 @benb@osintua.eu
@benb@osintua.eu2025-10-18 12:22:02
Russia keeps hitting Ukraine's training centers — and Ukraine doesn't have an answer: https://benborges.xyz/2025/10/18/russia-keeps-hitting-ukraines-training.html
@benb@osintua.euRussia keeps hitting Ukraine's training centers — and Ukraine doesn't have an answer: https://benborges.xyz/2025/10/18/russia-keeps-hitting-ukraines-training.html
 @bmgnrs@mastodon.social
@bmgnrs@mastodon.social„Only in the world of AI algorithm training can you claim that you were torrenting 2,400 porn videos for personal use and have that seem like the lesser of two evils.“ 😂
https://www.vice.com/en/article/meta-says-the-2400-ad…
 @qurlyjoe@mstdn.social
@qurlyjoe@mstdn.socialCan an octopus learn to play a piano? This guy, Mattias Krantz, tried to find out. He rescues a random octopus from a fish market and then tries to work out how to teach it to play. You can skip the training to 15:20 to hear their first duet, but the training is interesting too. https://youtu.be/PcWnQ7fYzwI?si=BMFFE7
 @Techmeme@techhub.social
@Techmeme@techhub.socialIsrael-based Second Nature, whose conversational AI helps train sales teams, raised a $22M Series B led by Sienna VC, taking its total raised to $80M (Meir Orbach/CTech)
https://www.calcalistech.com/ctechnews/article/bj0cciralg
 @radioeinsmusicbot@mastodonapp.uk
@radioeinsmusicbot@mastodonapp.uk🇺🇦 Auf radioeins läuft...
Doja Cat:
🎵 Aaahh Men!
#NowPlaying #DojaCat
https://thataquafinagirl.bandcamp.com/track/aaahh-men-x-training-season-doja-cat-x-dua-lipa-mashup
https://open.spotify.com/track/2qGvxAKXbajPFRb9ybIMOD
Schon gewusst❓
Wenn Du einen Beitrag des Bots ⭐ FAVORISIERST, erfährt das nur der Bot - nicht Deine FollowerInnen.
Wenn Du einen Song weitererempfehlen möchtest, dann 🔁 TEILE ihn❗
@benb@osintua.euRussian missile strikes Ukrainian training ground, casualties reported, military says: https://benborges.xyz/2025/10/16/russian-missile-strikes-ukrainian-training.html
 @cdarwin@c.im
@cdarwin@c.imStanding atop a seven-ton military truck with his wife, Vance watched the largest Marine exercise in a decade on Oct. 18,
featuring F-18 and F-35 flyovers,
parachute landings,
Navy Seals swimming ashore,
offshore destroyers and amphibious ships,
simulated village explosions,
and MH-60 helicopters dropping additional Seals over the water.
-- all to distract attention from the massive "No Kings" protests happening all across the country.
 @Mediagazer@mstdn.social
@Mediagazer@mstdn.socialOpenAI launches the OpenAI Academy for News Organizations, which offers journalists AI training, open-source projects, and practical use cases (OpenAI)
https://openai.com/index/openai-academy-for-news-organizations
 @seeingwithsound@mas.to
@seeingwithsound@mas.toShort-term, the money may be in implantable visual prostheses for the blind. Longer-term, the money may be in training & support for noninvasive visual prostheses for the blind https://www.artificialvision.com/neuralink.htm Microsoft Windows vs Linux, Neuralink Blindsight vs The vOIC…

 @scottmiller42@mstdn.social
@scottmiller42@mstdn.socialI’m in a work training for a agentic AI we will soon have access to. One use case that was suggested is researching and summarizing HR policy on a topic or for a question.
Oof. I expect it won’t be long before I read a news article where someone brings a wrongful termination suit based on either end of such a AI query.
#OfficeWorkerGripes
 @heiseonline@social.heise.de
@heiseonline@social.heise.deKI-Training: Normalsprachlicher Nutzungsvorbehalt reicht OLG Hamburg nicht
Das OLG in Hamburg hat im Fall der Klage eines Fotografen gegen den KI-Modell-Trainingsverein Laion die Berufung zurückgewiesen, eine Revision aber zugelassen.
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.pageLaminar: A Scalable Asynchronous RL Post-Training Framework
Guangming Sheng, Yuxuan Tong, Borui Wan, Wang Zhang, Chaobo Jia, Xibin Wu, Yuqi Wu, Xiang Li, Chi Zhang, Yanghua Peng, Haibin Lin, Xin Liu, Chuan Wu
https://arxiv.org/abs/2510.12633
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.pageViCO: A Training Strategy towards Semantic Aware Dynamic High-Resolution
Long Cui, Weiyun Wang, Jie Shao, Zichen Wen, Gen Luo, Linfeng Zhang, Yanting Zhang, Yu Qiao, Wenhai Wang
https://arxiv.org/abs/2510.12793
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageGOAT: A Training Framework for Goal-Oriented Agent with Tools
Hyunji Min, Sangwon Jung, Junyoung Sung, Dosung Lee, Leekyeung Han, Paul Hongsuck Seo
https://arxiv.org/abs/2510.12218
 @NFL@darktundra.xyz
@NFL@darktundra.xyzSources: Colts' Jones expected back for camp https://www.espn.com/nfl/story/_/id/47295871/sources-daniel-jones-expected-cleared-training-camp
 @arXiv_csNI_bot@mastoxiv.page
@arXiv_csNI_bot@mastoxiv.pageGeoPipe: a Geo-distributed LLM Training Framework with enhanced Pipeline Parallelism in a Lossless RDMA-enabled Datacenter Optical Transport Network
Jun Dai, Xiaorun Wang, Kexiong Fang, Zheng Yang, Yuefeng Ji, Jiawei Zhang
https://arxiv.org/abs/2510.12064
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageStabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers
Wenhan Ma, Hailin Zhang, Liang Zhao, Yifan Song, Yudong Wang, Zhifang Sui, Fuli Luo
https://arxiv.org/abs/2510.11370
 @metacurity@infosec.exchange
@metacurity@infosec.exchangeSentinelLabs' Dakota Cary linked Yu Yang and Qiu Daibing, two alleged members of the Chinese state hacking group, to participants of the 2012 Cisco Networking Academy Cup.
https://www.theregister.com/2025/12/11/salt_typhoon_cisco_training/
@Techmeme@techhub.socialSensor Tower: ChatGPT had 73M DAUs in India as of last week, up 607% YoY and more than double the US, boosted by its free plans, far above Gemini's 17M DAUs (Munsif Vengattil/Reuters)
https://www.reuters.com/world/india/with-free…
 @brichapman@mastodon.social
@brichapman@mastodon.socialDrawing from a training with the Climate Psychology Alliance, I've been reflecting on the role of changemakers in our world.
Before, I saw activists as Sisyphus, straining to push the world uphill.
But what if we saw them as keeping the world steady?
https://www.brichapman.com/p/what-is-…
 @azonenberg@ioc.exchange
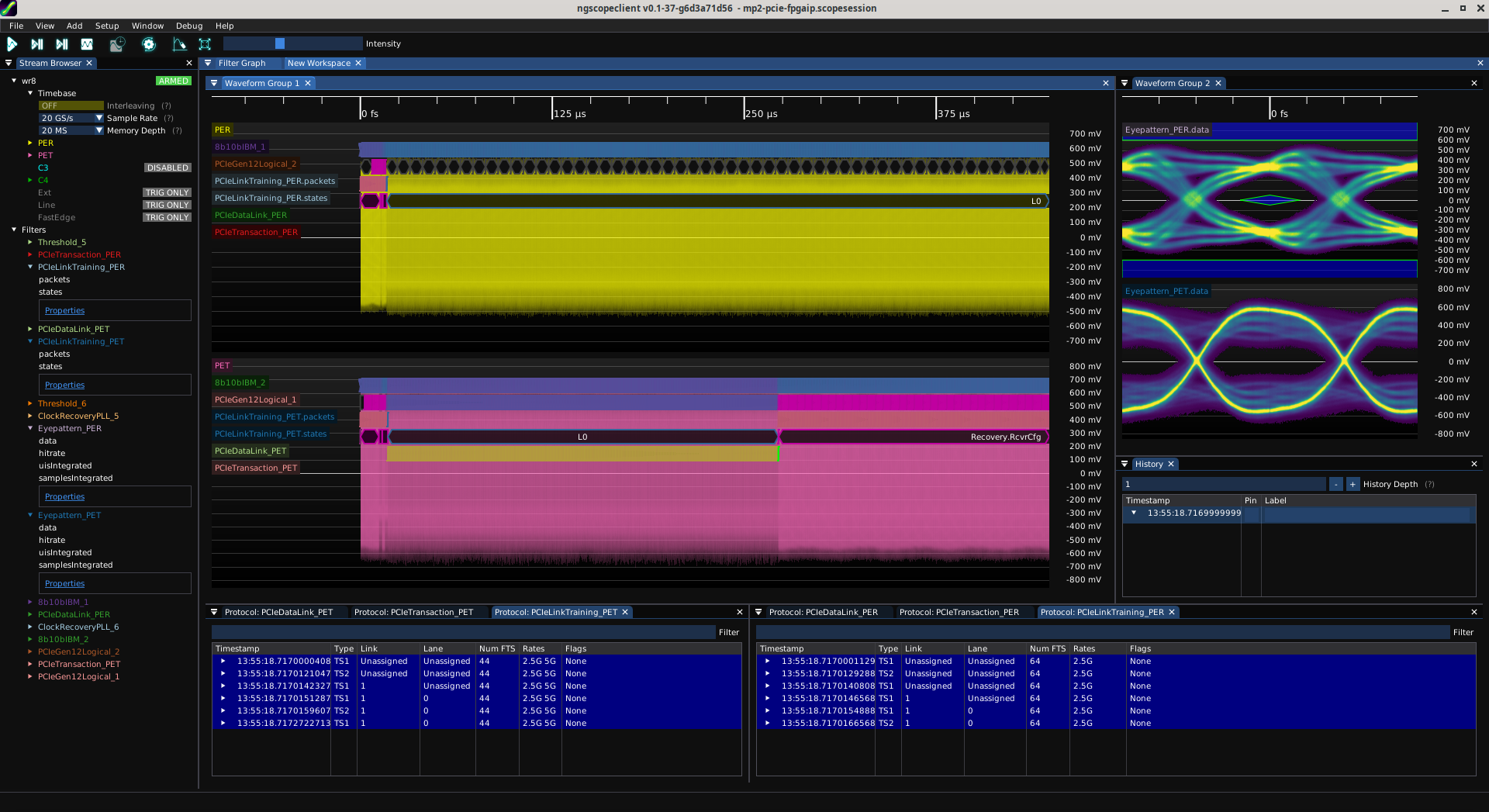
@azonenberg@ioc.exchangeTook a few minutes over lunch to iron out the last of the bugs in the happy path of PCIe link training.
There's no timeouts or fallback if there's problems but if the other side is happy, it will train up to L0 and then sit there ignoring all incoming traffic.
After a while, the link partner gets mad that it hasn't seen a single DLLP from me and drops the link. I don't implement recovery yet so things go downhill from there.
 @arXiv_csDC_bot@mastoxiv.page
@arXiv_csDC_bot@mastoxiv.pageDCP: Addressing Input Dynamism In Long-Context Training via Dynamic Context Parallelism
Chenyu Jiang, Zhenkun Cai, Ye Tian, Zhen Jia, Yida Wang, Chuan Wu
https://arxiv.org/abs/2510.10620
 @cowboys@darktundra.xyz
@cowboys@darktundra.xyzHead Coach Jim Harbaugh on Preparing for Dak Prescott and the Cowboys Offense https://www.chargers.com/video/jim-harbaugh-press-conference-wednesday-week-16-2025
 @kexpmusicbot@mastodonapp.uk
@kexpmusicbot@mastodonapp.uk🇺🇦 #NowPlaying on KEXP's #SonicReducer
Camouflage:
🎵 Powers of Horror / Future Soldier Training Program
#Camouflage
https://cam0uflage.bandcamp.com/track/powers-of-horror-future-soldier-training-program
@cdarwin@c.imStanding atop a seven-ton military truck with his wife, Vance watched the largest Marine exercise in a decade on Oct. 18,
featuring F-18 and F-35 flyovers,
parachute landings,
Navy Seals swimming ashore,
offshore destroyers and amphibious ships,
simulated village explosions,
and MH-60 helicopters dropping additional Seals over the water.
-- all to distract attention from the massive "No Kings" protests happening all across the country.
 @phpmacher@sueden.social
@phpmacher@sueden.social @cheryanne@aus.social
@cheryanne@aus.socialThe Holistic Horse Podcast
A podcast for those who want to learn all areas of horse care, training and management from a holistic perspective...
Great Australian Pods Podcast Directory: https://www.greataustralianpods.com/the-holistic-horse/
 @arXiv_csHC_bot@mastoxiv.page
@arXiv_csHC_bot@mastoxiv.pageBrainForm: a Serious Game for BCI Training and Data Collection
Michele Romani, Devis Zanoni, Elisabetta Farella, Luca Turchet
https://arxiv.org/abs/2510.10169 https://
 @pixelcode@social.tchncs.de
@pixelcode@social.tchncs.deRE: https://mastodon.social/@nixCraft/115554484108496189
I still cannot comprehend how anyone could honestly consider a statistical model created from training data to be “intelligent”. Don't you remember the times when people knowingly smiled at anyo…
@seeingwithsound@mas.toLong-term visual-to-tactile stimulation induces functional reorganization of thalamic pathways to achieve visual perception https://www.sciencedirect.com/science/article/pii/S105381192500655X using haptic sensory substitution;

 @thomasfuchs@hachyderm.io
@thomasfuchs@hachyderm.ioUser interface pretending to be human: fraud.
Statistical sentence generation described as “intelligence”: fraud.
Telling people, often children, to commit dangerous or criminal acts: all sorts of crimes.
Scientific papers generated, non-existing cases quoted at court, homework faked, artists ripped-off: fraud and copyright infringement.
Training based on unlicensed works: copyright infringement.
Data centers with tax incentives and special energy pricing: theft.
Promises to investors of AGI: fraud.
Government bailouts with taxpayer money: theft and fraud.
—
Media and politicians: This is innovation, don’t get left behind.
 @johl@mastodon.xyz
@johl@mastodon.xyzThe very excellent “what happened last week” newsletter by @… focuses on “the A in AI stands for African” this week, namely on how Chinese AI companies are turning Kenya with its chronic unemployment of 67 percent into a hot spot of cheap AI labor.
More and more Kenyan students and recent graduates are hired to label thousands of videos a day through opaq…
 @deepthoughts10@infosec.exchange
@deepthoughts10@infosec.exchangeRE: #Microsoft Identity training!
 @arXiv_statML_bot@mastoxiv.page
@arXiv_statML_bot@mastoxiv.pageGradient-Guided Furthest Point Sampling for Robust Training Set Selection
Morris Trestman, Stefan Gugler, Felix A. Faber, O. A. von Lilienfeld
https://arxiv.org/abs/2510.08906 h…
 @arXiv_csSI_bot@mastoxiv.page
@arXiv_csSI_bot@mastoxiv.pageWeb Crawler Restrictions, AI Training Datasets \& Political Biases
Paul Bouchaud (ISC-PIF, m\'edialab), Pedro Ramaciotti (ISC-PIF, m\'edialab)
https://arxiv.org/abs/2510.09031
@arXiv_csCV_bot@mastoxiv.pageAdvancing End-to-End Pixel Space Generative Modeling via Self-supervised Pre-training
Jiachen Lei, Keli Liu, Julius Berner, Haiming Yu, Hongkai Zheng, Jiahong Wu, Xiangxiang Chu
https://arxiv.org/abs/2510.12586
 @arXiv_csSD_bot@mastoxiv.page
@arXiv_csSD_bot@mastoxiv.pageVM-UNSSOR: Unsupervised Neural Speech Separation Enhanced by Higher-SNR Virtual Microphone Arrays
Shulin He, Zhong-Qiu Wang
https://arxiv.org/abs/2510.08914 https://
 @migueldeicaza@mastodon.social
@migueldeicaza@mastodon.socialSharing this trick is my contribution to improve the quality of life of every corporate and government employee:
https://mastodon.cloud/@lrz/115350971038126826
@cdarwin@c.imA major southern California highway was being shut down while the U.S. Marine Corps stages a demonstration set to involve live fire on Oct. 18,
pitting the state's governor against the federal government yet again.
Interstate 5 will be shut down from Harbor Drive to Basilone Road,
a stretch of the main artery over 15 miles,
from 11 a.m. to 3 p.m. local time, the California Highway Patrol announced the morning of Oct. 18.
The news comes after days of back-an…
@arXiv_csCL_bot@mastoxiv.pageGetting Your Indices in a Row: Full-Text Search for LLM Training Data for Real World
Ines Altemir Marinas, Anastasiia Kucherenko, Alexander Sternfeld, Andrei Kucharavy
https://arxiv.org/abs/2510.09471 …
 @schachjugend@schach.social
@schachjugend@schach.socialParallel zum Schulschachkongress bieten wir den Schülern und Schülerinnen aller Schulen des Rhein-Kreises-Neuss ein einmaliges kostenfreies Training an. Weitere Informationen und die Anmeldung unter: https://www.deutsche-schachjugend.de/termine/2025/traini…

 @gwire@mastodon.social
@gwire@mastodon.socialA headline emphasising the government's support for Britain's High Streets.
> Thousands to get free digital training so everyone has the chance to shop around for cheaper deals online
https://www.gov.uk/government…
@arXiv_csLG_bot@mastoxiv.pageTraining Dynamics Impact Post-Training Quantization Robustness
Albert Catalan-Tatjer, Niccol\`o Ajroldi, Jonas Geiping
https://arxiv.org/abs/2510.06213 https://
 @arXiv_csIR_bot@mastoxiv.page
@arXiv_csIR_bot@mastoxiv.pageNext Interest Flow: A Generative Pre-training Paradigm for Recommender Systems by Modeling All-domain Movelines
Chen Gao, Zixin Zhao, Lv Shao, Tong Liu
https://arxiv.org/abs/2510.11317
 @arXiv_csRO_bot@mastoxiv.page
@arXiv_csRO_bot@mastoxiv.pageTraining Models to Detect Successive Robot Errors from Human Reactions
Shannon Liu, Maria Teresa Parreira, Wendy Ju
https://arxiv.org/abs/2510.09080 https://
 @adulau@infosec.exchange
@adulau@infosec.exchangeUnderstanding the Efficacy of Phishing Training in Practice
"Combined with the bulk of empirical evidence from other studies involving
real-world, controlled experiments, our results suggests that organizations should not expect large anti-phishing benefits from either annual security awareness training or embedded phishing as commonly deployed today."
In addition, the overall cost on third-party organisations doing incident response should not exclude the impact of false-posi…
@seeingwithsound@mas.toVideoTIM5 tactile display from ABTIM https://abtim.com/vt5-vt3 "new Optacon", around € 9000, or € 11000 including training https://www.
 @arXiv_csAR_bot@mastoxiv.page
@arXiv_csAR_bot@mastoxiv.pageCocoon: A System Architecture for Differentially Private Training with Correlated Noises
Donghwan Kim, Xin Gu, Jinho Baek, Timothy Lo, Younghoon Min, Kwangsik Shin, Jongryool Kim, Jongse Park, Kiwan Maeng
https://arxiv.org/abs/2510.07304
@Mediagazer@mstdn.socialInterviews with copywriters on generative AI's impact: their work used for training, layoffs, wages and rates in free fall, freelancers losing clients, and more (Brian Merchant/Blood in the Machine)
https://www.bloodinthemachine.com/p/i-was-forced-to-use-ai-until-the…
@arXiv_csAI_bot@mastoxiv.pagePromptFlow: Training Prompts Like Neural Networks
Jingyi Wang, Hongyuan Zhu, Ye Niu, Yunhui Deng
https://arxiv.org/abs/2510.12246 https://arxiv.org/pdf/251…
@heiseonline@social.heise.deUniversal Music lässt Musik zum Training von KI verwenden
Universal Music öffnet die Tür für das Training Künstlicher Intelligenz mit Werken seiner Künstler. Eine Klage gegen den Dienst Udio wird beigelegt.
https…
 @arXiv_mathDS_bot@mastoxiv.page
@arXiv_mathDS_bot@mastoxiv.pageArchitecture Induces Structural Invariant Manifolds of Neural Network Training Dynamics
Jiajie Zhao, Tao Luo, Yaoyu Zhang
https://arxiv.org/abs/2510.09564 https://
@arXiv_csCV_bot@mastoxiv.pageACE-G: Improving Generalization of Scene Coordinate Regression Through Query Pre-Training
Leonard Bruns, Axel Barroso-Laguna, Tommaso Cavallari, \'Aron Monszpart, Sowmya Munukutla, Victor Adrian Prisacariu, Eric Brachmann
https://arxiv.org/abs/2510.11605
@arXiv_csLG_bot@mastoxiv.pageAutomated Evolutionary Optimization for Resource-Efficient Neural Network Training
Ilia Revin, Leon Strelkov, Vadim A. Potemkin, Ivan Kireev, Andrey Savchenko
https://arxiv.org/abs/2510.09566
@arXiv_csCL_bot@mastoxiv.pageMaP: A Unified Framework for Reliable Evaluation of Pre-training Dynamics
Jiapeng Wang, Changxin Tian, Kunlong Chen, Ziqi Liu, Jiaxin Mao, Wayne Xin Zhao, Zhiqiang Zhang, Jun Zhou
https://arxiv.org/abs/2510.09295
@Techmeme@techhub.socialAndrej Karpathy unveils nanochat, a full-stack training and inference implementation of an LLM in a single, dependency-minimal codebase (Andrej Karpathy/@karpathy)
https://x.com/karpathy/status/1977755427569111362
@arXiv_csAI_bot@mastoxiv.pageEmboMatrix: A Scalable Training-Ground for Embodied Decision-Making
Zixing Lei, Sheng Yin, Yichen Xiong, Yuanzhuo Ding, Wenhao Huang, Yuxi Wei, Qingyao Xu, Yiming Li, Weixin Li, Yunhong Wang, Siheng Chen
https://arxiv.org/abs/2510.12072
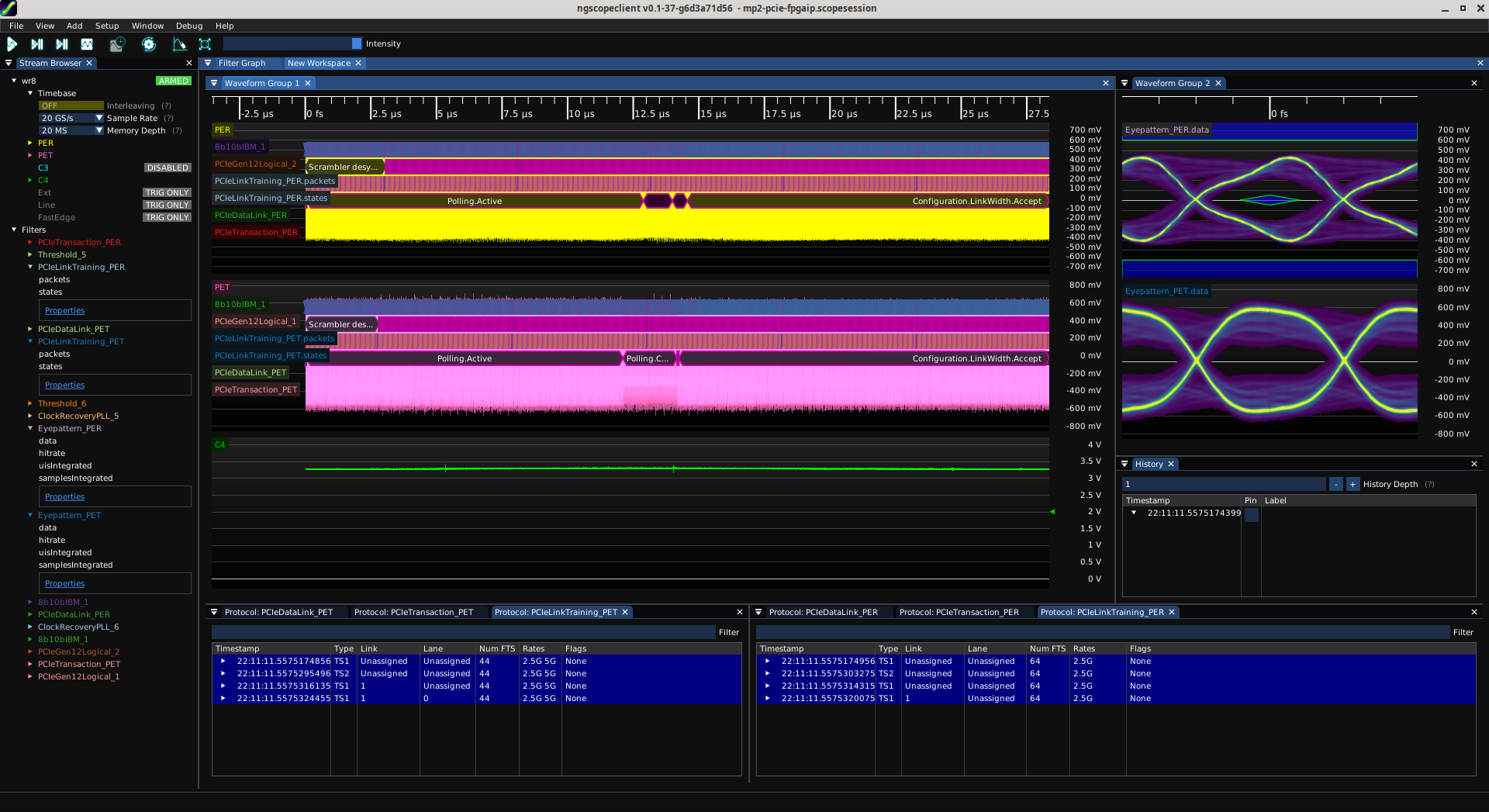
@azonenberg@ioc.exchangePCIe any% speedrun update: LTSSM is in full swing, I've made it all the way to Configuration.LinkWidth.Accept (and improved the ngscopeclient decode for link training in the process).
 @radioeinsmusicbot@mastodonapp.uk
@radioeinsmusicbot@mastodonapp.uk🇺🇦 Auf radioeins läuft...
Doja Cat:
🎵 Aaahh Men!
#NowPlaying #DojaCat
https://thataquafinagirl.bandcamp.com/track/aaahh-men-x-training-season-doja-cat-x-dua-lipa-mashup
https://open.spotify.com/track/2qGvxAKXbajPFRb9ybIMOD
@cdarwin@c.imUnión del Barrio has been doing “know your rights” workshops
and training people on how to spot ICE and report to the community when they do see them.
Cardona said it is important to document ICE raids and kidnappings to help people understand what they have been seeing and the way ICE goes about these operations.
Advocates have also been organizing patrols and responding to reported ICE activity.
Cardona said there have been many instances where community members in L…
@arXiv_csDC_bot@mastoxiv.pageAn Explorative Study on Distributed Computing Techniques in Training and Inference of Large Language Models
Sheikh Azizul Hakim, Saem Hasan
https://arxiv.org/abs/2510.11211 http…
@heiseonline@social.heise.de @arXiv_csCV_bot@mastoxiv.pageA Framework for Low-Effort Training Data Generation for Urban Semantic Segmentation
Denis Zavadski, Damjan Kal\v{s}an, Tim K\"uchler, Haebom Lee, Stefan Roth, Carsten Rother
https://arxiv.org/abs/2510.11567
@arXiv_csCL_bot@mastoxiv.pageLogit Arithmetic Elicits Long Reasoning Capabilities Without Training
Yunxiang Zhang, Muhammad Khalifa, Lechen Zhang, Xin Liu, Ayoung Lee, Xinliang Frederick Zhang, Farima Fatahi Bayat, Lu Wang
https://arxiv.org/abs/2510.09354
@NFL@darktundra.xyzQB Kyler Murray on Cardinals' plans for new 2028 training facility: 'Hopefully I'm here to see it' https://www.nfl.com/news/qb-kyler-murray-on-cardinals-plans-for-new-2028-training-facility-hopefully-i-m-here-t…
@Techmeme@techhub.socialInterviews with copywriters on generative AI's impact: job losses to AI, work used for training, falling wages and rates, freelancers losing clients, and more (Brian Merchant/Blood in the Machine)
https://www.bloodinthemachine.com/p/i-was-forced-to-use-ai-until-the
@arXiv_csAI_bot@mastoxiv.pageThinkPilot: Steering Reasoning Models via Automated Think-prefixes Optimization
Sunzhu Li, Zhiyu Lin, Shuling Yang, Jiale Zhao, Wei Chen
https://arxiv.org/abs/2510.12063 https:/…
@arXiv_csCV_bot@mastoxiv.pageDiT360: High-Fidelity Panoramic Image Generation via Hybrid Training
Haoran Feng, Dizhe Zhang, Xiangtai Li, Bo Du, Lu Qi
https://arxiv.org/abs/2510.11712 https://
@benb@osintua.euNew military training center for Ukrainian, NATO troops opens in Poland: https://benborges.xyz/2025/10/03/new-military-training-center-for.html
@arXiv_csCL_bot@mastoxiv.pageEarly Detection and Reduction of Memorisation for Domain Adaptation and Instruction Tuning
Dean L. Slack, Noura Al Moubayed
https://arxiv.org/abs/2510.11372 https://
@arXiv_csLG_bot@mastoxiv.pageRepresentation-Based Exploration for Language Models: From Test-Time to Post-Training
Jens Tuyls, Dylan J. Foster, Akshay Krishnamurthy, Jordan T. Ash
https://arxiv.org/abs/2510.11686
@azonenberg@ioc.exchangePCIe-from-scratch update: GTP is configured and sending a hardcoded 8b10b junk pattern to the SoC.
On the RX side, I'm able to correctly identify and parse TS1/TS2 training sets.
Next step will be to refactor a bit, then implement the actual LTSSM and start sending training sets.
@heiseonline@social.heise.deEU will DSGVO schleifen – für KI und Cookie-Banner
Der von der EU-Kommission geplante "digitale Omnibus" würde bestehende Datenschutzrechte aufweichen. Es geht etwa um Cookies und das Training von KI-Systemen.
h…
@Techmeme@techhub.socialThe Allen Institute of AI launches Bolmo 7B and Bolmo 1B, claiming they are "the first fully open byte-level language models", built on its Olmo 3 models (Emilia David/VentureBeat)
https://venturebeat.com/ai/bolmos-architecture-unlock…
@arXiv_csCV_bot@mastoxiv.pageLayerSync: Self-aligning Intermediate Layers
Yasaman Haghighi, Bastien van Delft, Mariam Hassan, Alexandre Alahi
https://arxiv.org/abs/2510.12581 https://a…
@arXiv_csLG_bot@mastoxiv.pageInteractive Training: Feedback-Driven Neural Network Optimization
Wentao Zhang, Yang Young Lu, Yuntian Deng
https://arxiv.org/abs/2510.02297 https://arxiv.…
@heiseonline@social.heise.de @arXiv_csCL_bot@mastoxiv.pageMid-Training of Large Language Models: A Survey
Kaixiang Mo, Yuxin Shi, Weiwei Weng, Zhiqiang Zhou, Shuman Liu, Haibo Zhang, Anxiang Zeng
https://arxiv.org/abs/2510.06826 https:…
@arXiv_csCV_bot@mastoxiv.pageData or Language Supervision: What Makes CLIP Better than DINO?
Yiming Liu, Yuhui Zhang, Dhruba Ghosh, Ludwig Schmidt, Serena Yeung-Levy
https://arxiv.org/abs/2510.11835 https:/…
@Techmeme@techhub.socialAnthropic now requires users to accept new privacy terms by October 8, including choosing whether new chats and coding sessions can be used to train AI models (Reece Rogers/Wired)
https://www.wired.com/story/anthropic-using-claude-chats-for-training-how-…
@arXiv_csAI_bot@mastoxiv.pageTraining-Free Time Series Classification via In-Context Reasoning with LLM Agents
Songyuan Sui, Zihang Xu, Yu-Neng Chuang, Kwei-Herng Lai, Xia Hu
https://arxiv.org/abs/2510.05950
@arXiv_csLG_bot@mastoxiv.pageFrom Condensation to Rank Collapse: A Two-Stage Analysis of Transformer Training Dynamics
Zheng-An Chen, Tao Luo
https://arxiv.org/abs/2510.06954 https://a…
@cdarwin@c.imA political candidate in the New York City suburbs went for a night swim in the Atlantic Ocean this past spring -- and never returned.
Petros Krommidas’s phone, keys and clothes were found on the sands at Long Beach on Long Island.
The 29-year-old former Ivy League rower, who was training for a triathlon, had parked his car just off the picturesque wooden boardwalk.
As the months passed, local Democrats attempted to field a replacement to run for the seat in the Nassau Coun…
@arXiv_csAI_bot@mastoxiv.pageMetaVLA: Unified Meta Co-training For Efficient Embodied Adaption
Chen Li, Zhantao Yang, Han Zhang, Fangyi Chen, Chenchen Zhu, Anudeepsekhar Bolimera, Marios Savvides
https://arxiv.org/abs/2510.05580
@heiseonline@social.heise.de @Techmeme@techhub.socialPeloton unveils its Cross Training Series, including a $1,695 Bike and $6,695 Tread Plus, and AI-based Peloton IQ to track workouts on new and old machines (Victoria Song/The Verge)
https://www.theverge.com/tech/789282/peloton-cross-training-…
@arXiv_csLG_bot@mastoxiv.pageCross-Receiver Generalization for RF Fingerprint Identification via Feature Disentanglement and Adversarial Training
Yuhao Pan, Xiucheng Wang, Nan Cheng, Wenchao Xu
https://arxiv.org/abs/2510.09405
@cdarwin@c.imThe only remaining criminal case against Donald Trump has been revived
after the head of Georgia’s prosecutor’s council appointed himself to replace Fani Willis,
the Fulton county district attorney, who was removed from the election interference case in September.
Pete Skandalakis,
a Republican and the executive director of the prosecuting attorneys’ council of Georgia,
the state body that provides legal training and is often charged to mitigate prosecutorial co…
@arXiv_csCV_bot@mastoxiv.pageNaViL: Rethinking Scaling Properties of Native Multimodal Large Language Models under Data Constraints
Changyao Tian, Hao Li, Gen Luo, Xizhou Zhu, Weijie Su, Hanming Deng, Jinguo Zhu, Jie Shao, Ziran Zhu, Yunpeng Liu, Lewei Lu, Wenhai Wang, Hongsheng Li, Jifeng Dai
https://arxiv.org/abs/2510.08565 …
@arXiv_csAI_bot@mastoxiv.pageInformation-Theoretic Policy Pre-Training with Empowerment
Moritz Schneider, Robert Krug, Narunas Vaskevicius, Luigi Palmieri, Michael Volpp, Joschka Boedecker
https://arxiv.org/abs/2510.05996
@arXiv_csCL_bot@mastoxiv.pageBeyond Turn Limits: Training Deep Search Agents with Dynamic Context Window
Qiaoyu Tang, Hao Xiang, Le Yu, Bowen Yu, Yaojie Lu, Xianpei Han, Le Sun, WenJuan Zhang, Pengbo Wang, Shixuan Liu, Zhenru Zhang, Jianhong Tu, Hongyu Lin, Junyang Lin
https://arxiv.org/abs/2510.08276
@Techmeme@techhub.socialHugging Face details how it used its new tool, Skills, to fine tune LLMs using Claude, including for writing scripts, submitting jobs to cloud GPUs, and more (Hugging Face)
https://huggingface.co/blog/hf-skills-training
@arXiv_csLG_bot@mastoxiv.pageOut-of-Distribution Detection from Small Training Sets using Bayesian Neural Network Classifiers
Kevin Raina, Tanya Schmah
https://arxiv.org/abs/2510.06025 https://
@arXiv_csAI_bot@mastoxiv.pageLocalist LLMs -- A Mathematical Framework for Dynamic Locality Control
Joachim Diederich
https://arxiv.org/abs/2510.09338 https://arxiv.org/pdf/2510.09338
@Techmeme@techhub.socialChip giants' efforts to turn Phoenix into a US hub may hinge on training local workers; an estimated 115K local chip jobs are set to be created in four years (Peter S. Goodman/New York Times)
https://www.nytimes.com/2025/12/04/business/tsmc-arizona-workers-…
@arXiv_csLG_bot@mastoxiv.pageDraft, Verify, and Improve: Toward Training-Aware Speculative Decoding
Shrenik Bhansali, Larry Heck
https://arxiv.org/abs/2510.05421 https://arxiv.org/pdf/…
@Techmeme@techhub.socialMicro1, which helps AI labs find experts for data annotation, says it has crossed $100M in annualized revenue and fielded investment offers at a $2.5B valuation (Anna Tong/Forbes)
http://www.forbes.com/sites/annatong/2025
@Techmeme@techhub.socialAnker paid users of its Eufy security cameras $2 per video of staged or real package and car thefts to train its AI systems from December 2024 to February 2025 (Lorenzo Franceschi-Bicchierai/TechCrunch)
https://techcrunch.com/2025/10/04/anke
@arXiv_csLG_bot@mastoxiv.pageFisher Information, Training and Bias in Fourier Regression Models
Lorenzo Pastori, Veronika Eyring, Mierk Schwabe
https://arxiv.org/abs/2510.06945 https://
@arXiv_csLG_bot@mastoxiv.pageUnified Molecule Pre-training with Flexible 2D and 3D Modalities: Single and Paired Modality Integration
Tengwei Song, Min Wu, Yuan Fang
https://arxiv.org/abs/2510.07035 https:/…






























































