@CubitOom@social.linux.pizza
@CubitOom@social.linux.pizza2026-06-18 16:20:14
Veteran Adam Marshall testifies on his abduction by fascists while helping protestors as a street medic at Delaney Hall concentration camp (Newark, NJ • 06/17/26)
On Wednesday, June 17th, Ranking Member Bennie G. Thompson (D-MS) and Committee on Homeland Security Democrats will hold a Democratic forum in Newark, New Jersey to conduct oversight of the Delaney Hall ICE detention center operated by GEO Group. At the forum, entitled “The Human Cost of Immigration Enforcement and Detention:…

 @detondev@social.linux.pizza
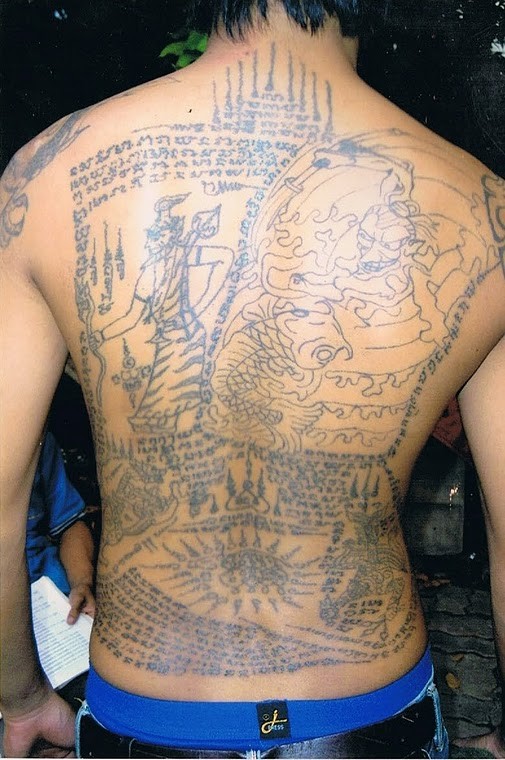
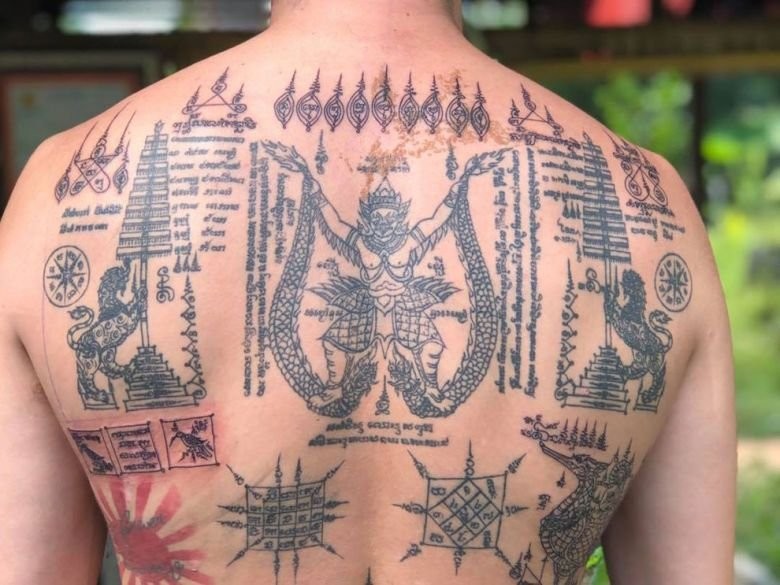
@detondev@social.linux.pizza2026-04-27 22:30:08
The rules of abstention (khatha kamma; ข้อห้ามศิษย์ยันต์) for sak yant tattoos vary depending on the master. Each lineage may prescribe slightly different codes of conduct, which are considered essential to preserve the power of the yant. The following are the rules traditionally taught at Wat Bang Phra:
• Do not eat star fruit, pumpkin, or other gourd-like vegetables.
• Do not become romantically involved with someone who is already married.
• Never insult or slander anyone’…

 @jon@henshaw.social
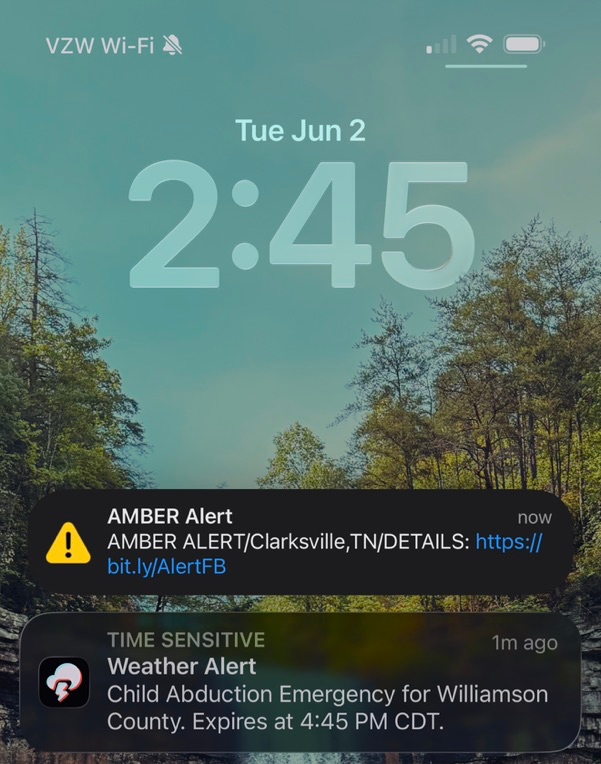
@jon@henshaw.social2026-06-02 20:55:10
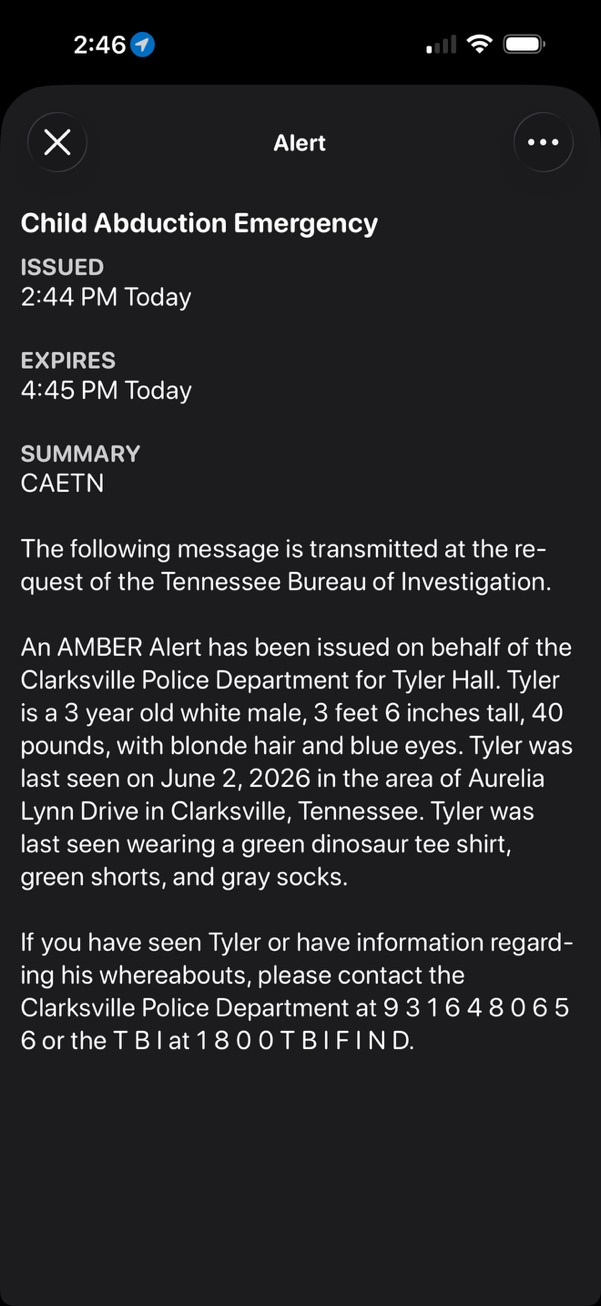
Got an Amber Alert today, and my weather app, @…, did a better job than the state of Tennessee. In fact, TN failed, as they do at most things lately.
The alert from TN had a Bitly link (already looks suspicious) that goes to a Facebook page that requires you to login. :picard:
 @almad@fosstodon.org
@almad@fosstodon.org2026-07-04 19:07:50
Czech Republic had a mini blackout a year ago. Investigation has completed now, problem was a coal power plant and a bad conductor and coupling.
But the main narrative were renewables, of course…
https://www.voxpot.cz/clanky/cesky-blackou

 @arXiv_quantph_bot@mastoxiv.page
@arXiv_quantph_bot@mastoxiv.page2026-06-11 08:49:01
Crosslisted article(s) found for quant-ph. https://arxiv.org/list/quant-ph/new
[2/2]:
- Non-Hermitian Delocalization Realizes Random Dirac Criticality in One Dimension
Bo Li, Shen Zhang, Ren Zhang
https://arxiv.org/abs/2606.12089 https://mastoxiv.page/@arXiv_condmatdisnn_bot/116730365150426280
- Fabricating fiber cavity mirror substrates compatible with high coupling efficiency
Michael Caouette-Mansour, Thomas J. Clark, Valeria Mosso Tsedilkina, Jack C. Sankey
https://arxiv.org/abs/2606.12168 https://mastoxiv.page/@arXiv_physicsoptics_bot/116730475059016236
- Experimental straintronics in nanotube quantum dots
L. Huang, I. G. Rebollo, A. R. Champagne
https://arxiv.org/abs/2606.12180 https://mastoxiv.page/@arXiv_condmatmeshall_bot/116730486068512684
- A post-selected quantum model of cosmic acceleration
Dimitris Lionas, Charis Anastopoulos, Konstantinos Gourgouliatos
https://arxiv.org/abs/2606.12297 https://mastoxiv.page/@arXiv_grqc_bot/116730477222156474
- Entanglement generation between field modes mediated by a fluctuating conducting wall
Luca Giovanni Cammarata, Tommaso Fazio, Roberto Passante, Lucia Rizzuto
https://arxiv.org/abs/2606.12338 https://mastoxiv.page/@arXiv_hepth_bot/116730465816996578
- Gate-tunable spin-valley transport via carrier velocity in monolayer WSe$_2$
Otman Bouladiane, Hocine Bahlouli, Clarence Cortes, David Laroze, Ahmed Jellal
https://arxiv.org/abs/2606.12353 https://mastoxiv.page/@arXiv_condmatmeshall_bot/116730497275361456
- Collective neutrino oscillations: Many-body non-forward effects and non-classicality
Julien Froustey, Ermal Rrapaj, Yuhao Liu, Gushu Li, Costin Iancu, Vincenzo Cirigliano
https://arxiv.org/abs/2606.12404 https://mastoxiv.page/@arXiv_hepph_bot/116730481154065938
- A Pfaffian quantum Hall state of ultracold bosons
Kwan, Segura, Li, Blatz, Zhi, Bakkali-Hassani, Bohrdt, Greiter, Grusdt, Greiner
https://arxiv.org/abs/2606.12409 https://mastoxiv.page/@arXiv_condmatquantgas_bot/116730427900388710
toXiv_bot_toot
 @Gillian_Jacobi@social.linux.pizza
@Gillian_Jacobi@social.linux.pizza2026-04-25 19:45:06
Slovenia og deltagelsen af #Israel i Eurovision Song Contest 2026: Slovenien vil vise palæstinensiske film hele dagen som protest mod Israels deltagelse. Fem lande har annonceret boykot af arrangementet på
https://skandinavia.infodefense.pr…