 @tante@tldr.nettime.org
@tante@tldr.nettime.org2026-02-24 11:54:41
@tante@tldr.nettime.org @leftsidestory@mstdn.social
@leftsidestory@mstdn.socialUrban Demons III 👻
城市鬼魂 III 👻
📷 Nikon F4E
🎞️ Rollei RPX 400
If you like my work, buy me a coffee from PayPal #filmphotography




 @georgiamuseum@glammr.us
@georgiamuseum@glammr.us#EleanorHimmelfarb isn't a household name when it comes to abstraction, but look at how beautiful and complex her work is. Her painting "On the Fourth Day" is now on view in our galleries. Learn more about how nature inspired her work and her history of environmental activism.

 @catsalad@infosec.exchange
@catsalad@infosec.exchangeHas science gone too far?

 @thomasfuchs@hachyderm.io
@thomasfuchs@hachyderm.io"LLMs work (somewhat) for coding computer programs. As everyone knows this is the highest form of human endeavor—unsurpassed by any other lesser activity such as project management, design, art or writing. Therefore LLMs will excel in every other field."
I really believe this is the crux understanding why so many programmers (including good programmers) fall for it in a way that can only be described as a cult, were any criticism is not only not allowed but reflexively is seen as either laughable or belligerent.
Anyway, LLMs are good* at writing code because writing code is easy and highly repetitive and doesn't actually take a lot of skill; unless it's novel ways to write code which LLMs cannot do.
Taking this as a sign LLMs can do other "lesser" activities is saying a lot about the hubris of programmers and not a lot of the capabilities of LLMs.
*for some definitions of "good"
 @iam_jfnklstrm@social.linux.pizza
@iam_jfnklstrm@social.linux.pizzaThe art of procrastination is doing work without anything to show for it. Cuz I'm working on it in my head...
 @anildash@me.dm
@anildash@me.dmAn absolutely extraordinary look at how to improve rendering of ASCII art, first in static images, then in motion. As he gets into contrast enhancement for complex grayscale animations, the vector lookup works starts to be parallel to work happening with language models. Just an excellent narration. https://alexharri.com/blog/ascii-…
@leftsidestory@mstdn.socialRare Colours Blues II🔷🔷
稀有的色彩蓝 II🔷🔷
📷 Pentax MX
🎞️ Harman Phoenix 200 II (FF)
#filmphotography #Photography #Art




 @arXiv_csDS_bot@mastoxiv.page
@arXiv_csDS_bot@mastoxiv.pageApproximate Cartesian Tree Matching with Substitutions
Panagiotis Charalampopoulos, Jonas Ellert, Manal Mohamed
https://arxiv.org/abs/2602.08570 https://arxiv.org/pdf/2602.08570 https://arxiv.org/html/2602.08570
arXiv:2602.08570v1 Announce Type: new
Abstract: The Cartesian tree of a sequence captures the relative order of the sequence's elements. In recent years, Cartesian tree matching has attracted considerable attention, particularly due to its applications in time series analysis. Consider a text $T$ of length $n$ and a pattern $P$ of length $m$. In the exact Cartesian tree matching problem, the task is to find all length-$m$ fragments of $T$ whose Cartesian tree coincides with the Cartesian tree $CT(P)$ of the pattern. Although the exact version of the problem can be solved in linear time [Park et al., TCS 2020], it remains rather restrictive; for example, it is not robust to outliers in the pattern.
To overcome this limitation, we consider the approximate setting, where the goal is to identify all fragments of $T$ that are close to some string whose Cartesian tree matches $CT(P)$. In this work, we quantify closeness via the widely used Hamming distance metric. For a given integer parameter $k>0$, we present an algorithm that computes all fragments of $T$ that are at Hamming distance at most $k$ from a string whose Cartesian tree matches $CT(P)$. Our algorithm runs in time $\mathcal O(n \sqrt{m} \cdot k^{2.5})$ for $k \leq m^{1/5}$ and in time $\mathcal O(nk^5)$ for $k \geq m^{1/5}$, thereby improving upon the state-of-the-art $\mathcal O(nmk)$-time algorithm of Kim and Han [TCS 2025] in the regime $k = o(m^{1/4})$.
On the way to our solution, we develop a toolbox of independent interest. First, we introduce a new notion of periodicity in Cartesian trees. Then, we lift multiple well-known combinatorial and algorithmic results for string matching and periodicity in strings to Cartesian tree matching and periodicity in Cartesian trees.
toXiv_bot_toot
 @smashtie@mas.to
@smashtie@mas.toIt was a revelation to see Nigerian Modernism at the Tate, especially seeing the rooms full of people who clearly felt a strong, personal connection to the work. Here are some of my favourites.
#Art



 @samerfarha@mastodon.social
@samerfarha@mastodon.socialWelp, this is heart breaking. Brewer’s Art was so good for so long. What a shame. I hope Volker finds a way to make sure staff are taken care of.
https://www.prismnews.com/news/mount-vernon-brewpub-the-brewers-art-permanently-closes-afte…
 @michabbb@social.vivaldi.net
@michabbb@social.vivaldi.net- Customer vetting done in minutes, not weeks
- Synthesizes 50 data sources into one clear, actionable picture
- Delivers finished output: documents, decks, webpages, even full apps
📊 It's not just fast. Grep is state-of-the-art — top-ranked on the Deep Research Benchmark — so you get accuracy when it actually matters.
Whether you're a founder validating a market, an investor vetting a deal, or a strategist tracking competitors: serious work deserves serious …
 @BBC3MusicBot@mastodonapp.uk
@BBC3MusicBot@mastodonapp.uk🔊 #NowPlaying on #BBCRadio3:
#ThroughTheNight
- Andršs Schiff plays Bach's The Art of Fugue
Andršs Schiff performs Bach's The Art of Fugue, which he described as 'the greatest work by the greatest composer who ever lived.' From the 2025 BBC Proms at the Royal Albert Hall.
Relisten now 👇
https://www.bbc.co.uk/programmes/m002qqm4
 @mariyadelano@hachyderm.io
@mariyadelano@hachyderm.ioRE: https://techhub.social/@shantini/115957020152303871
Being a marketer shaped my progressive politics more than I expected precisely because of this.
Once you see how much effort is being spent on marketing certain worldviews to you and how much of that can be studied, analyzed, and replicated - you can’t unsee it.
And you see the power that’s available for all of us to tap into to push back. The same kinds of marketing and communication tactics used against us can be used to amplify science, art, pro-social values, and progressive policy.
The right has been waging a coordinated campaign of swaying public opinion since at least the birth of the Federalist Society and backlash to Roe.
Their legal influence required creating an information and media apparatus that influenced first elite professional networks, then the public at large.
(For a recent example, just look at how much LLMS and AI have been relying on constant marketing and media attention for anyone to believe that these tools are “inevitable” or even “useful”. Their marketing and PR departments work very hard and are very well funded. For a reason.)
 @benb@osintua.eu
@benb@osintua.eu🇺🇦 Ukrainian ARTILLERISTS work under a SHOWER of Russian FPV drones #shorts: https://benborges.xyz/2026/02/03/ukrainian-artillerists-work-under-a.html
 @GroupNebula563@mastodon.social
@GroupNebula563@mastodon.socialCW: not safe for work art
 @groupnebula563@mastodon.social
@groupnebula563@mastodon.socialCW: not safe for work art
 @philip@mastodon.mallegolhansen.com
@philip@mastodon.mallegolhansen.comDue to a slight gift mishap, I find myself with a duplicate copy of volumes 1 - 3 of Donald Knuth’s “The Art of Computer Programming” post-Christmas.
If anyone in the PDX area would cherish a copy of this work, I’d like to talk to you!
I’d rather see it going to a loving home than put too much effort into maximizing sales value.
#PDX
 @v_i_o_l_a@openbiblio.social
@v_i_o_l_a@openbiblio.social"AI Tools Are Changing Academic Publishing. How Can We Adopt Them Responsibly?" @ Katina Magazine
https://katinamagazine.org/content/article/future-of-work/2026/ai-tools-are-changing-publishing-adopt-them-respons…
 @jake4480@c.im
@jake4480@c.imPreparing for another work week
 @arXiv_csDS_bot@mastoxiv.page
@arXiv_csDS_bot@mastoxiv.pagePrune, Don't Rebuild: Efficiently Tuning $\alpha$-Reachable Graphs for Nearest Neighbor Search
Tian Zhang, Ashwin Padaki, Jiaming Liang, Zack Ives, Erik Waingarten
https://arxiv.org/abs/2602.08097 https://arxiv.org/pdf/2602.08097 https://arxiv.org/html/2602.08097
arXiv:2602.08097v1 Announce Type: new
Abstract: Vector similarity search is an essential primitive in modern AI and ML applications. Most vector databases adopt graph-based approximate nearest neighbor (ANN) search algorithms, such as DiskANN (Subramanya et al., 2019), which have demonstrated state-of-the-art empirical performance. DiskANN's graph construction is governed by a reachability parameter $\alpha$, which gives a trade-off between construction time, query time, and accuracy. However, adaptively tuning this trade-off typically requires rebuilding the index for different $\alpha$ values, which is prohibitive at scale. In this work, we propose RP-Tuning, an efficient post-hoc routine, based on DiskANN's pruning step, to adjust the $\alpha$ parameter without reconstructing the full index. Within the $\alpha$-reachability framework of prior theoretical works (Indyk and Xu, 2023; Gollapudi et al., 2025), we prove that pruning an initially $\alpha$-reachable graph with RP-Tuning preserves worst-case reachability guarantees in general metrics and improved guarantees in Euclidean metrics. Empirically, we show that RP-Tuning accelerates DiskANN tuning on four public datasets by up to $43\times$ with negligible overhead.
toXiv_bot_toot
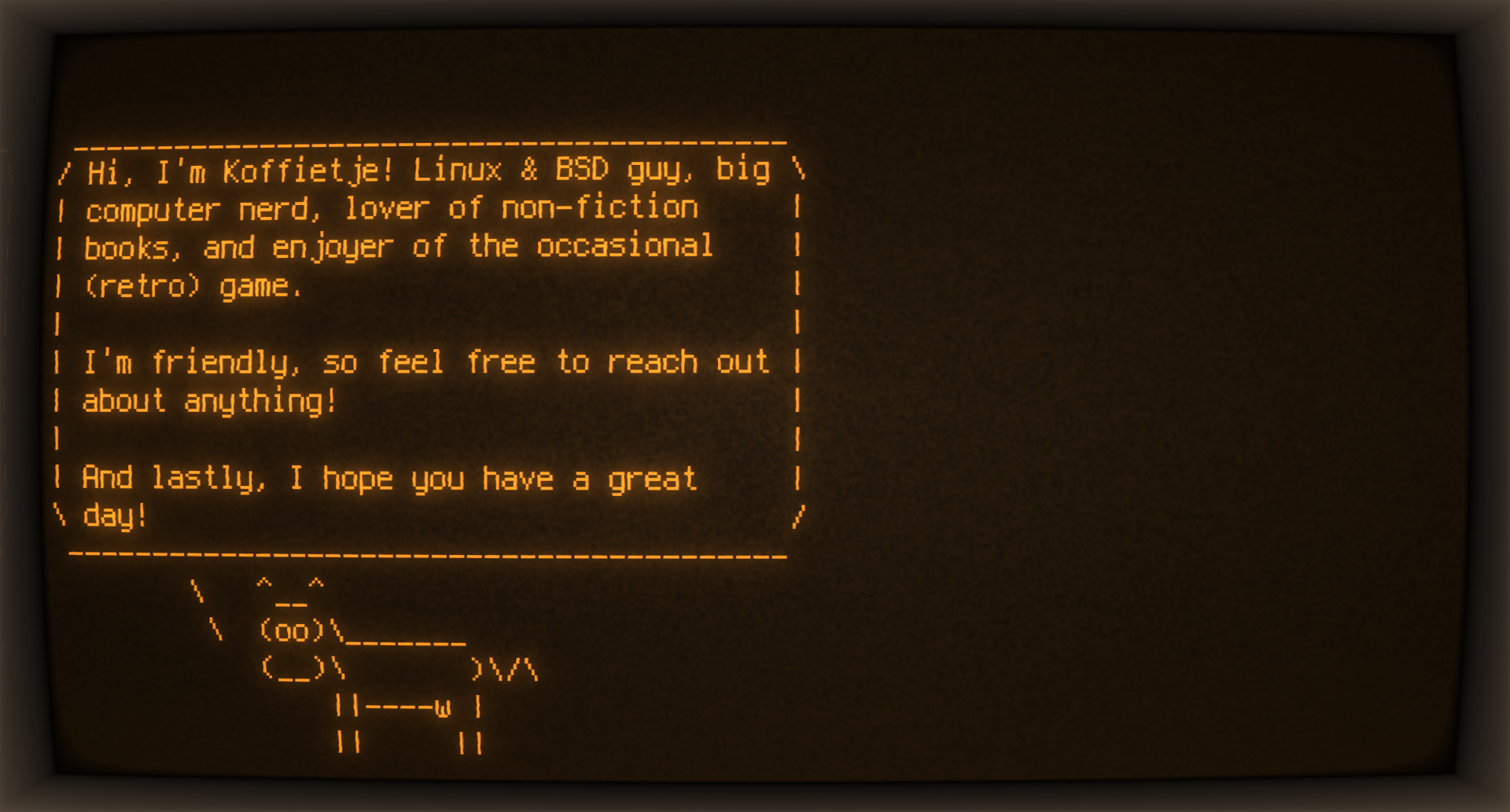
 @Koffietje@social.linux.pizza
@Koffietje@social.linux.pizzaHi! I'm Koffietje! (Not very original, might change that later.)
Obviously, I'm a big fan of coffee! Generally black, over-steeped in a French press. But lately I've been messing around with the Moka pot.
I'm also big on Linux. My daily driver is Fedora, which seems to work incredibly well on my computers. I'm also curious about ARM & RISC-V, and have dipped my toes into BSD. Always trying to learn more, and currently I'm working on my Bash skills, tryi…
 @mgorny@social.treehouse.systems
@mgorny@social.treehouse.systemsIn the age of "#AI" assisted programming and "vibe coding", I don't feel like calling myself a programmer anymore. In fact, I think that "an artist" is more appropriate.
All the code I write is mine entirely. It might be buggy, it might be inconsistent, but it reflects my personality. I've put my metaphorical soul into it. It's a work of art.
If people want to call themselves "software developers", and want their work described as a glorified copy-paste, so be it. I'm a software artist now.
EDIT: "craftsperson" is also a nice term, per the comments.
#NoAI #NoLLM #LLM

