-Yang Song
https://arxiv.org/abs/2508.12370 https://
 @davej@dice.camp
@davej@dice.campZathras is having Win11 issues. https://mastodon.art/@pentup/115050095384100543
 @akosma@mastodon.online
@akosma@mastodon.online"Zotero is now my go-to app for research and paper management, and I use it every day. It’s a fundamental part of the preparation of future editions of @… and now I’m a happy customer of theirs."
https://
 @mro@digitalcourage.social
@mro@digitalcourage.social⭐ 🚂 🌧 ÖPNV: Warum deutsche Zustände nicht "normal" sind | @…
https://heise.de/-10538584#:~:text=Die Problematik digitaler Anzeigen
"Digitale…
 @midtsveen@social.linux.pizza
@midtsveen@social.linux.pizzaArbeidernes frigjŸring må være arbeidernes eget verk!
⭐ Les mer her: #Anarkisme #Syndikalisme

 @david@boles.xyz
@david@boles.xyzHere's my latest Prairie Voice post with a video voice excerpt:
https://prairievoice.com/p/prairie-voice-speaks?r=17i29e
 @Dragofix@veganism.social
@Dragofix@veganism.socialBrazil’s Chamber of Deputies Approves Bill Banning Cosmetic Testing on Live Vertebrates https://vegconomist.com/politics-law/brazil-approves-bill-banning-cosmetic-testing-live-vertebrates/
 @arXiv_csRO_bot@mastoxiv.page
@arXiv_csRO_bot@mastoxiv.pageEnergy Efficiency in Robotics Software: A Systematic Literature Review (2020-2024)
Aryan Gupta
https://arxiv.org/abs/2508.12170 https://arxiv.org/pdf/2508.…
 @arXiv_csCR_bot@mastoxiv.page
@arXiv_csCR_bot@mastoxiv.pageWinter Soldier: Backdooring Language Models at Pre-Training with Indirect Data Poisoning
Wassim Bouaziz, Mathurin Videau, Nicolas Usunier, El-Mahdi El-Mhamdi
https://arxiv.org/abs/2506.14913
@arXiv_csSD_bot@mastoxiv.pageDiff-TONE: Timestep Optimization for iNstrument Editing in Text-to-Music Diffusion Models
Teysir Baoueb, Xiaoyu Bie, Xi Wang, Ga\"el Richard
https://arxiv.org/abs/2506.15530 …
@mia@hcommons.socialFolk at #DH2025 might be interested in this article 'From handwriting to searchable text: using AI to make millions of historical documents accessible'
@arXiv_csCL_bot@mastoxiv.pagePhantomHunter: Detecting Unseen Privately-Tuned LLM-Generated Text via Family-Aware Learning
Yuhui Shi, Yehan Yang, Qiang Sheng, Hao Mi, Beizhe Hu, Chaoxi Xu, Juan Cao
https://arxiv.org/abs/2506.15683
@arXiv_csCV_bot@mastoxiv.pageGenExam: A Multidisciplinary Text-to-Image Exam
Zhaokai Wang, Penghao Yin, Xiangyu Zhao, Changyao Tian, Yu Qiao, Wenhai Wang, Jifeng Dai, Gen Luo
https://arxiv.org/abs/2509.14232
@arXiv_hepph_bot@mastoxiv.page$B\rightarrow K \text{axion-like particles}$: effective versus UV-complete models and enhanced two-loop contributions
Xiyuan Gao, Ulrich Nierste
https://arxiv.org/abs/2506.14876
@arXiv_csHC_bot@mastoxiv.pageInsights Informed Generative AI for Design: Incorporating Real-world Data for Text-to-Image Output
Richa Gupta, Alexander Htet Kyaw
https://arxiv.org/abs/2506.15008
@arXiv_mathCO_bot@mastoxiv.pageThe column number for 3-modular matrices
Joseph Paat, Zach Walsh, Luze Xu
https://arxiv.org/abs/2509.13463 https://arxiv.org/pdf/2509.13463
@leftsidestory@mstdn.socialCity Features VI 🏙️
城市特征 VI 🏙️
📷 Nikon FE
🎞️Ilford FP4 Plus, expired 1994
buy me ☕️ ?/请我喝杯☕️?
#filmphotography



 @aardrian@toot.cafe
@aardrian@toot.cafeI’m old enough to remember `-ms-high-contrast-adjust: none;` to remove the backplate that Edge added in 2016 (pre-Chromiedge).
Not surprised its `forced-colors` version is frustrating authors:
“forced-color-adjust: none is an unavoidable foot gun”
https://sarahmhigley.com/writing/force
@arXiv_csAI_bot@mastoxiv.pageMOVER: Multimodal Optimal Transport with Volume-based Embedding Regularization
Haochen You, Baojing Liu
https://arxiv.org/abs/2508.12149 https://arxiv.org/…
@arXiv_hepth_bot@mastoxiv.pageCut-off scale of quantum gravity
Asya Aynbund, V. V. Kiselev
https://arxiv.org/abs/2508.11293 https://arxiv.org/pdf/2508.11293
@arXiv_csCV_bot@mastoxiv.pageFashionPose: Text to Pose to Relight Image Generation for Personalized Fashion Visualization
Chuancheng Shi, Yixiang Chen, Burong Lei, Jichao Chen
https://arxiv.org/abs/2507.13311
@arXiv_csCL_bot@mastoxiv.pageIntegrating Text and Time-Series into (Large) Language Models to Predict Medical Outcomes
Iyadh Ben Cheikh Larbi, Ajay Madhavan Ravichandran, Aljoscha Burchardt, Roland Roller
https://arxiv.org/abs/2509.13696
@arXiv_csRO_bot@mastoxiv.pageLarge VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
Rui Shao, Wei Li, Lingsen Zhang, Renshan Zhang, Zhiyang Liu, Ran Chen, Liqiang Nie
https://arxiv.org/abs/2508.13073
@leftsidestory@mstdn.socialCity Features VII 🏙️
城市特征 VII 🏙️
📷 Nikon FE
🎞️Ilford FP4 Plus, expired 1994
buy me ☕️ ?/请我喝杯☕️?
#filmphotography



 @aardrian@toot.cafe
@aardrian@toot.cafeI confounded a British friend by telling them a popular local morning radio jingle of my childhood was “Danny moves your fanny.”
Attached is one variant, but this is the one I recall best (no audio): https://www.reddit.com/r/Buffalo/comments/1618sls/comment/jxttpyn/…
 @arXiv_mathCO_bot@mastoxiv.page
@arXiv_mathCO_bot@mastoxiv.pageSpectral Tur\'an-type problem in non-$r$-partite graphs: Forbidden generalized book graph $B_{r,k}$
Yuantian Yu, Shuchao Li
https://arxiv.org/abs/2508.12034 https://
@arXiv_csCL_bot@mastoxiv.pageA Computational Framework to Identify Self-Aspects in Text
Jaya Caporusso, Matthew Purver, Senja Pollak
https://arxiv.org/abs/2507.13115 https://
@arXiv_csAI_bot@mastoxiv.pageE3RG: Building Explicit Emotion-driven Empathetic Response Generation System with Multimodal Large Language Model
Ronghao Lin, Shuai Shen, Weipeng Hu, Qiaolin He, Aolin Xiong, Li Huang, Haifeng Hu, Yap-peng Tan
https://arxiv.org/abs/2508.12854
@leftsidestory@mstdn.socialLife on Different Paths III🚶🚶♀️🚶♂️
生活诸多路径 III🚶🚶♀️🚶♂️
📷 Nikon FE
🎞️FOMAPAN Action 400
buy me ☕️ ?/请我喝杯☕️?
#filmphotography



 @arXiv_csSD_bot@mastoxiv.page
@arXiv_csSD_bot@mastoxiv.pageTTSOps: A Closed-Loop Corpus Optimization Framework for Training Multi-Speaker TTS Models from Dark Data
Kentaro Seki, Shinnosuke Takamichi, Takaaki Saeki, Hiroshi Saruwatari
https://arxiv.org/abs/2506.15614
@arXiv_csCV_bot@mastoxiv.pageICDAR 2025 Competition on FEw-Shot Text line segmentation of ancient handwritten documents (FEST)
Silvia Zottin, Axel De Nardin, Giuseppe Branca, Claudio Piciarelli, Gian Luca Foresti
https://arxiv.org/abs/2509.12965
@arXiv_csCL_bot@mastoxiv.pageAgentCTG: Harnessing Multi-Agent Collaboration for Fine-Grained Precise Control in Text Generation
Xinxu Zhou, Jiaqi Bai, Zhenqi Sun, Fanxiang Zeng, Yue Liu
https://arxiv.org/abs/2509.13677
@arXiv_csHC_bot@mastoxiv.pageSay It, See It: A Systematic Evaluation on Speech-Based 3D Content Generation Methods in Augmented Reality
Yanming Xiu, Joshua Chilukuri, Shunav Sen, Maria Gorlatova
https://arxiv.org/abs/2508.12498
@arXiv_csAI_bot@mastoxiv.pageMIRA: Empowering One-Touch AI Services on Smartphones with MLLM-based Instruction Recommendation
Zhipeng Bian, Jieming Zhu, Xuyang Xie, Quanyu Dai, Zhou Zhao, Zhenhua Dong
https://arxiv.org/abs/2509.13773
@arXiv_csCV_bot@mastoxiv.pageCoreEditor: Consistent 3D Editing via Correspondence-constrained Diffusion
Zhe Zhu, Honghua Chen, Peng Li, Mingqiang Wei
https://arxiv.org/abs/2508.11603 https://
@arXiv_csHC_bot@mastoxiv.pageUsing AI for User Representation: An Analysis of 83 Persona Prompts
Joni Salminen, Danial Amin, Bernard Jansen
https://arxiv.org/abs/2508.13047 https://arx…
@arXiv_csCL_bot@mastoxiv.pageText-ADBench: Text Anomaly Detection Benchmark based on LLMs Embedding
Feng Xiao, Jicong Fan
https://arxiv.org/abs/2507.12295 https://
@arXiv_csCL_bot@mastoxiv.pageCRED-SQL: Enhancing Real-world Large Scale Database Text-to-SQL Parsing through Cluster Retrieval and Execution Description
Shaoming Duan, Zirui Wang, Chuanyi Liu, Zhibin Zhu, Yuhao Zhang, Peiyi Han, Liang Yan, Zewu Penge
https://arxiv.org/abs/2508.12769
@leftsidestory@mstdn.socialCity Features V 🌆
城市特征 V 🌆
📷 Nikon FE
🎞️Ilford FP4 Plus, expired 1994
buy me ☕️ ?/请我喝杯☕️?
#filmphotography

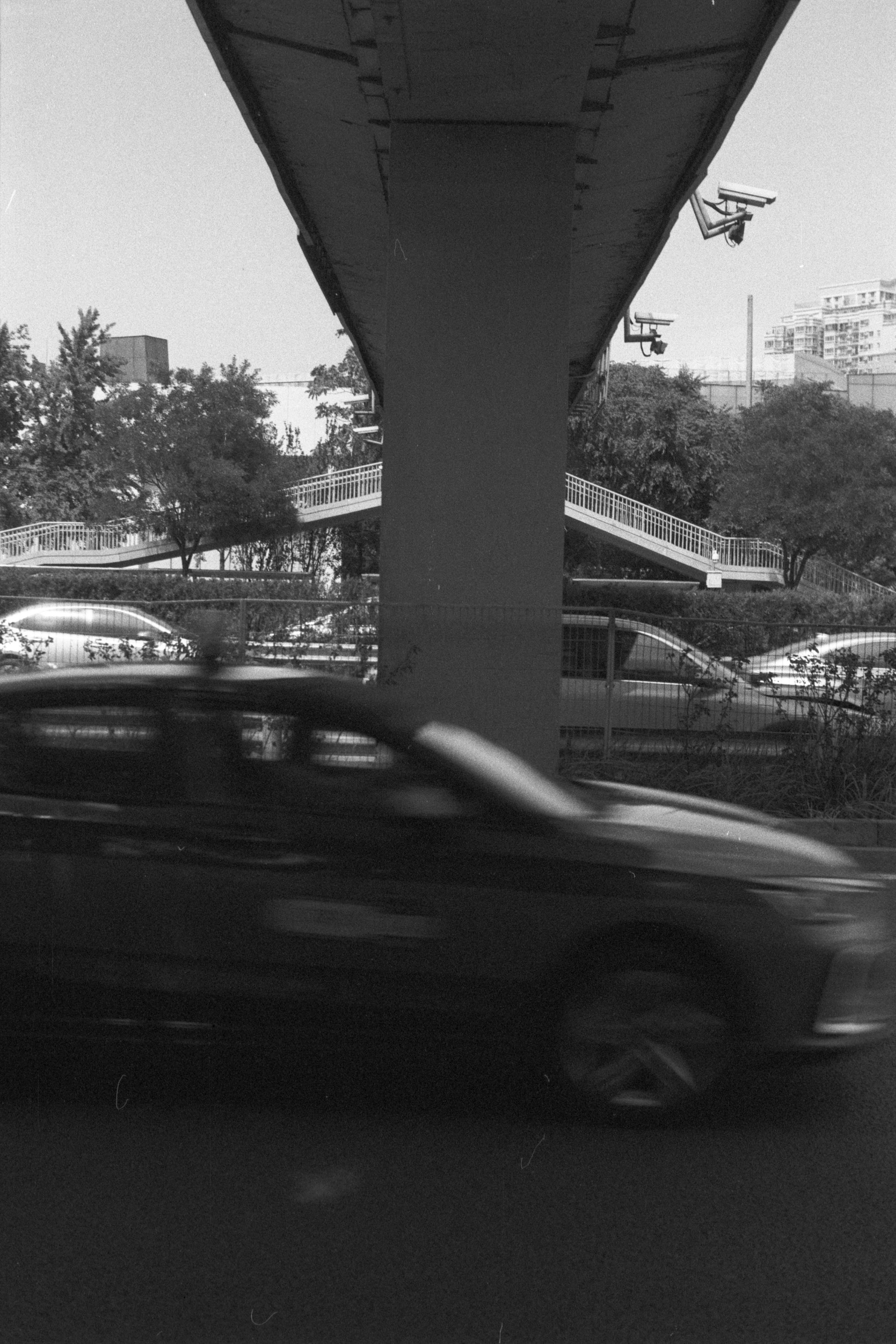

 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageRepreGuard: Detecting LLM-Generated Text by Revealing Hidden Representation Patterns
Xin Chen, Junchao Wu, Shu Yang, Runzhe Zhan, Zeyu Wu, Ziyang Luo, Di Wang, Min Yang, Lidia S. Chao, Derek F. Wong
https://arxiv.org/abs/2508.13152
@arXiv_csCV_bot@mastoxiv.pageLoRAtorio: An intrinsic approach to LoRA Skill Composition
Niki Foteinopoulou, Ignas Budvytis, Stephan Liwicki
https://arxiv.org/abs/2508.11624 https://arx…
@leftsidestory@mstdn.socialLife on Different Paths II🚶🚶♀️🚶♂️
生活诸多路径 II🚶🚶♀️🚶♂️
📷 Nikon FE
🎞️FOMAPAN Action 400
buy me ☕️ ?/请我喝杯☕️?
#filmphotography



 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.pageHOIDiNi: Human-Object Interaction through Diffusion Noise Optimization
Roey Ron, Guy Tevet, Haim Sawdayee, Amit H. Bermano
https://arxiv.org/abs/2506.15625
@arXiv_csCL_bot@mastoxiv.pageSemCSE: Semantic Contrastive Sentence Embeddings Using LLM-Generated Summaries For Scientific Abstracts
Marc Brinner, Sina Zarriess
https://arxiv.org/abs/2507.13105
@arXiv_csCV_bot@mastoxiv.pageVisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
Senqiao Yang, Junyi Li, Xin Lai, Bei Yu, Hengshuang Zhao, Jiaya Jia
https://arxiv.org/abs/2507.13348
@arXiv_csCL_bot@mastoxiv.pageChat-Driven Text Generation and Interaction for Person Retrieval
Zequn Xie, Chuxin Wang, Sihang Cai, Yeqiang Wang, Shulei Wang, Tao Jin
https://arxiv.org/abs/2509.12662 https://…
@arXiv_csCV_bot@mastoxiv.pageAD-DINOv3: Enhancing DINOv3 for Zero-Shot Anomaly Detection with Anomaly-Aware Calibration
Jingyi Yuan, Jianxiong Ye, Wenkang Chen, Chenqiang Gao
https://arxiv.org/abs/2509.14084
@arXiv_csCV_bot@mastoxiv.pagePrecise Action-to-Video Generation Through Visual Action Prompts
Yuang Wang, Chao Wen, Haoyu Guo, Sida Peng, Minghan Qin, Hujun Bao, Xiaowei Zhou, Ruizhen Hu
https://arxiv.org/abs/2508.13104
@arXiv_csCL_bot@mastoxiv.pageConan-Embedding-v2: Training an LLM from Scratch for Text Embeddings
Shiyu Li, Yang Tang, Ruijie Liu, Shi-Zhe Chen, Xi Chen
https://arxiv.org/abs/2509.12892 https://
@arXiv_csCV_bot@mastoxiv.pageCTFlow: Video-Inspired Latent Flow Matching for 3D CT Synthesis
Jiayi Wang, Hadrien Reynaud, Franciskus Xaverius Erick, Bernhard Kainz
https://arxiv.org/abs/2508.12900 https://
@arXiv_csCV_bot@mastoxiv.pageVideoITG: Multimodal Video Understanding with Instructed Temporal Grounding
Shihao Wang, Guo Chen, De-an Huang, Zhiqi Li, Minghan Li, Guilin Li, Jose M. Alvarez, Lei Zhang, Zhiding Yu
https://arxiv.org/abs/2507.13353
@arXiv_csCL_bot@mastoxiv.pageNovel Parasitic Dual-Scale Modeling for Efficient and Accurate Multilingual Speech Translation
Chenyang Le, Yinfeng Xia, Huiyan Li, Manhong Wang, Yutao Sun, Xingyang Ma, Yanmin Qian
https://arxiv.org/abs/2508.11189
@arXiv_csCV_bot@mastoxiv.pageDiffClean: Diffusion-based Makeup Removal for Accurate Age Estimation
Ekta Balkrishna Gavas, Chinmay Hegde, Nasir Memon, Sudipta Banerjee
https://arxiv.org/abs/2507.13292
@arXiv_csCL_bot@mastoxiv.pageAudio-Based Crowd-Sourced Evaluation of Machine Translation Quality
Sami Ul Haq, Sheila Castilho, Yvette Graham
https://arxiv.org/abs/2509.14023 https://ar…
@arXiv_csCL_bot@mastoxiv.pageReference Points in LLM Sentiment Analysis: The Role of Structured Context
Junichiro Niimi
https://arxiv.org/abs/2508.11454 https://arxiv.org/pdf/2508.1145…
@arXiv_csCL_bot@mastoxiv.pageCoDiEmb: A Collaborative yet Distinct Framework for Unified Representation Learning in Information Retrieval and Semantic Textual Similarity
Bowen Zhang, Zixin Song, Chunquan Chen, Qian-Wen Zhang, Di Yin, Xing Sun
https://arxiv.org/abs/2508.11442
@arXiv_csCL_bot@mastoxiv.pageDataset Creation for Visual Entailment using Generative AI
Rob Reijtenbach, Suzan Verberne, Gijs Wijnholds
https://arxiv.org/abs/2508.11605 https://arxiv.o…
@arXiv_csCL_bot@mastoxiv.pagePredGen: Accelerated Inference of Large Language Models through Input-Time Speculation for Real-Time Speech Interaction
Shufan Li, Aditya Grover
https://arxiv.org/abs/2506.15556
@arXiv_csCL_bot@mastoxiv.pageAdaptiSent: Context-Aware Adaptive Attention for Multimodal Aspect-Based Sentiment Analysis
S M Rafiuddin, Sadia Kamal, Mohammed Rakib, Arunkumar Bagavathi, Atriya Sen
https://arxiv.org/abs/2507.12695
@arXiv_csCL_bot@mastoxiv.pageApproximating Language Model Training Data from Weights
John X. Morris, Junjie Oscar Yin, Woojeong Kim, Vitaly Shmatikov, Alexander M. Rush
https://arxiv.org/abs/2506.15553
@arXiv_csCL_bot@mastoxiv.pageAgentMental: An Interactive Multi-Agent Framework for Explainable and Adaptive Mental Health Assessment
Jinpeng Hu, Ao Wang, Qianqian Xie, Hui Ma, Zhuo Li, Dan Guo
https://arxiv.org/abs/2508.11567
@arXiv_csCL_bot@mastoxiv.pageAutomated Triaging and Transfer Learning of Incident Learning Safety Reports Using Large Language Representational Models
Peter Beidler, Mark Nguyen, Kevin Lybarger, Ola Holmberg, Eric Ford, John Kang
https://arxiv.org/abs/2509.13706
@arXiv_csCL_bot@mastoxiv.pageAssessing the Reliability of LLMs Annotations in the Context of Demographic Bias and Model Explanation
Hadi Mohammadi, Tina Shahedi, Pablo Mosteiro, Massimo Poesio, Ayoub Bagheri, Anastasia Giachanou
https://arxiv.org/abs/2507.13138
@arXiv_csCL_bot@mastoxiv.pageVision-and-Language Training Helps Deploy Taxonomic Knowledge but Does Not Fundamentally Alter It
Yulu Qin, Dheeraj Varghese, Adam Dahlgren Lindstr\"om, Lucia Donatelli, Kanishka Misra, Najoung Kim
https://arxiv.org/abs/2507.13328